 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Order: Task Sequencing as In-Context Optimization
Mar 15, 2026Task sequencing (TS) is one of the core open problems in Deep Learning, arising in a plethora of real-world domains, from robotic assembly lines to autonomous driving. Unfortunately, prior work has not convincingly demonstrated the generalization ability of meta-learned TS methods to solve new TS problems, given few initial demonstrations. In this paper, we demonstrate that deep neural networks can meta-learn over an infinite prior of synthetically generated TS problems and achieve a few-shot generalization. We meta-learn a transformer-based architecture over datasets of sequencing trajectories generated from a prior distribution that samples sequencing problems as paths in directed graphs. In a large-scale experiment, we provide ample empirical evidence that our meta-learned models discover optimal task sequences significantly quicker than non-meta-learned baselines.
POP: Prior-fitted Optimizer Policies
Feb 17, 2026Optimization refers to the task of finding extrema of an objective function. Classical gradient-based optimizers are highly sensitive to hyperparameter choices. In highly non-convex settings their performance relies on carefully tuned learning rates, momentum, and gradient accumulation. To address these limitations, we introduce POP (Prior-fitted Optimizer Policies), a meta-learned optimizer that predicts coordinate-wise step sizes conditioned on the contextual information provided in the optimization trajectory. Our model is learned on millions of synthetic optimization problems sampled from a novel prior spanning both convex and non-convex objectives. We evaluate POP on an established benchmark including 47 optimization functions of various complexity, where it consistently outperforms first-order gradient-based methods, non-convex optimization approaches (e.g., evolutionary strategies), Bayesian optimization, and a recent meta-learned competitor under matched budget constraints. Our evaluation demonstrates strong generalization capabilities without task-specific tuning.
End-to-End Compression for Tabular Foundation Models
Feb 05, 2026The long-standing dominance of gradient-boosted decision trees for tabular data has recently been challenged by in-context learning tabular foundation models. In-context learning methods fit and predict in one forward pass without parameter updates by leveraging the training data as context for predicting on query test points. While recent tabular foundation models achieve state-of-the-art performance, their transformer architecture based on the attention mechanism has quadratic complexity regarding dataset size, which in turn increases the overhead on training and inference time, and limits the capacity of the models to handle large-scale datasets. In this work, we propose TACO, an end-to-end tabular compression model that compresses the training dataset in a latent space. We test our method on the TabArena benchmark, where our proposed method is up to 94x faster in inference time, while consuming up to 97\% less memory compared to the state-of-the-art tabular transformer architecture, all while retaining performance without significant degradation. Lastly, our method not only scales better with increased dataset sizes, but it also achieves better performance compared to other baselines.
Warmstarting for Scaling Language Models
Nov 11, 2024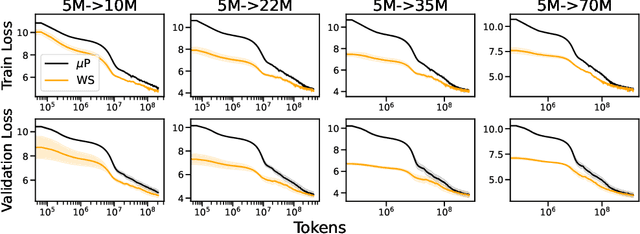
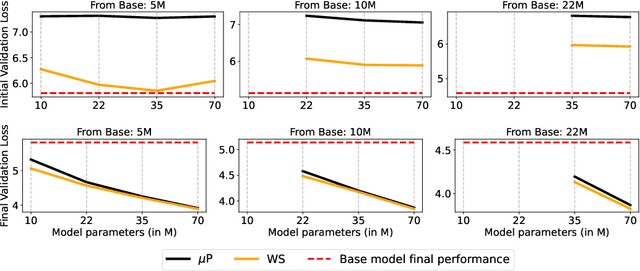
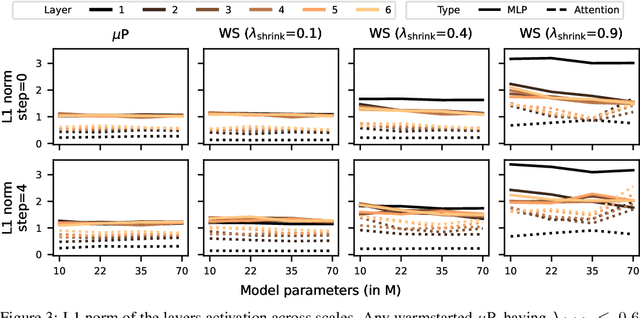
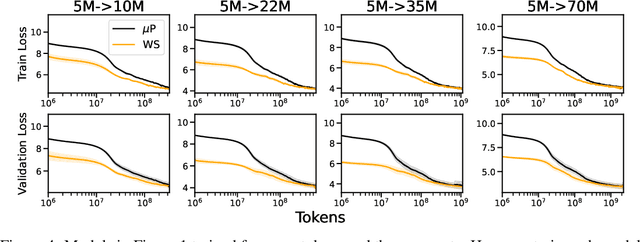
Scaling model sizes to scale performance has worked remarkably well for the current large language models paradigm. The research and empirical findings of various scaling studies led to novel scaling results and laws that guides subsequent research. High training costs for contemporary scales of data and models result in a lack of thorough understanding of how to tune and arrive at such training setups. One direction to ameliorate the cost of pretraining large models is to warmstart the large-scale training from smaller models that are cheaper to tune. In this work, we attempt to understand if the behavior of optimal hyperparameters can be retained under warmstarting for scaling. We explore simple operations that allow the application of theoretically motivated methods of zero-shot transfer of optimal hyperparameters using {\mu}Transfer. We investigate the aspects that contribute to the speedup in convergence and the preservation of stable training dynamics under warmstarting with {\mu}Transfer. We find that shrinking smaller model weights, zero-padding, and perturbing the resulting larger model with scaled initialization from {\mu}P enables effective warmstarting of $\mut{}$.
Ensembling Finetuned Language Models for Text Classification
Oct 25, 2024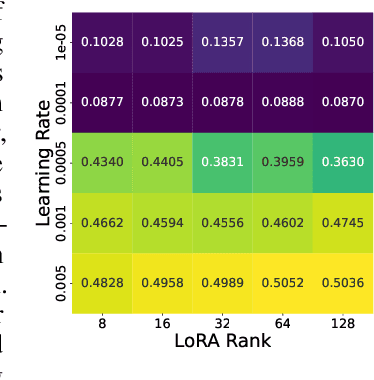

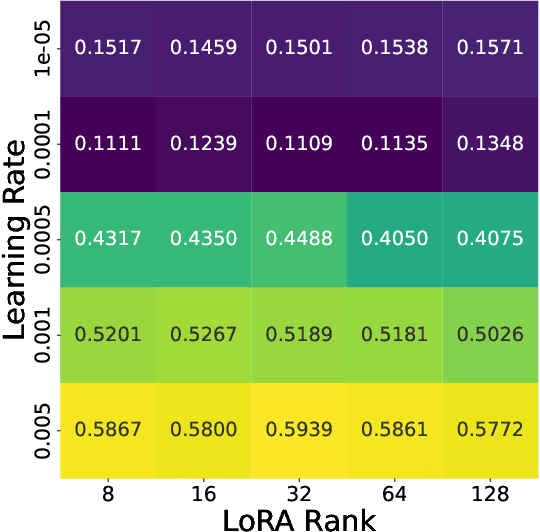
Finetuning is a common practice widespread across different communities to adapt pretrained models to particular tasks. Text classification is one of these tasks for which many pretrained models are available. On the other hand, ensembles of neural networks are typically used to boost performance and provide reliable uncertainty estimates. However, ensembling pretrained models for text classification is not a well-studied avenue. In this paper, we present a metadataset with predictions from five large finetuned models on six datasets, and report results of different ensembling strategies from these predictions. Our results shed light on how ensembling can improve the performance of finetuned text classifiers and incentivize future adoption of ensembles in such tasks.
Lightweight Correlation-Aware Table Compression
Oct 24, 2024


The growing adoption of data lakes for managing relational data necessitates efficient, open storage formats that provide high scan performance and competitive compression ratios. While existing formats achieve fast scans through lightweight encoding techniques, they have reached a plateau in terms of minimizing storage footprint. Recently, correlation-aware compression schemes have been shown to reduce file sizes further. Yet, current approaches either incur significant scan overheads or require manual specification of correlations, limiting their practicability. We present $\texttt{Virtual}$, a framework that integrates seamlessly with existing open formats to automatically leverage data correlations, achieving substantial compression gains while having minimal scan performance overhead. Experiments on data-gov datasets show that $\texttt{Virtual}$ reduces file sizes by up to 40% compared to Apache Parquet.
Dynamic Post-Hoc Neural Ensemblers
Oct 06, 2024



Ensemble methods are known for enhancing the accuracy and robustness of machine learning models by combining multiple base learners. However, standard approaches like greedy or random ensembles often fall short, as they assume a constant weight across samples for the ensemble members. This can limit expressiveness and hinder performance when aggregating the ensemble predictions. In this study, we explore employing neural networks as ensemble methods, emphasizing the significance of dynamic ensembling to leverage diverse model predictions adaptively. Motivated by the risk of learning low-diversity ensembles, we propose regularizing the model by randomly dropping base model predictions during the training. We demonstrate this approach lower bounds the diversity within the ensemble, reducing overfitting and improving generalization capabilities. Our experiments showcase that the dynamic neural ensemblers yield competitive results compared to strong baselines in computer vision, natural language processing, and tabular data.
Multi-objective Differentiable Neural Architecture Search
Feb 28, 2024Pareto front profiling in multi-objective optimization (MOO), i.e. finding a diverse set of Pareto optimal solutions, is challenging, especially with expensive objectives like neural network training. Typically, in MOO neural architecture search (NAS), we aim to balance performance and hardware metrics across devices. Prior NAS approaches simplify this task by incorporating hardware constraints into the objective function, but profiling the Pareto front necessitates a search for each constraint. In this work, we propose a novel NAS algorithm that encodes user preferences for the trade-off between performance and hardware metrics, and yields representative and diverse architectures across multiple devices in just one search run. To this end, we parameterize the joint architectural distribution across devices and multiple objectives via a hypernetwork that can be conditioned on hardware features and preference vectors, enabling zero-shot transferability to new devices. Extensive experiments with up to 19 hardware devices and 3 objectives showcase the effectiveness and scalability of our method. Finally, we show that, without additional costs, our method outperforms existing MOO NAS methods across qualitatively different search spaces and datasets, including MobileNetV3 on ImageNet-1k and a Transformer space on machine translation.
Hierarchical Transformers are Efficient Meta-Reinforcement Learners
Feb 09, 2024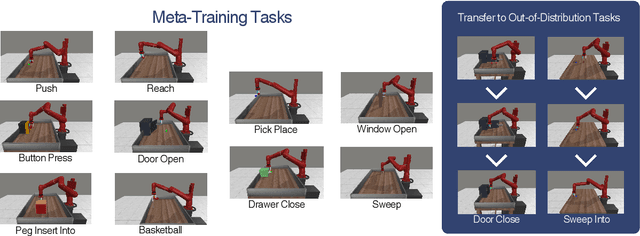

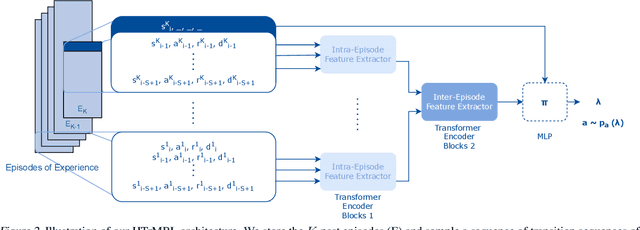
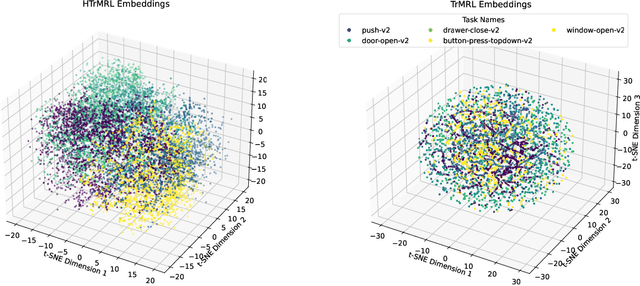
We introduce Hierarchical Transformers for Meta-Reinforcement Learning (HTrMRL), a powerful online meta-reinforcement learning approach. HTrMRL aims to address the challenge of enabling reinforcement learning agents to perform effectively in previously unseen tasks. We demonstrate how past episodes serve as a rich source of information, which our model effectively distills and applies to new contexts. Our learned algorithm is capable of outperforming the previous state-of-the-art and provides more efficient meta-training while significantly improving generalization capabilities. Experimental results, obtained across various simulated tasks of the Meta-World Benchmark, indicate a significant improvement in learning efficiency and adaptability compared to the state-of-the-art on a variety of tasks. Our approach not only enhances the agent's ability to generalize from limited data but also paves the way for more robust and versatile AI systems.
Tabular Data: Is Attention All You Need?
Feb 06, 2024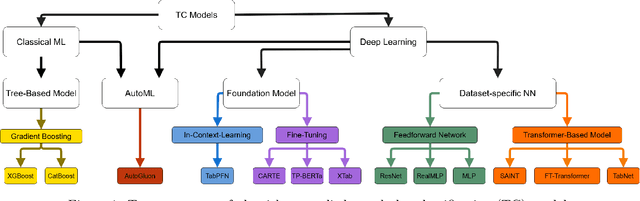
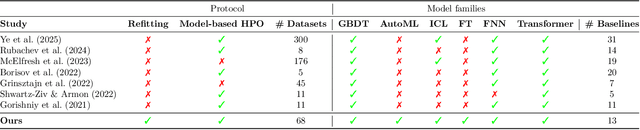
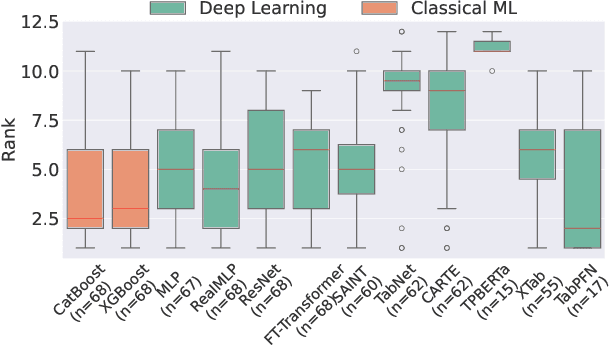
Deep Learning has revolutionized the field of AI and led to remarkable achievements in applications involving image and text data. Unfortunately, there is inconclusive evidence on the merits of neural networks for structured tabular data. In this paper, we introduce a large-scale empirical study comparing neural networks against gradient-boosted decision trees on tabular data, but also transformer-based architectures against traditional multi-layer perceptrons (MLP) with residual connections. In contrast to prior work, our empirical findings indicate that neural networks are competitive against decision trees. Furthermore, we assess that transformer-based architectures do not outperform simpler variants of traditional MLP architectures on tabular datasets. As a result, this paper helps the research and practitioner communities make informed choices on deploying neural networks on future tabular data applications.