 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Beat Classical Hyperparameter Optimization Algorithms? A Study on autoresearch
Mar 25, 2026The autoresearch repository enables an LLM agent to search for optimal hyperparameter configurations on an unconstrained search space by editing the training code directly. Given a fixed compute budget and constraints, we use \emph{autoresearch} as a testbed to compare classical hyperparameter optimization (HPO) algorithms against LLM-based methods on tuning the hyperparameters of a small language model. Within a fixed hyperparameter search space, classical HPO methods such as CMA-ES and TPE consistently outperform LLM-based agents. However, an LLM agent that directly edits training source code in an unconstrained search space narrows the gap to classical methods substantially despite using only a self-hosted open-weight 27B model. Methods that avoid out-of-memory failures outperform those with higher search diversity, suggesting that reliability matters more than exploration breadth. While small and mid-sized LLMs struggle to track optimization state across trials, classical methods lack domain knowledge. To bridge this gap, we introduce Centaur, a hybrid that shares CMA-ES's internal state, including mean vector, step-size, and covariance matrix, with an LLM. Centaur achieves the best result in our experiments, with its 0.8B variant outperforming the 27B variant, suggesting that a cheap LLM suffices when paired with a strong classical optimizer. The 0.8B model is insufficient for unconstrained code editing but sufficient for hybrid optimization, while scaling to 27B provides no advantage for fixed search space methods with the open-weight models tested. Code is available at https://github.com/ferreirafabio/autoresearch-automl.
Where to Begin: Efficient Pretraining via Subnetwork Selection and Distillation
Oct 08, 2025Small Language models (SLMs) offer an efficient and accessible alternative to Large Language Models (LLMs), delivering strong performance while using far fewer resources. We introduce a simple and effective framework for pretraining SLMs that brings together three complementary ideas. First, we identify structurally sparse sub-network initializations that consistently outperform randomly initialized models of similar size under the same compute budget. Second, we use evolutionary search to automatically discover high-quality sub-network initializations, providing better starting points for pretraining. Third, we apply knowledge distillation from larger teacher models to speed up training and improve generalization. Together, these components make SLM pretraining substantially more efficient: our best model, discovered using evolutionary search and initialized with LLM weights, matches the validation perplexity of a comparable Pythia SLM while requiring 9.2x fewer pretraining tokens. We release all code and models at https://github.com/whittle-org/whittle/, offering a practical and reproducible path toward cost-efficient small language model development at scale.
confopt: A Library for Implementation and Evaluation of Gradient-based One-Shot NAS Methods
Jul 22, 2025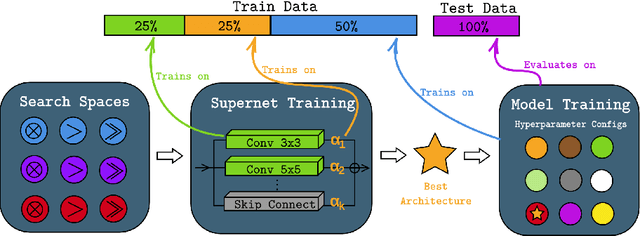
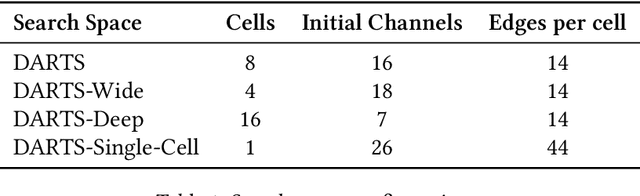
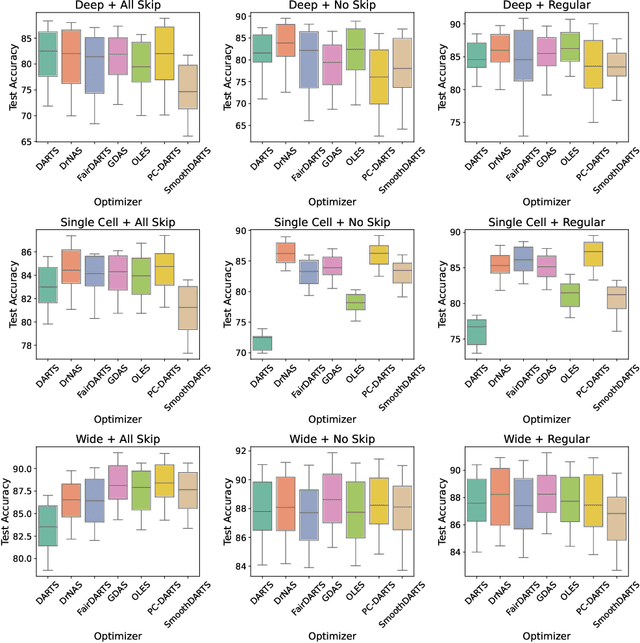
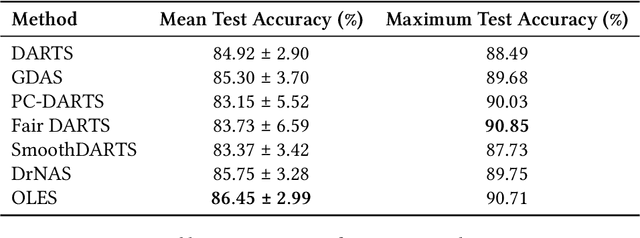
Gradient-based one-shot neural architecture search (NAS) has significantly reduced the cost of exploring architectural spaces with discrete design choices, such as selecting operations within a model. However, the field faces two major challenges. First, evaluations of gradient-based NAS methods heavily rely on the DARTS benchmark, despite the existence of other available benchmarks. This overreliance has led to saturation, with reported improvements often falling within the margin of noise. Second, implementations of gradient-based one-shot NAS methods are fragmented across disparate repositories, complicating fair and reproducible comparisons and further development. In this paper, we introduce Configurable Optimizer (confopt), an extensible library designed to streamline the development and evaluation of gradient-based one-shot NAS methods. Confopt provides a minimal API that makes it easy for users to integrate new search spaces, while also supporting the decomposition of NAS optimizers into their core components. We use this framework to create a suite of new DARTS-based benchmarks, and combine them with a novel evaluation protocol to reveal a critical flaw in how gradient-based one-shot NAS methods are currently assessed. The code can be found at https://github.com/automl/ConfigurableOptimizer.
Weight-Entanglement Meets Gradient-Based Neural Architecture Search
Dec 16, 2023



Weight sharing is a fundamental concept in neural architecture search (NAS), enabling gradient-based methods to explore cell-based architecture spaces significantly faster than traditional blackbox approaches. In parallel, weight \emph{entanglement} has emerged as a technique for intricate parameter sharing among architectures within macro-level search spaces. %However, the macro structure of such spaces poses compatibility challenges for gradient-based NAS methods. %As a result, blackbox optimization methods have been commonly employed, particularly in conjunction with supernet training, to maintain search efficiency. %Due to the inherent differences in the structure of these search spaces, these Since weight-entanglement poses compatibility challenges for gradient-based NAS methods, these two paradigms have largely developed independently in parallel sub-communities. This paper aims to bridge the gap between these sub-communities by proposing a novel scheme to adapt gradient-based methods for weight-entangled spaces. This enables us to conduct an in-depth comparative assessment and analysis of the performance of gradient-based NAS in weight-entangled search spaces. Our findings reveal that this integration of weight-entanglement and gradient-based NAS brings forth the various benefits of gradient-based methods (enhanced performance, improved supernet training properties and superior any-time performance), while preserving the memory efficiency of weight-entangled spaces. The code for our work is openly accessible \href{https://anonymous.4open.science/r/TangleNAS-527C}{here}
NAS-Bench-Suite-Zero: Accelerating Research on Zero Cost Proxies
Oct 06, 2022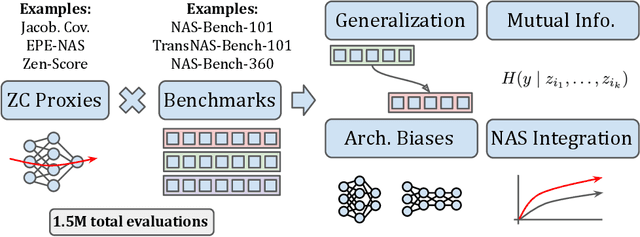
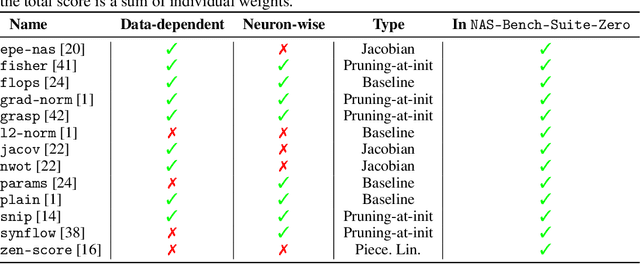
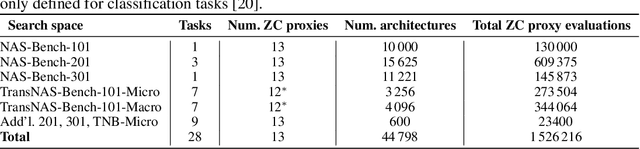
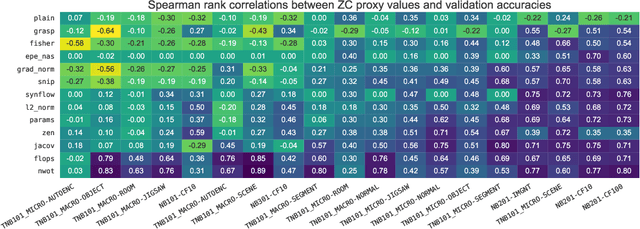
Zero-cost proxies (ZC proxies) are a recent architecture performance prediction technique aiming to significantly speed up algorithms for neural architecture search (NAS). Recent work has shown that these techniques show great promise, but certain aspects, such as evaluating and exploiting their complementary strengths, are under-studied. In this work, we create NAS-Bench-Suite: we evaluate 13 ZC proxies across 28 tasks, creating by far the largest dataset (and unified codebase) for ZC proxies, enabling orders-of-magnitude faster experiments on ZC proxies, while avoiding confounding factors stemming from different implementations. To demonstrate the usefulness of NAS-Bench-Suite, we run a large-scale analysis of ZC proxies, including a bias analysis, and the first information-theoretic analysis which concludes that ZC proxies capture substantial complementary information. Motivated by these findings, we present a procedure to improve the performance of ZC proxies by reducing biases such as cell size, and we also show that incorporating all 13 ZC proxies into the surrogate models used by NAS algorithms can improve their predictive performance by up to 42%. Our code and datasets are available at https://github.com/automl/naslib/tree/zerocost.
NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy
Feb 11, 2022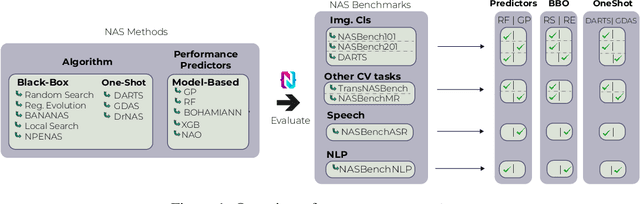
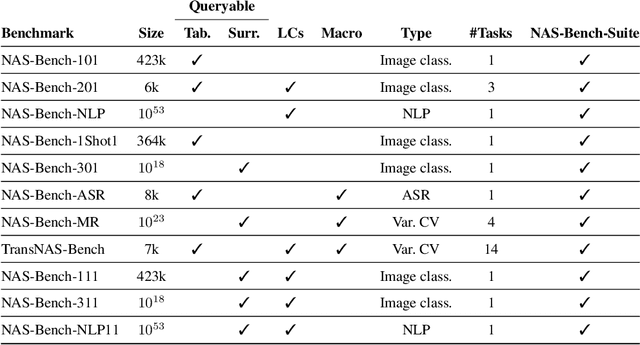
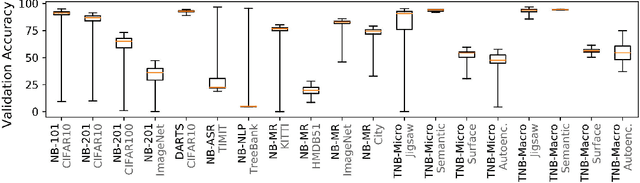
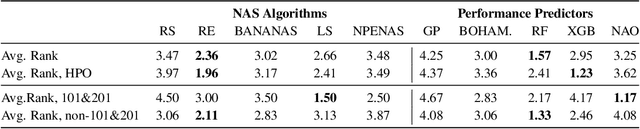
The release of tabular benchmarks, such as NAS-Bench-101 and NAS-Bench-201, has significantly lowered the computational overhead for conducting scientific research in neural architecture search (NAS). Although they have been widely adopted and used to tune real-world NAS algorithms, these benchmarks are limited to small search spaces and focus solely on image classification. Recently, several new NAS benchmarks have been introduced that cover significantly larger search spaces over a wide range of tasks, including object detection, speech recognition, and natural language processing. However, substantial differences among these NAS benchmarks have so far prevented their widespread adoption, limiting researchers to using just a few benchmarks. In this work, we present an in-depth analysis of popular NAS algorithms and performance prediction methods across 25 different combinations of search spaces and datasets, finding that many conclusions drawn from a few NAS benchmarks do not generalize to other benchmarks. To help remedy this problem, we introduce NAS-Bench-Suite, a comprehensive and extensible collection of NAS benchmarks, accessible through a unified interface, created with the aim to facilitate reproducible, generalizable, and rapid NAS research. Our code is available at https://github.com/automl/naslib.