 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLSkip: Data Skipping for ML Filters via Lightweight Metadata
Jun 02, 2026Database vendors recently released AI functions that can be used in filter predicates. As such functions often rely on costly, black-box ML models, they unveil new data management challenges. Concretely, traditional data skipping techniques for integer and string data fail to be applicable to the new filter type. Indeed, there is no known mechanism for pruning non-qualifying row groups, e.g., when reading files from blob storage. In this work, we initiate the study of data skipping techniques for ML filters. We make the case that Parquet's default min-max metadata is enough to enable pruning. To this end, we draw connections to two lines of research: (i) the recently proposed query language for ML models and (ii) neural network verification. Our preliminary results on ReLU architectures show that on tables from TPC-H and TPC-DS, the average pruning effectiveness for filters of selectivity below 0.1% amounts to 27.4%. Finally, inspired by research on spatial joins, we propose an enhanced metadata structure: a size-bounded 2D convex hull that verification tools can make better use of, increasing the pruning effectiveness to 38.31%, while occupying at most 45 bytes per row group and column pair. We observe an end-to-end speedup of 1.07$\times$ over PyTorch in DuckDB.
Lightweight Correlation-Aware Table Compression
Oct 24, 2024


The growing adoption of data lakes for managing relational data necessitates efficient, open storage formats that provide high scan performance and competitive compression ratios. While existing formats achieve fast scans through lightweight encoding techniques, they have reached a plateau in terms of minimizing storage footprint. Recently, correlation-aware compression schemes have been shown to reduce file sizes further. Yet, current approaches either incur significant scan overheads or require manual specification of correlations, limiting their practicability. We present $\texttt{Virtual}$, a framework that integrates seamlessly with existing open formats to automatically leverage data correlations, achieving substantial compression gains while having minimal scan performance overhead. Experiments on data-gov datasets show that $\texttt{Virtual}$ reduces file sizes by up to 40% compared to Apache Parquet.
Group Privacy Amplification and Unified Amplification by Subsampling for Rényi Differential Privacy
Mar 07, 2024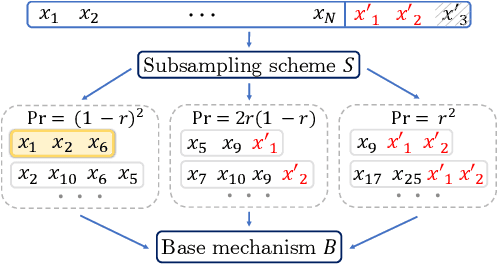

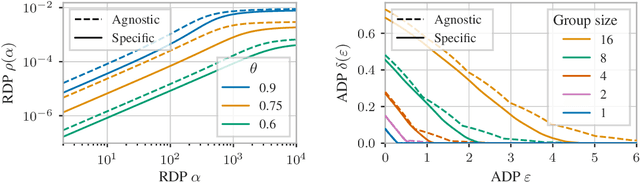
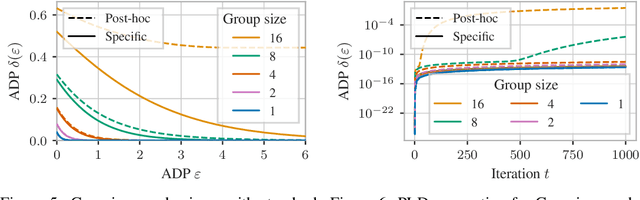
Differential privacy (DP) has various desirable properties, such as robustness to post-processing, group privacy, and amplification by subsampling, which can be derived independently of each other. Our goal is to determine whether stronger privacy guarantees can be obtained by considering multiple of these properties jointly. To this end, we focus on the combination of group privacy and amplification by subsampling. To provide guarantees that are amenable to machine learning algorithms, we conduct our analysis in the framework of R\'enyi-DP, which has more favorable composition properties than $(\epsilon,\delta)$-DP. As part of this analysis, we develop a unified framework for deriving amplification by subsampling guarantees for R\'enyi-DP, which represents the first such framework for a privacy accounting method and is of independent interest. We find that it not only lets us improve upon and generalize existing amplification results for R\'enyi-DP, but also derive provably tight group privacy amplification guarantees stronger than existing principles. These results establish the joint study of different DP properties as a promising research direction.
PLEX: Towards Practical Learned Indexing
Aug 11, 2021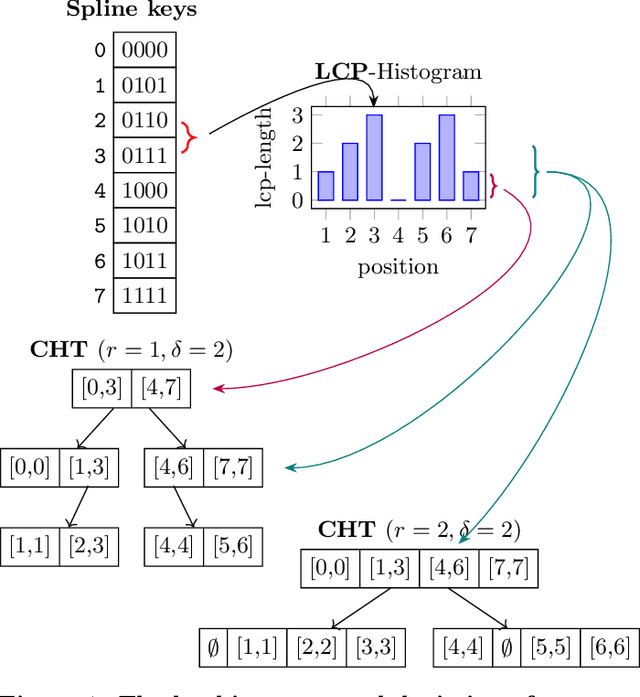
Latest research proposes to replace existing index structures with learned models. However, current learned indexes tend to have many hyperparameters, often do not provide any error guarantees, and are expensive to build. We introduce Practical Learned Index (PLEX). PLEX only has a single hyperparameter $\epsilon$ (maximum prediction error) and offers a better trade-off between build and lookup time than state-of-the-art approaches. Similar to RadixSpline, PLEX consists of a spline and a (multi-level) radix layer. It first builds a spline satisfying the given $\epsilon$ and then performs an ad-hoc analysis of the distribution of spline points to quickly tune the radix layer.
RadixSpline: A Single-Pass Learned Index
May 22, 2020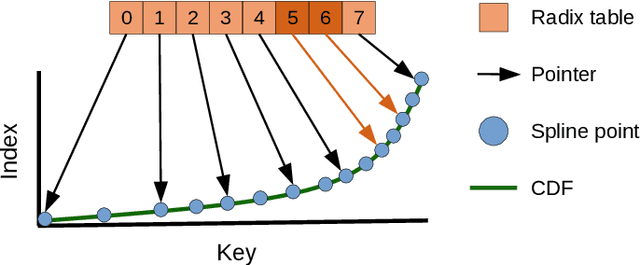
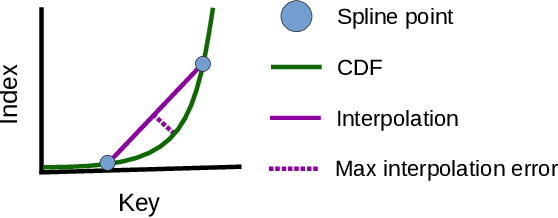
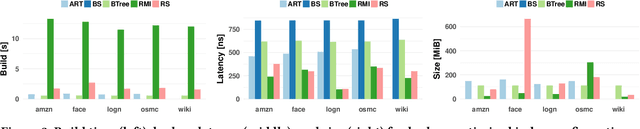

Recent research has shown that learned models can outperform state-of-the-art index structures in size and lookup performance. While this is a very promising result, existing learned structures are often cumbersome to implement and are slow to build. In fact, most approaches that we are aware of require multiple training passes over the data. We introduce RadixSpline (RS), a learned index that can be built in a single pass over the data and is competitive with state-of-the-art learned index models, like RMI, in size and lookup performance. We evaluate RS using the SOSD benchmark and show that it achieves competitive results on all datasets, despite the fact that it only has two parameters.
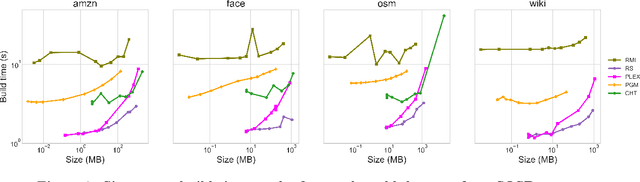
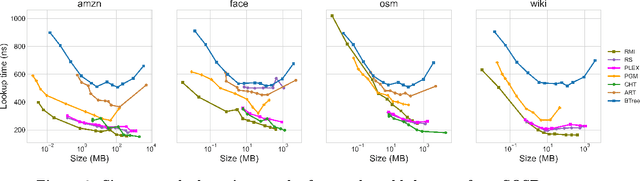
SOSD: A Benchmark for Learned Indexes
Nov 29, 2019

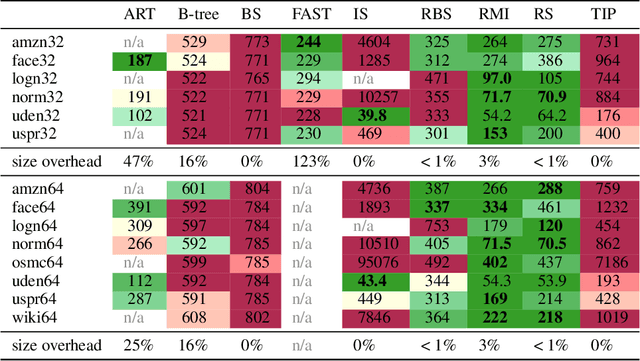
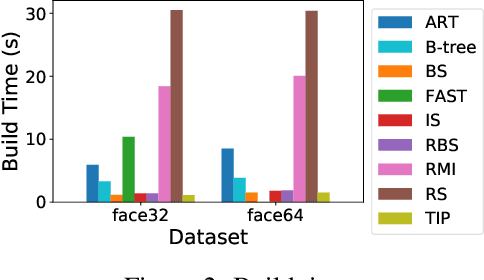
A groundswell of recent work has focused on improving data management systems with learned components. Specifically, work on learned index structures has proposed replacing traditional index structures, such as B-trees, with learned models. Given the decades of research committed to improving index structures, there is significant skepticism about whether learned indexes actually outperform state-of-the-art implementations of traditional structures on real-world data. To answer this question, we propose a new benchmarking framework that comes with a variety of real-world datasets and baseline implementations to compare against. We also show preliminary results for selected index structures, and find that learned models indeed often outperform state-of-the-art implementations, and are therefore a promising direction for future research.