 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizing With Randomized Hadamard Transforms: Efficient Heuristic Now Proven
May 07, 2026Uniform random rotations (URRs) are a common preprocessing step in modern quantization approaches used for gradient compression, inference acceleration, KV-cache compression, model weight quantization, and approximate nearest-neighbor search in vector databases. In practice, URRs are often replaced by randomized Hadamard transforms (RHTs), which preserve orthogonality while admitting fast implementations. The remaining issue is the performance for worst-case inputs. With a URR, each coordinate is individually distributed as a shifted beta distribution, which converges to a Gaussian distribution in high dimensions. Generally, one RHT is not suitable in the worst case, as individual coordinates can be far from these distributions. We show that after composing two RHTs on any $d$-sized input vector, the marginal distribution of every fixed coordinate of the normalized rotated vector is within $O(d^{-1/2})$ of a standard Gaussian both in Kolmogorov distance and in $1$-Wasserstein distance. We then plug these bounds into the analyses of modern compression schemes, namely DRIVE and QUIC-FL, and show that two RHTs achieve performance that asymptotically matches URRs. However, we show that two RHTs may not be sufficient for Vector Quantization (VQ), which often requires weak correlation across fixed-size blocks of coordinates (as opposed to only marginal distribution convergence for single coordinates). We prove that a composition of three RHTs leads to decaying coordinate covariance. This ensures that any fixed, bounded, multi-dimensional VQ codebook optimized for URRs has the same expected error when using three RHTs, up to an additive term that vanishes with the dimension. Finally, because practical inputs are rarely adversarial, we propose a linear-time ${O}(d)$ check on the input's moments to dynamically adapt the number of RHTs used at runtime to improve performance.
A Note on TurboQuant and the Earlier DRIVE/EDEN Line of Work
Apr 20, 2026This note clarifies the relationship between the recent TurboQuant work and the earlier DRIVE (NeurIPS 2021) and EDEN (ICML 2022) schemes. DRIVE is a 1-bit quantizer that EDEN extended to any $b>0$ bits per coordinate; we refer to them collectively as EDEN. First, TurboQuant$_{\text{mse}}$ is a special case of EDEN obtained by fixing EDEN's scalar scale parameter to $S=1$. EDEN supports both biased and unbiased quantization, each optimized by a different $S$ (chosen via methods described in the EDEN works). The fixed choice $S=1$ used by TurboQuant is generally suboptimal, although the optimal $S$ for biased EDEN converges to $1$ as the dimension grows; accordingly TurboQuant$_{\text{mse}}$ approaches EDEN's behavior for large $d$. Second, TurboQuant$_{\text{prod}}$ combines a biased $(b-1)$-bit EDEN step with an unbiased 1-bit QJL quantization of the residual. It is suboptimal in three ways: (1) its $(b-1)$-bit step uses the suboptimal $S=1$; (2) its 1-bit unbiased residual quantization has worse MSE than (unbiased) 1-bit EDEN; (3) chaining a biased $(b-1)$-bit step with a 1-bit unbiased residual step is inferior to unbiasedly quantizing the input directly with $b$-bit EDEN. Third, some of the analysis in the TurboQuant work mirrors that of the EDEN works: both exploit the connection between random rotations and the shifted Beta distribution, use the Lloyd-Max algorithm, and note that Randomized Hadamard Transforms can replace uniform random rotations. Experiments support these claims: biased EDEN (with optimized $S$) is more accurate than TurboQuant$_{\text{mse}}$, and unbiased EDEN is markedly more accurate than TurboQuant$_{\text{prod}}$, often by more than a bit (e.g., 2-bit EDEN beats 3-bit TurboQuant$_{\text{prod}}$). We also repeat all accuracy experiments from the TurboQuant paper, showing that EDEN outperforms it in every setup we have tried.
Orla: A Library for Serving LLM-Based Multi-Agent Systems
Mar 13, 2026We introduce Orla, a library for constructing and running LLM-based agentic systems. Modern agentic applications consist of workflows that combine multiple LLM inference steps, tool calls, and heterogeneous infrastructure. Today, developers typically build these systems by manually composing orchestration code with LLM serving engines and tool execution logic. Orla provides a general abstraction that separates request execution from workflow-level policy. It acts as a serving layer above existing LLM inference engines: developers define workflows composed of stages, while Orla manages how those stages are mapped, executed, and coordinated across models and backends. It provides agent-level control through three mechanisms: a stage mapper, which assigns each stage to an appropriate model and backend; a workflow orchestrator, which schedules stages and manages their resources and context; and a memory manager, which manages inference state such as the KV cache across workflow boundaries. We demonstrate Orla with a customer support workflow that exercises many of its capabilities. We evaluate Orla on two datasets, showing that stage mapping improves latency and cost compared to a single-model vLLM baseline, while workflow-level cache management reduces time-to-first-token.
DynamiQ: Accelerating Gradient Synchronization using Compressed Multi-hop All-reduce
Feb 09, 2026Multi-hop all-reduce is the de facto backbone of large model training. As the training scale increases, the network often becomes a bottleneck, motivating reducing the volume of transmitted data. Accordingly, recent systems demonstrated significant acceleration of the training process using gradient quantization. However, these systems are not optimized for multi-hop aggregation, where entries are partially summed multiple times along their aggregation topology. This paper presents DynamiQ, a quantization framework that bridges the gap between quantization best practices and multi-hop aggregation. DynamiQ introduces novel techniques to better represent partial sums, co-designed with a decompress-accumulate-recompress fused kernel to facilitate fast execution. We extended PyTorch DDP to support DynamiQ over NCCL P2P, and across different LLMs, tasks, and scales, we demonstrate consistent improvement of up to 34.2% over the best among state-of-the-art methods such as Omni-Reduce, THC, and emerging standards such as MXFP4, MXFP6, and MXFP8. Further, DynamiQ is the only evaluated method that consistently reaches near-baseline accuracy (e.g., 99.9% of the BF16 baseline) and does so while significantly accelerating the training.
Queueing, Predictions, and LLMs: Challenges and Open Problems
Mar 10, 2025Queueing systems present many opportunities for applying machine-learning predictions, such as estimated service times, to improve system performance. This integration raises numerous open questions about how predictions can be effectively leveraged to improve scheduling decisions. Recent studies explore queues with predicted service times, typically aiming to minimize job time in the system. We review these works, highlight the effectiveness of predictions, and present open questions on queue performance. We then move to consider an important practical example of using predictions in scheduling, namely Large Language Model (LLM) systems, which presents novel scheduling challenges and highlights the potential for predictions to improve performance. In particular, we consider LLMs performing inference. Inference requests (jobs) in LLM systems are inherently complex; they have variable inference times, dynamic memory footprints that are constrained by key-value (KV) store memory limitations, and multiple possible preemption approaches that affect performance differently. We provide background on the important aspects of scheduling in LLM systems, and introduce new models and open problems that arise from them. We argue that there are significant opportunities for applying insights and analysis from queueing theory to scheduling in LLM systems.
HACK: Homomorphic Acceleration via Compression of the Key-Value Cache for Disaggregated LLM Inference
Feb 05, 2025

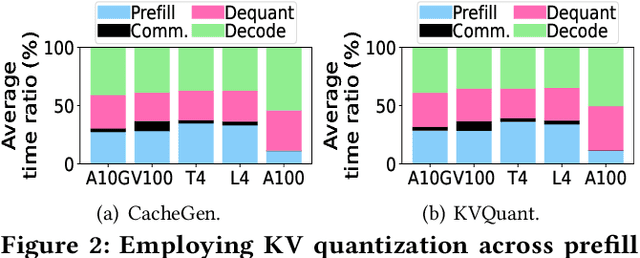

Disaggregated Large Language Model (LLM) inference has gained popularity as it separates the computation-intensive prefill stage from the memory-intensive decode stage, avoiding the prefill-decode interference and improving resource utilization. However, transmitting Key-Value (KV) data between the two stages can be a bottleneck, especially for long prompts. Additionally, the computation time overhead for prefill and decode is key for optimizing Job Completion Time (JCT), and KV data size can become prohibitive for long prompts and sequences. Existing KV quantization methods can alleviate the transmission bottleneck and reduce memory requirements, but they introduce significant dequantization overhead, exacerbating the computation time. We propose Homomorphic Acceleration via Compression of the KV cache (HACK) for disaggregated LLM inference. HACK eliminates the heavy KV dequantization step, and directly performs computations on quantized KV data to approximate and reduce the cost of the expensive matrix-multiplication step. Extensive trace-driven experiments show that HACK reduces JCT by up to 70.9% compared to disaggregated LLM inference baseline and by up to 52.3% compared to state-of-the-art KV quantization methods.
Fast Inference for Augmented Large Language Models
Oct 25, 2024



Augmented Large Language Models (LLMs) enhance the capabilities of standalone LLMs by integrating external data sources through API calls. In interactive LLM applications, efficient scheduling is crucial for maintaining low request completion times, directly impacting user engagement. However, these augmentations introduce scheduling challenges due to the need to manage limited memory for cached information (KV caches). As a result, traditional size-based scheduling algorithms, such as Shortest Job First (SJF), become less effective at minimizing completion times. Existing work focuses only on handling requests during API calls by preserving, discarding, or swapping memory without considering how to schedule requests with API calls. In this paper, we propose LAMPS, a novel LLM inference framework for augmented LLMs. LAMPS minimizes request completion time through a unified scheduling approach that considers the total length of requests and their handling strategies during API calls. Recognizing that LLM inference is memory-bound, our approach ranks requests based on their consumption of memory over time, which depends on both the output sizes and how a request is managed during its API calls. To implement our scheduling, LAMPS predicts the strategy that minimizes memory waste of a request during its API calls, aligning with but improving upon existing approaches. We also propose starvation prevention techniques and optimizations to mitigate the overhead of our scheduling. We implement LAMPS on top of vLLM and evaluate its performance against baseline LLM inference systems, demonstrating improvements in end-to-end latency by 27%-85% and reductions in TTFT by 4%-96% compared to the existing augmented-LLM system, with even greater gains over vLLM.
Efficient Inference for Augmented Large Language Models
Oct 23, 2024Augmented Large Language Models (LLMs) enhance the capabilities of standalone LLMs by integrating external data sources through API calls. In interactive LLM applications, efficient scheduling is crucial for maintaining low request completion times, directly impacting user engagement. However, these augmentations introduce scheduling challenges due to the need to manage limited memory for cached information (KV caches). As a result, traditional size-based scheduling algorithms, such as Shortest Job First (SJF), become less effective at minimizing completion times. Existing work focuses only on handling requests during API calls by preserving, discarding, or swapping memory without considering how to schedule requests with API calls. In this paper, we propose LAMPS, a novel LLM inference framework for augmented LLMs. LAMPS minimizes request completion time through a unified scheduling approach that considers the total length of requests and their handling strategies during API calls. Recognizing that LLM inference is memory-bound, our approach ranks requests based on their consumption of memory over time, which depends on both the output sizes and how a request is managed during its API calls. To implement our scheduling, LAMPS predicts the strategy that minimizes memory waste of a request during its API calls, aligning with but improving upon existing approaches. We also propose starvation prevention techniques and optimizations to mitigate the overhead of our scheduling. We implement LAMPS on top of vLLM and evaluate its performance against baseline LLM inference systems, demonstrating improvements in end-to-end latency by 27%-85% and reductions in TTFT by 4%-96% compared to the existing augmented-LLM system, with even greater gains over vLLM.
Don't Stop Me Now: Embedding Based Scheduling for LLMs
Oct 01, 2024



Efficient scheduling is crucial for interactive Large Language Model (LLM) applications, where low request completion time directly impacts user engagement. Size-based scheduling algorithms like Shortest Remaining Process Time (SRPT) aim to reduce average request completion time by leveraging known or estimated request sizes and allowing preemption by incoming jobs with shorter service times. However, two main challenges arise when applying size-based scheduling to LLM systems. First, accurately predicting output lengths from prompts is challenging and often resource-intensive, making it impractical for many systems. As a result, the state-of-the-art LLM systems default to first-come, first-served scheduling, which can lead to head-of-line blocking and reduced system efficiency. Second, preemption introduces extra memory overhead to LLM systems as they must maintain intermediate states for unfinished (preempted) requests. In this paper, we propose TRAIL, a method to obtain output predictions from the target LLM itself. After generating each output token, we recycle the embedding of its internal structure as input for a lightweight classifier that predicts the remaining length for each running request. Using these predictions, we propose a prediction-based SRPT variant with limited preemption designed to account for memory overhead in LLM systems. This variant allows preemption early in request execution when memory consumption is low but restricts preemption as requests approach completion to optimize resource utilization. On the theoretical side, we derive a closed-form formula for this SRPT variant in an M/G/1 queue model, which demonstrates its potential value. In our system, we implement this preemption policy alongside our embedding-based prediction method.
Learning-Augmented Frequency Estimation in Sliding Windows
Sep 17, 2024



We show how to utilize machine learning approaches to improve sliding window algorithms for approximate frequency estimation problems, under the ``algorithms with predictions'' framework. In this dynamic environment, previous learning-augmented algorithms are less effective, since properties in sliding window resolution can differ significantly from the properties of the entire stream. Our focus is on the benefits of predicting and filtering out items with large next arrival times -- that is, there is a large gap until their next appearance -- from the stream, which we show improves the memory-accuracy tradeoffs significantly. We provide theorems that provide insight into how and by how much our technique can improve the sliding window algorithm, as well as experimental results using real-world data sets. Our work demonstrates that predictors can be useful in the challenging sliding window setting.