 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Begin: Efficient Pretraining via Subnetwork Selection and Distillation
Oct 08, 2025Small Language models (SLMs) offer an efficient and accessible alternative to Large Language Models (LLMs), delivering strong performance while using far fewer resources. We introduce a simple and effective framework for pretraining SLMs that brings together three complementary ideas. First, we identify structurally sparse sub-network initializations that consistently outperform randomly initialized models of similar size under the same compute budget. Second, we use evolutionary search to automatically discover high-quality sub-network initializations, providing better starting points for pretraining. Third, we apply knowledge distillation from larger teacher models to speed up training and improve generalization. Together, these components make SLM pretraining substantially more efficient: our best model, discovered using evolutionary search and initialized with LLM weights, matches the validation perplexity of a comparable Pythia SLM while requiring 9.2x fewer pretraining tokens. We release all code and models at https://github.com/whittle-org/whittle/, offering a practical and reproducible path toward cost-efficient small language model development at scale.
LLM Compression with Neural Architecture Search
Oct 09, 2024



Large language models (LLMs) exhibit remarkable reasoning abilities, allowing them to generalize across a wide range of downstream tasks, such as commonsense reasoning or instruction following. However, as LLMs scale, inference costs become increasingly prohibitive, accumulating significantly over their life cycle. This poses the question: Can we compress pre-trained LLMs to meet diverse size and latency requirements? We leverage Neural Architecture Search (NAS) to compress LLMs by pruning structural components, such as attention heads, neurons, and layers, aiming to achieve a Pareto-optimal balance between performance and efficiency. While NAS already achieved promising results on small language models in previous work, in this paper we propose various extensions that allow us to scale to LLMs. Compared to structural pruning baselines, we show that NAS improves performance up to 3.4% on MMLU with an on-device latency speedup.
HW-GPT-Bench: Hardware-Aware Architecture Benchmark for Language Models
May 16, 2024The expanding size of language models has created the necessity for a comprehensive examination across various dimensions that reflect the desiderata with respect to the tradeoffs between various hardware metrics, such as latency, energy consumption, GPU memory usage, and performance. There is a growing interest in establishing Pareto frontiers for different language model configurations to identify optimal models with specified hardware constraints. Notably, architectures that excel in latency on one device may not perform optimally on another. However, exhaustive training and evaluation of numerous architectures across diverse hardware configurations is computationally prohibitive. To this end, we propose HW-GPT-Bench, a hardware-aware language model surrogate benchmark, where we leverage weight-sharing techniques from Neural Architecture Search (NAS) to efficiently train a supernet proxy, encompassing language models of varying scales in a single model. We conduct profiling of these models across 13 devices, considering 5 hardware metrics and 3 distinct model scales. Finally, we showcase the usability of HW-GPT-Bench using 8 different multi-objective NAS algorithms and evaluate the quality of the resultant Pareto fronts. Through this benchmark, our objective is to propel and expedite research in the advancement of multi-objective methods for NAS and structural pruning in large language models.
Multi-objective Differentiable Neural Architecture Search
Feb 28, 2024Pareto front profiling in multi-objective optimization (MOO), i.e. finding a diverse set of Pareto optimal solutions, is challenging, especially with expensive objectives like neural network training. Typically, in MOO neural architecture search (NAS), we aim to balance performance and hardware metrics across devices. Prior NAS approaches simplify this task by incorporating hardware constraints into the objective function, but profiling the Pareto front necessitates a search for each constraint. In this work, we propose a novel NAS algorithm that encodes user preferences for the trade-off between performance and hardware metrics, and yields representative and diverse architectures across multiple devices in just one search run. To this end, we parameterize the joint architectural distribution across devices and multiple objectives via a hypernetwork that can be conditioned on hardware features and preference vectors, enabling zero-shot transferability to new devices. Extensive experiments with up to 19 hardware devices and 3 objectives showcase the effectiveness and scalability of our method. Finally, we show that, without additional costs, our method outperforms existing MOO NAS methods across qualitatively different search spaces and datasets, including MobileNetV3 on ImageNet-1k and a Transformer space on machine translation.
Weight-Entanglement Meets Gradient-Based Neural Architecture Search
Dec 16, 2023



Weight sharing is a fundamental concept in neural architecture search (NAS), enabling gradient-based methods to explore cell-based architecture spaces significantly faster than traditional blackbox approaches. In parallel, weight \emph{entanglement} has emerged as a technique for intricate parameter sharing among architectures within macro-level search spaces. %However, the macro structure of such spaces poses compatibility challenges for gradient-based NAS methods. %As a result, blackbox optimization methods have been commonly employed, particularly in conjunction with supernet training, to maintain search efficiency. %Due to the inherent differences in the structure of these search spaces, these Since weight-entanglement poses compatibility challenges for gradient-based NAS methods, these two paradigms have largely developed independently in parallel sub-communities. This paper aims to bridge the gap between these sub-communities by proposing a novel scheme to adapt gradient-based methods for weight-entangled spaces. This enables us to conduct an in-depth comparative assessment and analysis of the performance of gradient-based NAS in weight-entangled search spaces. Our findings reveal that this integration of weight-entanglement and gradient-based NAS brings forth the various benefits of gradient-based methods (enhanced performance, improved supernet training properties and superior any-time performance), while preserving the memory efficiency of weight-entangled spaces. The code for our work is openly accessible \href{https://anonymous.4open.science/r/TangleNAS-527C}{here}
Generative Flows with Invertible Attentions
Jun 26, 2021
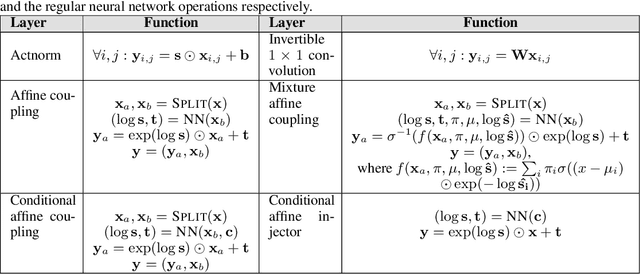


Flow-based generative models have shown excellent ability to explicitly learn the probability density function of data via a sequence of invertible transformations. Yet, modeling long-range dependencies over normalizing flows remains understudied. To fill the gap, in this paper, we introduce two types of invertible attention mechanisms for generative flow models. To be precise, we propose map-based and scaled dot-product attention for unconditional and conditional generative flow models. The key idea is to exploit split-based attention mechanisms to learn the attention weights and input representations on every two splits of flow feature maps. Our method provides invertible attention modules with tractable Jacobian determinants, enabling seamless integration of it at any positions of the flow-based models. The proposed attention mechanism can model the global data dependencies, leading to more comprehensive flow models. Evaluation on multiple generation tasks demonstrates that the introduced attention flow idea results in efficient flow models and compares favorably against the state-of-the-art unconditional and conditional generative flow methods.
Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
Jan 17, 2021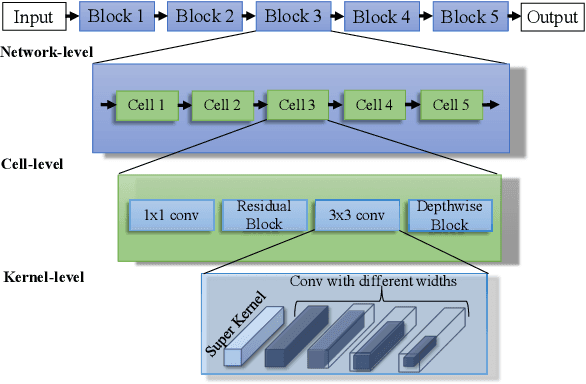
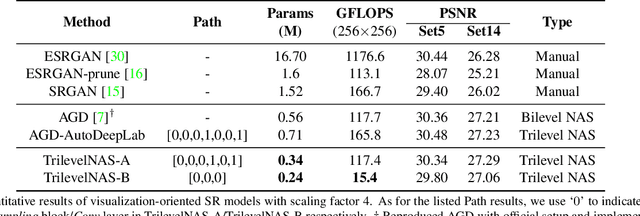
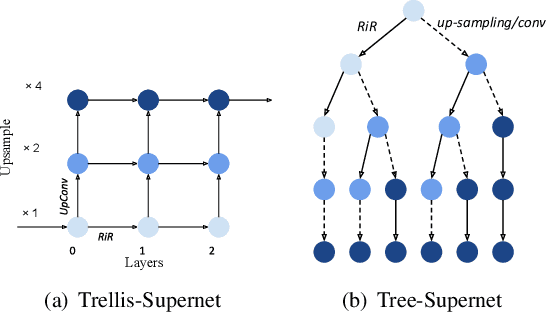
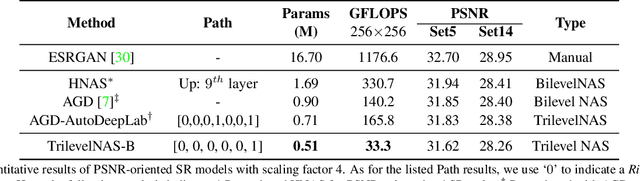
This paper proposes a trilevel neural architecture search (NAS) method for efficient single image super-resolution (SR). For that, we first define the discrete search space at three-level, i.e., at network-level, cell-level, and kernel-level (convolution-kernel). For modeling the discrete search space, we apply a new continuous relaxation on the discrete search spaces to build a hierarchical mixture of network-path, cell-operations, and kernel-width. Later an efficient search algorithm is proposed to perform optimization in a hierarchical supernet manner that provides a globally optimized and compressed network via joint convolution kernel width pruning, cell structure search, and network path optimization. Unlike current NAS methods, we exploit a sorted sparsestmax activation to let the three-level neural structures contribute sparsely. Consequently, our NAS optimization progressively converges to those neural structures with dominant contributions to the supernet. Additionally, our proposed optimization construction enables a simultaneous search and training in a single phase, which dramatically reduces search and train time compared to the traditional NAS algorithms. Experiments on the standard benchmark datasets demonstrate that our NAS algorithm provides SR models that are significantly lighter in terms of the number of parameters and FLOPS with PSNR value comparable to the current state-of-the-art.
Neural Architecture Search of SPD Manifold Networks
Oct 27, 2020



In this paper, we propose a new neural architecture search (NAS) problem of Symmetric Positive Definite (SPD) manifold networks. Unlike the conventional NAS problem, our problem requires to search for a unique computational cell called the SPD cell. This SPD cell serves as a basic building block of SPD neural architectures. An efficient solution to our problem is important to minimize the extraneous manual effort in the SPD neural architecture design. To accomplish this goal, we first introduce a geometrically rich and diverse SPD neural architecture search space for an efficient SPD cell design. Further, we model our new NAS problem using the supernet strategy which models the architecture search problem as a one-shot training process of a single supernet. Based on the supernet modeling, we exploit a differentiable NAS algorithm on our relaxed continuous search space for SPD neural architecture search. Statistical evaluation of our method on drone, action, and emotion recognition tasks mostly provides better results than the state-of-the-art SPD networks and NAS algorithms. Empirical results show that our algorithm excels in discovering better SPD network design, and providing models that are more than 3 times lighter than searched by state-of-the-art NAS algorithms.