 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Augmented Frequency Estimation in Sliding Windows
Sep 17, 2024



We show how to utilize machine learning approaches to improve sliding window algorithms for approximate frequency estimation problems, under the ``algorithms with predictions'' framework. In this dynamic environment, previous learning-augmented algorithms are less effective, since properties in sliding window resolution can differ significantly from the properties of the entire stream. Our focus is on the benefits of predicting and filtering out items with large next arrival times -- that is, there is a large gap until their next appearance -- from the stream, which we show improves the memory-accuracy tradeoffs significantly. We provide theorems that provide insight into how and by how much our technique can improve the sliding window algorithm, as well as experimental results using real-world data sets. Our work demonstrates that predictors can be useful in the challenging sliding window setting.
The Case for Learned Spatial Indexes
Aug 24, 2020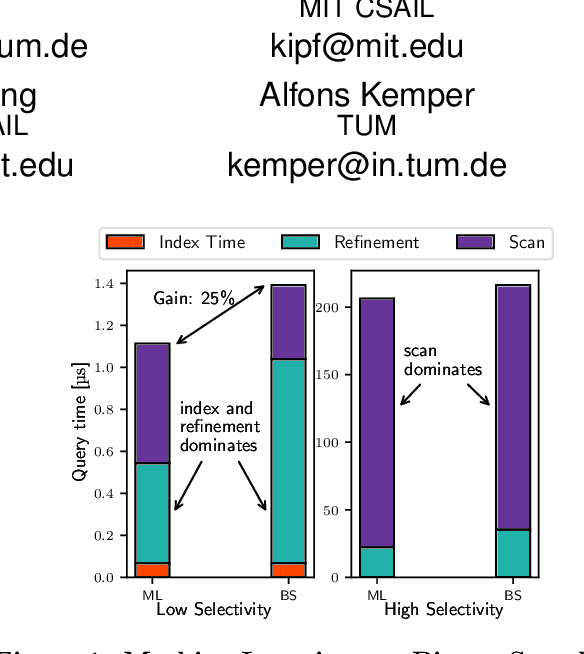



Spatial data is ubiquitous. Massive amounts of data are generated every day from billions of GPS-enabled devices such as cell phones, cars, sensors, and various consumer-based applications such as Uber, Tinder, location-tagged posts in Facebook, Twitter, Instagram, etc. This exponential growth in spatial data has led the research community to focus on building systems and applications that can process spatial data efficiently. In the meantime, recent research has introduced learned index structures. In this work, we use techniques proposed from a state-of-the art learned multi-dimensional index structure (namely, Flood) and apply them to five classical multi-dimensional indexes to be able to answer spatial range queries. By tuning each partitioning technique for optimal performance, we show that (i) machine learned search within a partition is faster by 11.79\% to 39.51\% than binary search when using filtering on one dimension, (ii) the bottleneck for tree structures is index lookup, which could potentially be improved by linearizing the indexed partitions (iii) filtering on one dimension and refining using machine learned indexes is 1.23x to 1.83x times faster than closest competitor which filters on two dimensions, and (iv) learned indexes can have a significant impact on the performance of low selectivity queries while being less effective under higher selectivities.
MonoStream: A Minimal-Hardware High Accuracy Device-free WLAN Localization System
Aug 04, 2013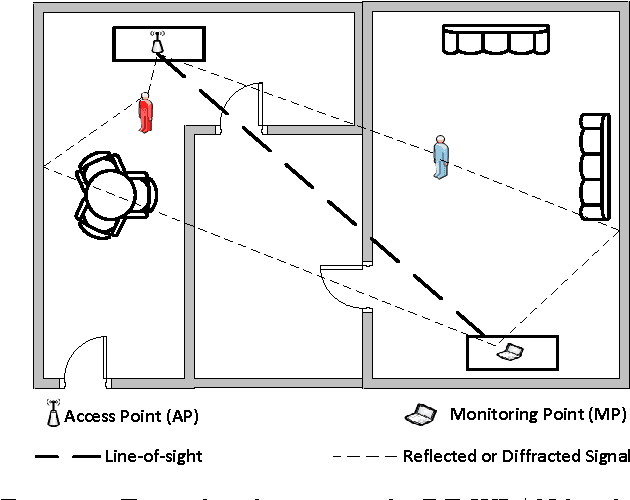
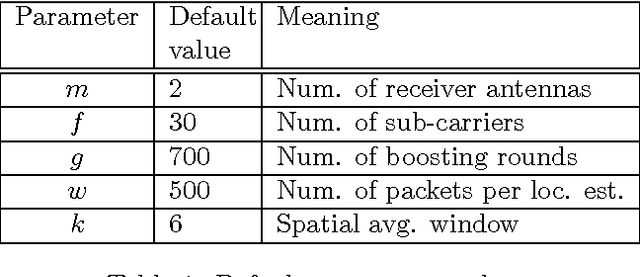
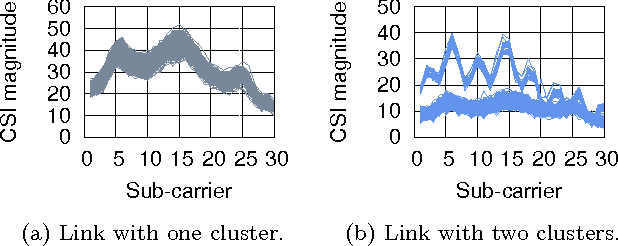
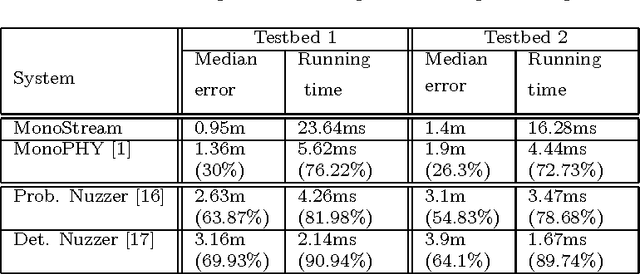
Device-free (DF) localization is an emerging technology that allows the detection and tracking of entities that do not carry any devices nor participate actively in the localization process. Typically, DF systems require a large number of transmitters and receivers to achieve acceptable accuracy, which is not available in many scenarios such as homes and small businesses. In this paper, we introduce MonoStream as an accurate single-stream DF localization system that leverages the rich Channel State Information (CSI) as well as MIMO information from the physical layer to provide accurate DF localization with only one stream. To boost its accuracy and attain low computational requirements, MonoStream models the DF localization problem as an object recognition problem and uses a novel set of CSI-context features and techniques with proven accuracy and efficiency. Experimental evaluation in two typical testbeds, with a side-by-side comparison with the state-of-the-art, shows that MonoStream can achieve an accuracy of 0.95m with at least 26% enhancement in median distance error using a single stream only. This enhancement in accuracy comes with an efficient execution of less than 23ms per location update on a typical laptop. This highlights the potential of MonoStream usage for real-time DF tracking applications.
Intelligent Hybrid Man-Machine Translation Quality Estimation
Jul 07, 2013
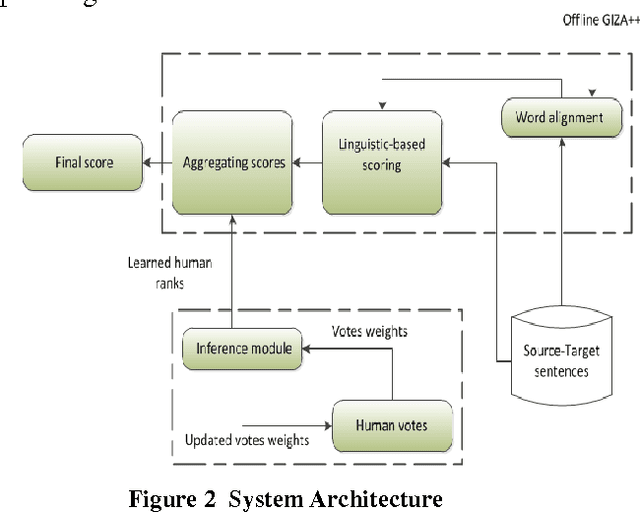
Inferring evaluation scores based on human judgments is invaluable compared to using current evaluation metrics which are not suitable for real-time applications e.g. post-editing. However, these judgments are much more expensive to collect especially from expert translators, compared to evaluation based on indicators contrasting source and translation texts. This work introduces a novel approach for quality estimation by combining learnt confidence scores from a probabilistic inference model based on human judgments, with selective linguistic features-based scores, where the proposed inference model infers the credibility of given human ranks to solve the scarcity and inconsistency issues of human judgments. Experimental results, using challenging language-pairs, demonstrate improvement in correlation with human judgments over traditional evaluation metrics.