 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Duck's Brain: Training and Inference of Neural Networks in Modern Database Engines
Dec 28, 2023Although database systems perform well in data access and manipulation, their relational model hinders data scientists from formulating machine learning algorithms in SQL. Nevertheless, we argue that modern database systems perform well for machine learning algorithms expressed in relational algebra. To overcome the barrier of the relational model, this paper shows how to transform data into a relational representation for training neural networks in SQL: We first describe building blocks for data transformation, model training and inference in SQL-92 and their counterparts using an extended array data type. Then, we compare the implementation for model training and inference using array data types to the one using a relational representation in SQL-92 only. The evaluation in terms of runtime and memory consumption proves the suitability of modern database systems for matrix algebra, although specialised array data types perform better than matrices in relational representation.
RadixSpline: A Single-Pass Learned Index
May 22, 2020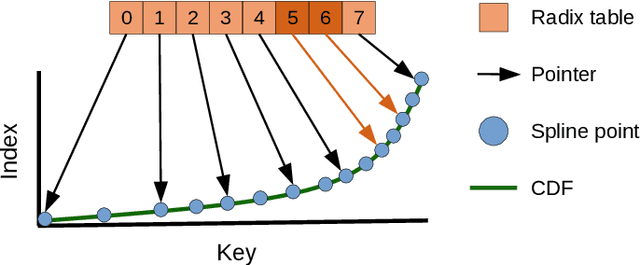
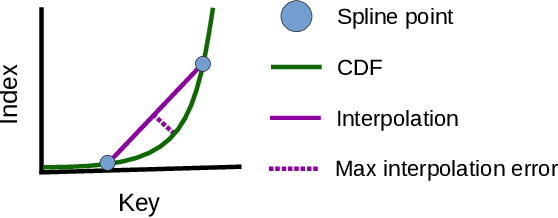

Recent research has shown that learned models can outperform state-of-the-art index structures in size and lookup performance. While this is a very promising result, existing learned structures are often cumbersome to implement and are slow to build. In fact, most approaches that we are aware of require multiple training passes over the data. We introduce RadixSpline (RS), a learned index that can be built in a single pass over the data and is competitive with state-of-the-art learned index models, like RMI, in size and lookup performance. We evaluate RS using the SOSD benchmark and show that it achieves competitive results on all datasets, despite the fact that it only has two parameters.
SOSD: A Benchmark for Learned Indexes
Nov 29, 2019

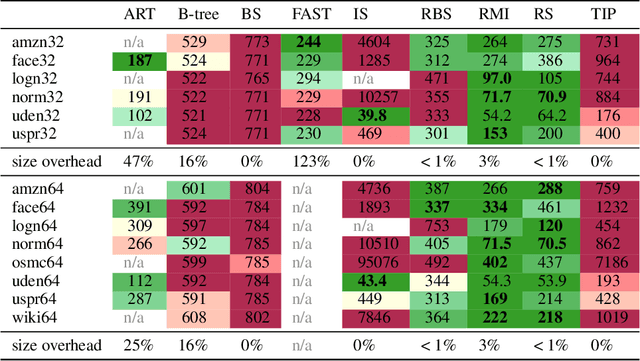
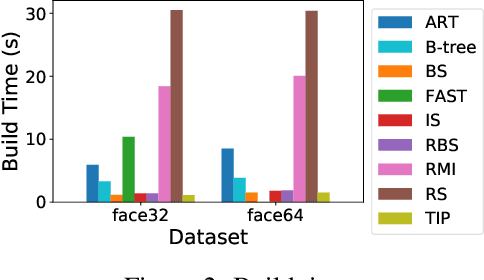
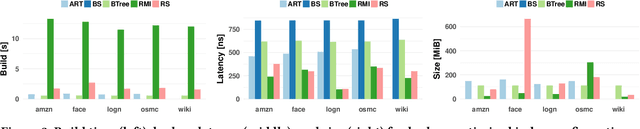
A groundswell of recent work has focused on improving data management systems with learned components. Specifically, work on learned index structures has proposed replacing traditional index structures, such as B-trees, with learned models. Given the decades of research committed to improving index structures, there is significant skepticism about whether learned indexes actually outperform state-of-the-art implementations of traditional structures on real-world data. To answer this question, we propose a new benchmarking framework that comes with a variety of real-world datasets and baseline implementations to compare against. We also show preliminary results for selected index structures, and find that learned models indeed often outperform state-of-the-art implementations, and are therefore a promising direction for future research.