 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Correlation-Aware Table Compression
Oct 24, 2024The growing adoption of data lakes for managing relational data necessitates efficient, open storage formats that provide high scan performance and competitive compression ratios. While existing formats achieve fast scans through lightweight encoding techniques, they have reached a plateau in terms of minimizing storage footprint. Recently, correlation-aware compression schemes have been shown to reduce file sizes further. Yet, current approaches either incur significant scan overheads or require manual specification of correlations, limiting their practicability. We present $\texttt{Virtual}$, a framework that integrates seamlessly with existing open formats to automatically leverage data correlations, achieving substantial compression gains while having minimal scan performance overhead. Experiments on data-gov datasets show that $\texttt{Virtual}$ reduces file sizes by up to 40% compared to Apache Parquet.
The Case for Learned Spatial Indexes
Aug 24, 2020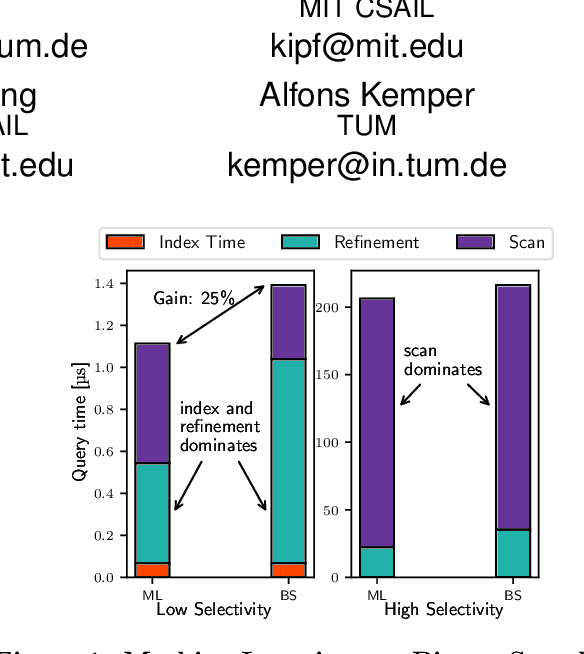



Spatial data is ubiquitous. Massive amounts of data are generated every day from billions of GPS-enabled devices such as cell phones, cars, sensors, and various consumer-based applications such as Uber, Tinder, location-tagged posts in Facebook, Twitter, Instagram, etc. This exponential growth in spatial data has led the research community to focus on building systems and applications that can process spatial data efficiently. In the meantime, recent research has introduced learned index structures. In this work, we use techniques proposed from a state-of-the art learned multi-dimensional index structure (namely, Flood) and apply them to five classical multi-dimensional indexes to be able to answer spatial range queries. By tuning each partitioning technique for optimal performance, we show that (i) machine learned search within a partition is faster by 11.79\% to 39.51\% than binary search when using filtering on one dimension, (ii) the bottleneck for tree structures is index lookup, which could potentially be improved by linearizing the indexed partitions (iii) filtering on one dimension and refining using machine learned indexes is 1.23x to 1.83x times faster than closest competitor which filters on two dimensions, and (iv) learned indexes can have a significant impact on the performance of low selectivity queries while being less effective under higher selectivities.
RadixSpline: A Single-Pass Learned Index
May 22, 2020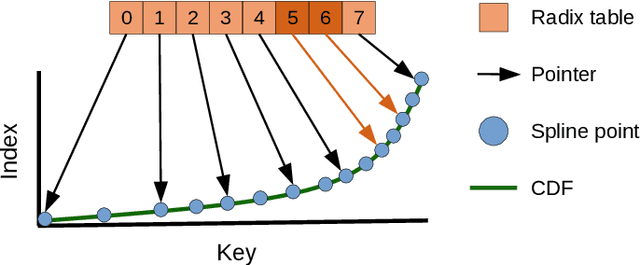
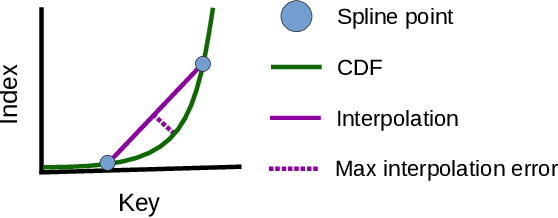
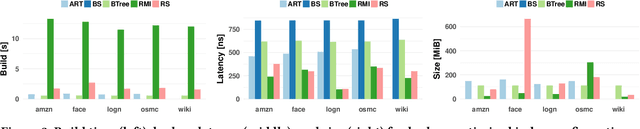

Recent research has shown that learned models can outperform state-of-the-art index structures in size and lookup performance. While this is a very promising result, existing learned structures are often cumbersome to implement and are slow to build. In fact, most approaches that we are aware of require multiple training passes over the data. We introduce RadixSpline (RS), a learned index that can be built in a single pass over the data and is competitive with state-of-the-art learned index models, like RMI, in size and lookup performance. We evaluate RS using the SOSD benchmark and show that it achieves competitive results on all datasets, despite the fact that it only has two parameters.
SOSD: A Benchmark for Learned Indexes
Nov 29, 2019

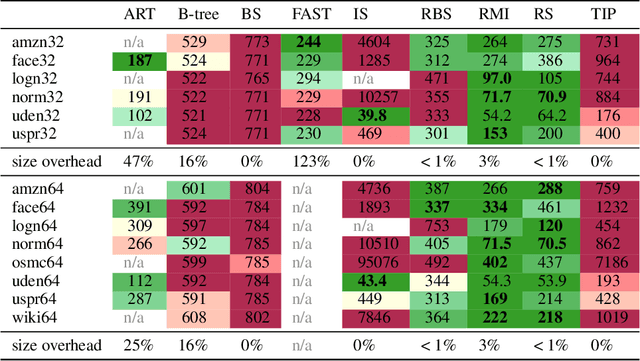
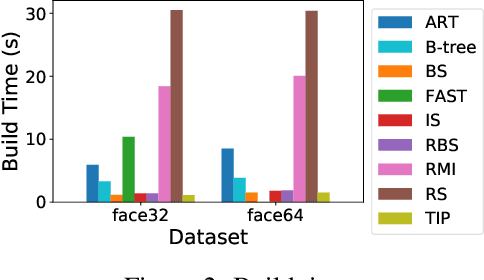
A groundswell of recent work has focused on improving data management systems with learned components. Specifically, work on learned index structures has proposed replacing traditional index structures, such as B-trees, with learned models. Given the decades of research committed to improving index structures, there is significant skepticism about whether learned indexes actually outperform state-of-the-art implementations of traditional structures on real-world data. To answer this question, we propose a new benchmarking framework that comes with a variety of real-world datasets and baseline implementations to compare against. We also show preliminary results for selected index structures, and find that learned models indeed often outperform state-of-the-art implementations, and are therefore a promising direction for future research.