 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract-RAG: Reason and Interact with the Corpus, Beyond Black-Box Retrieval
Oct 31, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced LLMs by incorporating external information. However, prevailing agentic RAG approaches are constrained by a critical limitation: they treat the retrieval process as a black-box querying operation. This confines agents' actions to query issuing, hindering its ability to tackle complex information-seeking tasks. To address this, we introduce Interact-RAG, a new paradigm that elevates the LLM agent from a passive query issuer into an active manipulator of the retrieval process. We dismantle the black-box with a Corpus Interaction Engine, equipping the agent with a set of action primitives for fine-grained control over information retrieval. To further empower the agent on the entire RAG pipeline, we first develop a reasoning-enhanced workflow, which enables both zero-shot execution and the synthesis of interaction trajectories. We then leverage this synthetic data to train a fully autonomous end-to-end agent via Supervised Fine-Tuning (SFT), followed by refinement with Reinforcement Learning (RL). Extensive experiments across six benchmarks demonstrate that Interact-RAG significantly outperforms other advanced methods, validating the efficacy of our reasoning-interaction strategy.
ScaleDoc: Scaling LLM-based Predicates over Large Document Collections
Sep 16, 2025Predicates are foundational components in data analysis systems. However, modern workloads increasingly involve unstructured documents, which demands semantic understanding, beyond traditional value-based predicates. Given enormous documents and ad-hoc queries, while Large Language Models (LLMs) demonstrate powerful zero-shot capabilities, their high inference cost leads to unacceptable overhead. Therefore, we introduce \textsc{ScaleDoc}, a novel system that addresses this by decoupling predicate execution into an offline representation phase and an optimized online filtering phase. In the offline phase, \textsc{ScaleDoc} leverages a LLM to generate semantic representations for each document. Online, for each query, it trains a lightweight proxy model on these representations to filter the majority of documents, forwarding only the ambiguous cases to the LLM for final decision. Furthermore, \textsc{ScaleDoc} proposes two core innovations to achieve significant efficiency: (1) a contrastive-learning-based framework that trains the proxy model to generate reliable predicating decision scores; (2) an adaptive cascade mechanism that determines the effective filtering policy while meeting specific accuracy targets. Our evaluations across three datasets demonstrate that \textsc{ScaleDoc} achieves over a 2$\times$ end-to-end speedup and reduces expensive LLM invocations by up to 85\%, making large-scale semantic analysis practical and efficient.
OkraLong: A Flexible Retrieval-Augmented Framework for Long-Text Query Processing
Mar 05, 2025



Large Language Models (LLMs) encounter challenges in efficiently processing long-text queries, as seen in applications like enterprise document analysis and financial report comprehension. While conventional solutions employ long-context processing or Retrieval-Augmented Generation (RAG), they suffer from prohibitive input expenses or incomplete information. Recent advancements adopt context compression and dynamic retrieval loops, but still sacrifice critical details or incur iterative costs. To address these limitations, we propose OkraLong, a novel framework that flexibly optimizes the entire processing workflow. Unlike prior static or coarse-grained adaptive strategies, OkraLong adopts fine-grained orchestration through three synergistic components: analyzer, organizer and executor. The analyzer characterizes the task states, which guide the organizer in dynamically scheduling the workflow. The executor carries out the execution and generates the final answer. Experimental results demonstrate that OkraLong not only enhances answer accuracy but also achieves cost-effectiveness across a variety of datasets.
UDA: A Benchmark Suite for Retrieval Augmented Generation in Real-world Document Analysis
Jun 21, 2024

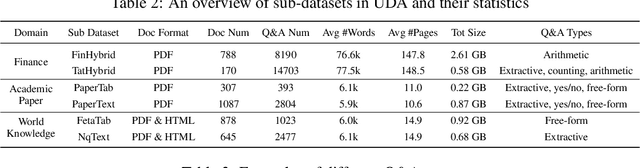
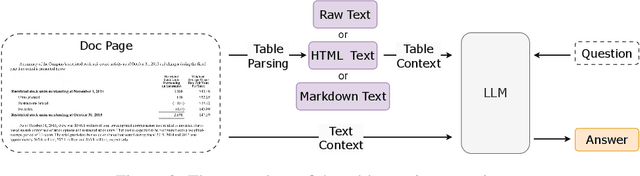
The use of Retrieval-Augmented Generation (RAG) has improved Large Language Models (LLMs) in collaborating with external data, yet significant challenges exist in real-world scenarios. In areas such as academic literature and finance question answering, data are often found in raw text and tables in HTML or PDF formats, which can be lengthy and highly unstructured. In this paper, we introduce a benchmark suite, namely Unstructured Document Analysis (UDA), that involves 2,965 real-world documents and 29,590 expert-annotated Q&A pairs. We revisit popular LLM- and RAG-based solutions for document analysis and evaluate the design choices and answer qualities across multiple document domains and diverse query types. Our evaluation yields interesting findings and highlights the importance of data parsing and retrieval. We hope our benchmark can shed light and better serve real-world document analysis applications. The benchmark suite and code can be found at https://github.com/qinchuanhui/UDA-Benchmark.
ReaLHF: Optimized RLHF Training for Large Language Models through Parameter Reallocation
Jun 20, 2024



Reinforcement Learning from Human Feedback (RLHF) stands as a pivotal technique in empowering large language model (LLM) applications. Since RLHF involves diverse computational workloads and intricate dependencies among multiple LLMs, directly adopting parallelization techniques from supervised training can result in sub-optimal performance. To overcome this limitation, we propose a novel approach named parameter ReaLlocation, which dynamically redistributes LLM parameters in the cluster and adapts parallelization strategies during training. Building upon this idea, we introduce ReaLHF, a pioneering system capable of automatically discovering and running efficient execution plans for RLHF training given the desired algorithmic and hardware configurations. ReaLHF formulates the execution plan for RLHF as an augmented dataflow graph. Based on this formulation, ReaLHF employs a tailored search algorithm with a lightweight cost estimator to discover an efficient execution plan. Subsequently, the runtime engine deploys the selected plan by effectively parallelizing computations and redistributing parameters. We evaluate ReaLHF on the LLaMA-2 models with up to $4\times70$ billion parameters and 128 GPUs. The experiment results showcase ReaLHF's substantial speedups of $2.0-10.6\times$ compared to baselines. Furthermore, the execution plans generated by ReaLHF exhibit an average of $26\%$ performance improvement over heuristic approaches based on Megatron-LM. The source code of ReaLHF is publicly available at https://github.com/openpsi-project/ReaLHF .
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores
Jul 05, 2023



The ever-growing complexity of reinforcement learning (RL) tasks demands a distributed RL system to efficiently generate and process a massive amount of data to train intelligent agents. However, existing open-source libraries suffer from various limitations, which impede their practical use in challenging scenarios where large-scale training is necessary. While industrial systems from OpenAI and DeepMind have achieved successful large-scale RL training, their system architecture and implementation details remain undisclosed to the community. In this paper, we present a novel abstraction on the dataflows of RL training, which unifies practical RL training across diverse applications into a general framework and enables fine-grained optimizations. Following this abstraction, we develop a scalable, efficient, and extensible distributed RL system called ReaLly Scalable RL (SRL). The system architecture of SRL separates major RL computation components and allows massively parallelized training. Moreover, SRL offers user-friendly and extensible interfaces for customized algorithms. Our evaluation shows that SRL outperforms existing academic libraries in both a single machine and a medium-sized cluster. In a large-scale cluster, the novel architecture of SRL leads to up to 3.7x speedup compared to the design choices adopted by the existing libraries. We also conduct a direct benchmark comparison to OpenAI's industrial system, Rapid, in the challenging hide-and-seek environment. SRL reproduces the same solution as reported by OpenAI with up to 5x speedup in wall-clock time. Furthermore, we also examine the performance of SRL in a much harder variant of the hide-and-seek environment and achieve substantial learning speedup by scaling SRL to over 15k CPU cores and 32 A100 GPUs. Notably, SRL is the first in the academic community to perform RL experiments at such a large scale.
LeCo: Lightweight Compression via Learning Serial Correlations
Jun 27, 2023


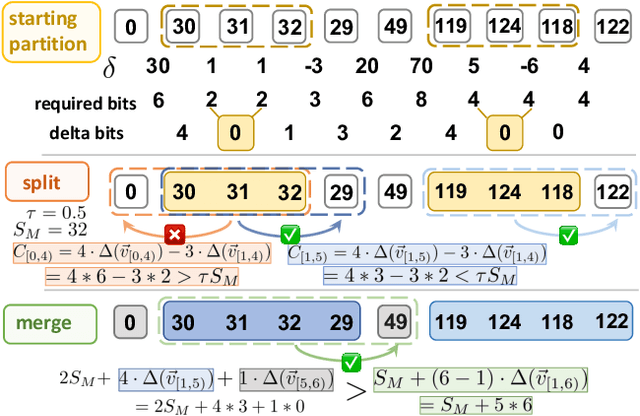
Lightweight data compression is a key technique that allows column stores to exhibit superior performance for analytical queries. Despite a comprehensive study on dictionary-based encodings to approach Shannon's entropy, few prior works have systematically exploited the serial correlation in a column for compression. In this paper, we propose LeCo (i.e., Learned Compression), a framework that uses machine learning to remove the serial redundancy in a value sequence automatically to achieve an outstanding compression ratio and decompression performance simultaneously. LeCo presents a general approach to this end, making existing (ad-hoc) algorithms such as Frame-of-Reference (FOR), Delta Encoding, and Run-Length Encoding (RLE) special cases under our framework. Our microbenchmark with three synthetic and six real-world data sets shows that a prototype of LeCo achieves a Pareto improvement on both compression ratio and random access speed over the existing solutions. When integrating LeCo into widely-used applications, we observe up to 3.9x speed up in filter-scanning a Parquet file and a 16% increase in Rocksdb's throughput.
Proteus: A Self-Designing Range Filter
Jun 30, 2022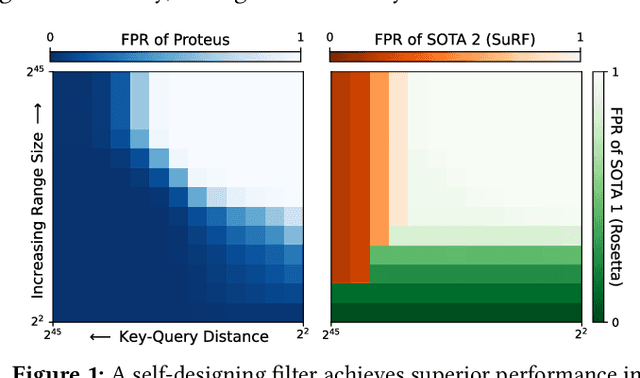

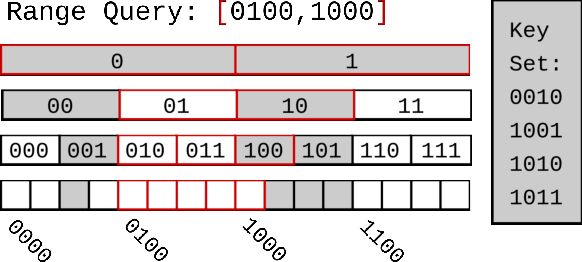
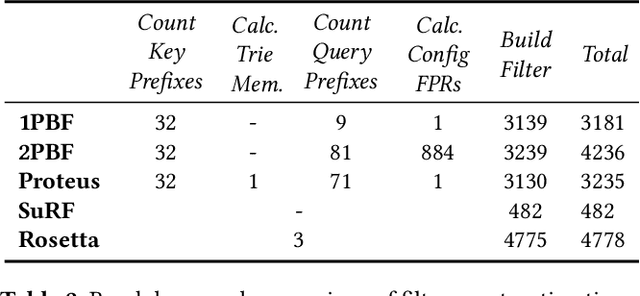
We introduce Proteus, a novel self-designing approximate range filter, which configures itself based on sampled data in order to optimize its false positive rate (FPR) for a given space requirement. Proteus unifies the probabilistic and deterministic design spaces of state-of-the-art range filters to achieve robust performance across a larger variety of use cases. At the core of Proteus lies our Contextual Prefix FPR (CPFPR) model - a formal framework for the FPR of prefix-based filters across their design spaces. We empirically demonstrate the accuracy of our model and Proteus' ability to optimize over both synthetic workloads and real-world datasets. We further evaluate Proteus in RocksDB and show that it is able to improve end-to-end performance by as much as 5.3x over more brittle state-of-the-art methods such as SuRF and Rosetta. Our experiments also indicate that the cost of modeling is not significant compared to the end-to-end performance gains and that Proteus is robust to workload shifts.
* 14 pages, 9 figures, originally published in the Proceedings of the 2022 International Conference on Management of Data (SIGMOD'22), ISBN: 9781450392495