 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBHCast: Unlocking Black Hole Plasma Dynamics from a Single Blurry Image with Long-Term Forecasting
Mar 24, 2026The Event Horizon Telescope (EHT) delivered the first image of a black hole by capturing the light from its surrounding accretion flow, revealing structure but not dynamics. Simulations of black hole accretion dynamics are essential for interpreting EHT images but costly to generate and impractical for inference. Motivated by this bottleneck, BHCast presents a framework for forecasting black hole plasma dynamics from a single, blurry snapshot, such as those captured by the EHT. At its core, BHCast is a neural model that transforms a static image into forecasted future frames, revealing the underlying dynamics hidden within one snapshot. With a multi-scale pyramid loss, we demonstrate how autoregressive forecasting can simultaneously super-resolve and evolve a blurry frame into a coherent, high-resolution movie that remains stable over long time horizons. From forecasted dynamics, we can then extract interpretable spatio-temporal features, such as pattern speed (rotation rate) and pitch angle. Finally, BHCast uses gradient-boosting trees to recover black hole properties from these plasma features, including the spin and viewing inclination angle. The separation between forecasting and inference provides modular flexibility, interpretability, and robust uncertainty quantification. We demonstrate the effectiveness of BHCast on simulations of two distinct black hole accretion systems, Sagittarius A* and M87*, by testing on simulated frames blurred to EHT resolution and real EHT images of M87*. Ultimately, our methodology establishes a scalable paradigm for solving inverse problems, demonstrating the potential of learned dynamics to unlock insights from resolution-limited scientific data.
DPQuant: Efficient and Differentially-Private Model Training via Dynamic Quantization Scheduling
Sep 03, 2025Differentially-Private SGD (DP-SGD) is a powerful technique to protect user privacy when using sensitive data to train neural networks. During training, converting model weights and activations into low-precision formats, i.e., quantization, can drastically reduce training times, energy consumption, and cost, and is thus a widely used technique. In this work, we demonstrate that quantization causes significantly higher accuracy degradation in DP-SGD compared to regular SGD. We observe that this is caused by noise injection in DP-SGD, which amplifies quantization variance, leading to disproportionately large accuracy degradation. To address this challenge, we present QPQuant, a dynamic quantization framework that adaptively selects a changing subset of layers to quantize at each epoch. Our method combines two key ideas that effectively reduce quantization variance: (i) probabilistic sampling of the layers that rotates which layers are quantized every epoch, and (ii) loss-aware layer prioritization, which uses a differentially private loss sensitivity estimator to identify layers that can be quantized with minimal impact on model quality. This estimator consumes a negligible fraction of the overall privacy budget, preserving DP guarantees. Empirical evaluations on ResNet18, ResNet50, and DenseNet121 across a range of datasets demonstrate that DPQuant consistently outperforms static quantization baselines, achieving near Pareto-optimal accuracy-compute trade-offs and up to 2.21x theoretical throughput improvements on low-precision hardware, with less than 2% drop in validation accuracy.
Proteus: Preserving Model Confidentiality during Graph Optimizations
Apr 18, 2024
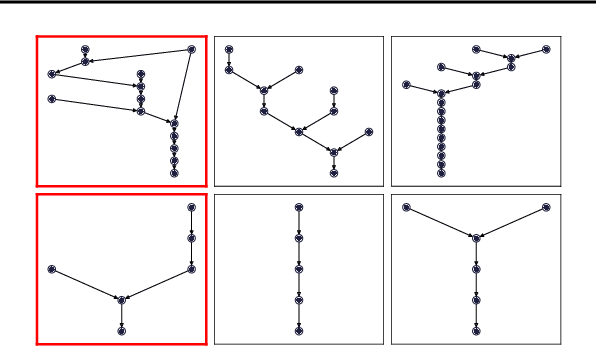
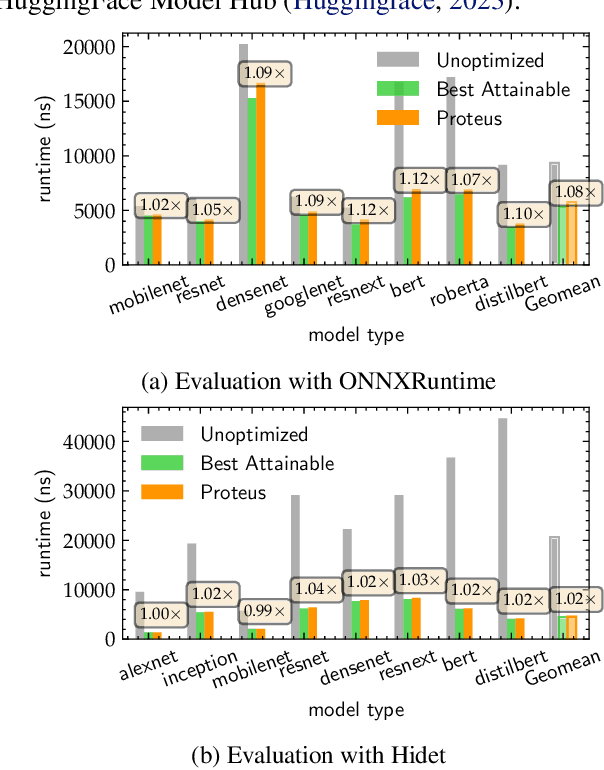
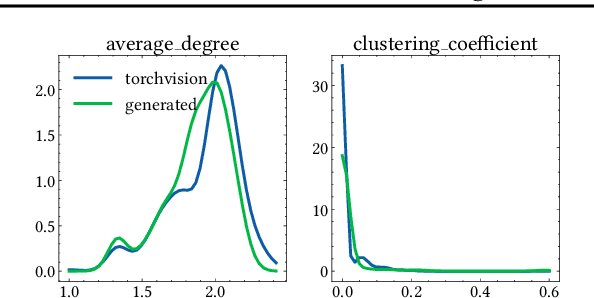
Deep learning (DL) models have revolutionized numerous domains, yet optimizing them for computational efficiency remains a challenging endeavor. Development of new DL models typically involves two parties: the model developers and performance optimizers. The collaboration between the parties often necessitates the model developers exposing the model architecture and computational graph to the optimizers. However, this exposure is undesirable since the model architecture is an important intellectual property, and its innovations require significant investments and expertise. During the exchange, the model is also vulnerable to adversarial attacks via model stealing. This paper presents Proteus, a novel mechanism that enables model optimization by an independent party while preserving the confidentiality of the model architecture. Proteus obfuscates the protected model by partitioning its computational graph into subgraphs and concealing each subgraph within a large pool of generated realistic subgraphs that cannot be easily distinguished from the original. We evaluate Proteus on a range of DNNs, demonstrating its efficacy in preserving confidentiality without compromising performance optimization opportunities. Proteus effectively hides the model as one alternative among up to $10^{32}$ possible model architectures, and is resilient against attacks with a learning-based adversary. We also demonstrate that heuristic based and manual approaches are ineffective in identifying the protected model. To our knowledge, Proteus is the first work that tackles the challenge of model confidentiality during performance optimization. Proteus will be open-sourced for direct use and experimentation, with easy integration with compilers such as ONNXRuntime.
Speeding up Fourier Neural Operators via Mixed Precision
Jul 27, 2023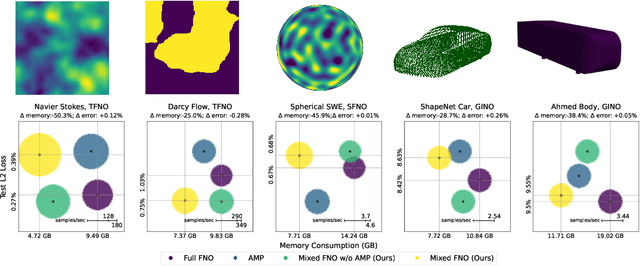

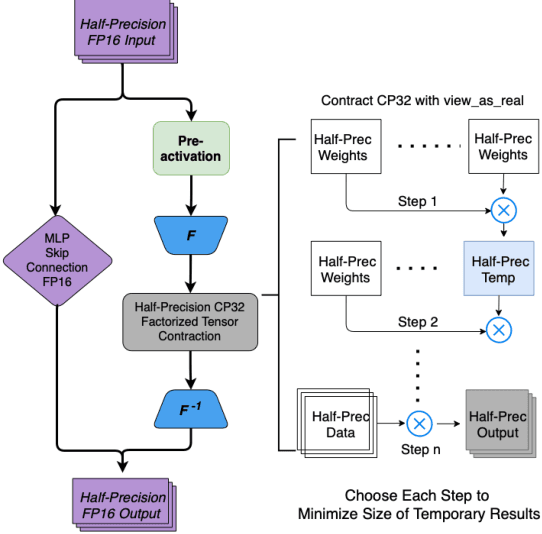
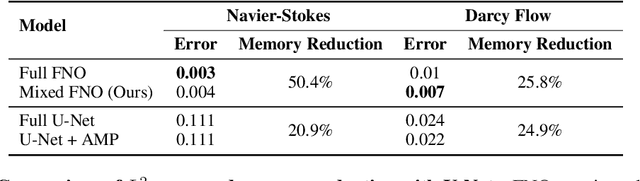
The Fourier neural operator (FNO) is a powerful technique for learning surrogate maps for partial differential equation (PDE) solution operators. For many real-world applications, which often require high-resolution data points, training time and memory usage are significant bottlenecks. While there are mixed-precision training techniques for standard neural networks, those work for real-valued datatypes on finite dimensions and therefore cannot be directly applied to FNO, which crucially operates in the (complex-valued) Fourier domain and in function spaces. On the other hand, since the Fourier transform is already an approximation (due to discretization error), we do not need to perform the operation at full precision. In this work, we (i) profile memory and runtime for FNO with full and mixed-precision training, (ii) conduct a study on the numerical stability of mixed-precision training of FNO, and (iii) devise a training routine which substantially decreases training time and memory usage (up to 34%), with little or no reduction in accuracy, on the Navier-Stokes and Darcy flow equations. Combined with the recently proposed tensorized FNO (Kossaifi et al., 2023), the resulting model has far better performance while also being significantly faster than the original FNO.
Self-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Dec 23, 2022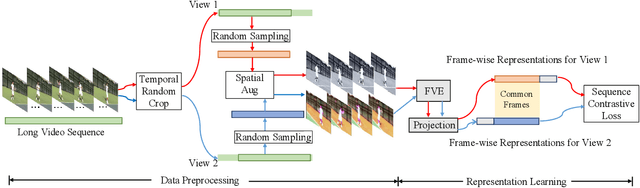
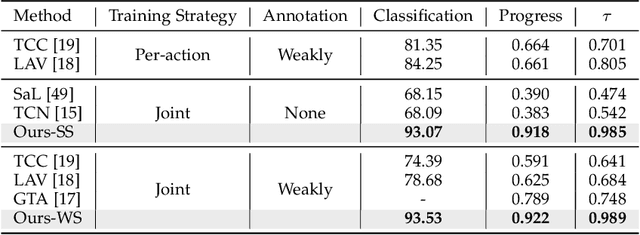
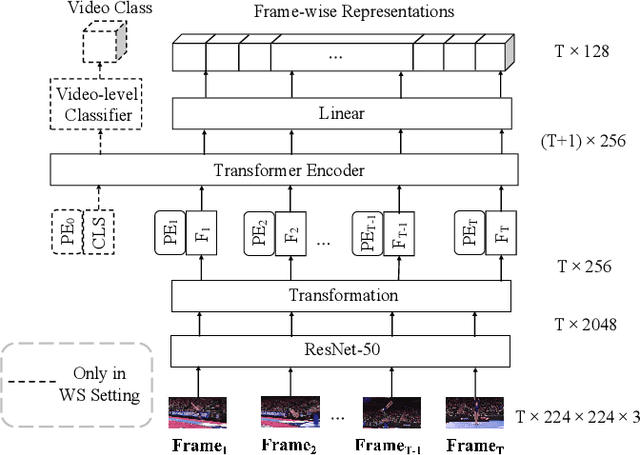
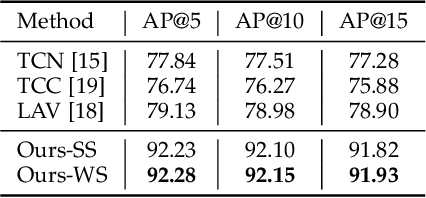
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.
AutoML for Climate Change: A Call to Action
Oct 07, 2022

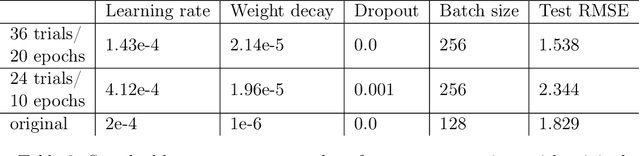

The challenge that climate change poses to humanity has spurred a rapidly developing field of artificial intelligence research focused on climate change applications. The climate change AI (CCAI) community works on a diverse, challenging set of problems which often involve physics-constrained ML or heterogeneous spatiotemporal data. It would be desirable to use automated machine learning (AutoML) techniques to automatically find high-performing architectures and hyperparameters for a given dataset. In this work, we benchmark popular AutoML libraries on three high-leverage CCAI applications: climate modeling, wind power forecasting, and catalyst discovery. We find that out-of-the-box AutoML libraries currently fail to meaningfully surpass the performance of human-designed CCAI models. However, we also identify a few key weaknesses, which stem from the fact that most AutoML techniques are tailored to computer vision and NLP applications. For example, while dozens of search spaces have been designed for image and language data, none have been designed for spatiotemporal data. Addressing these key weaknesses can lead to the discovery of novel architectures that yield substantial performance gains across numerous CCAI applications. Therefore, we present a call to action to the AutoML community, since there are a number of concrete, promising directions for future work in the space of AutoML for CCAI. We release our code and a list of resources at https://github.com/climate-change-automl/climate-change-automl.
NAS-Bench-Suite-Zero: Accelerating Research on Zero Cost Proxies
Oct 06, 2022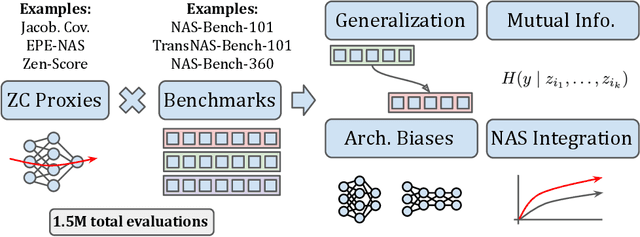
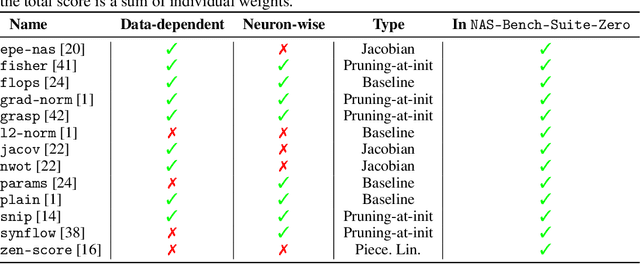
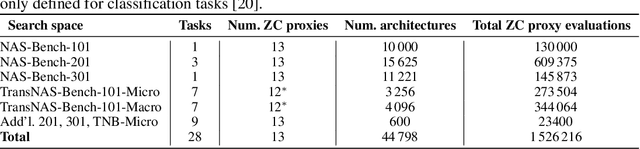
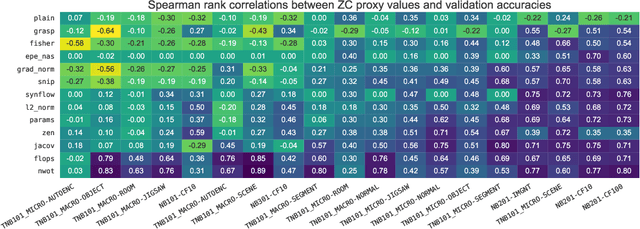
Zero-cost proxies (ZC proxies) are a recent architecture performance prediction technique aiming to significantly speed up algorithms for neural architecture search (NAS). Recent work has shown that these techniques show great promise, but certain aspects, such as evaluating and exploiting their complementary strengths, are under-studied. In this work, we create NAS-Bench-Suite: we evaluate 13 ZC proxies across 28 tasks, creating by far the largest dataset (and unified codebase) for ZC proxies, enabling orders-of-magnitude faster experiments on ZC proxies, while avoiding confounding factors stemming from different implementations. To demonstrate the usefulness of NAS-Bench-Suite, we run a large-scale analysis of ZC proxies, including a bias analysis, and the first information-theoretic analysis which concludes that ZC proxies capture substantial complementary information. Motivated by these findings, we present a procedure to improve the performance of ZC proxies by reducing biases such as cell size, and we also show that incorporating all 13 ZC proxies into the surrogate models used by NAS algorithms can improve their predictive performance by up to 42%. Our code and datasets are available at https://github.com/automl/naslib/tree/zerocost.
NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search
Oct 26, 2021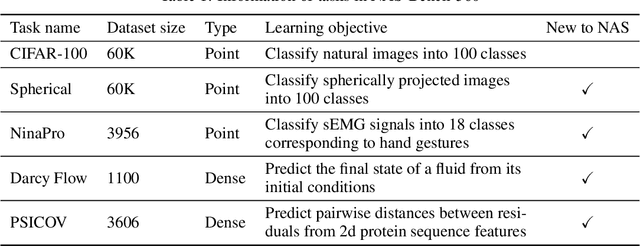
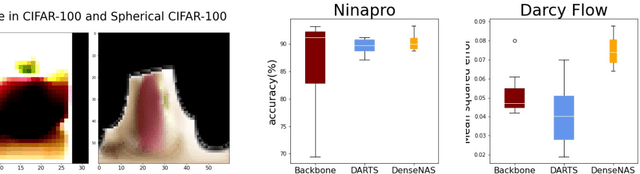
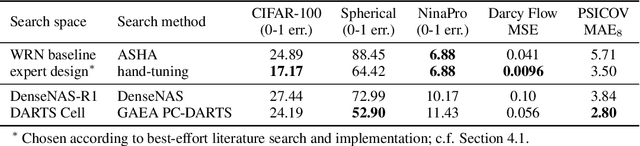
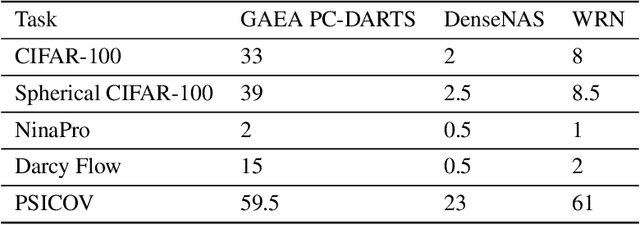
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize performance on well-studied tasks, e.g., image classification on CIFAR and ImageNet. This makes the applicability of NAS approaches in more diverse areas inadequately understood. In this paper, we present NAS-Bench-360, a benchmark suite for evaluating state-of-the-art NAS methods for convolutional neural networks (CNNs). To construct it, we curate a collection of ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. By carefully selecting tasks that can both interoperate with modern CNN-based search methods but that are also far-afield from their original development domain, we can use NAS-Bench-360 to investigate the following central question: do existing state-of-the-art NAS methods perform well on diverse tasks? Our experiments show that a modern NAS procedure designed for image classification can indeed find good architectures for tasks with other dimensionalities and learning objectives; however, the same method struggles against more task-specific methods and performs catastrophically poorly on classification in non-vision domains. The case for NAS robustness becomes even more dire in a resource-constrained setting, where a recent NAS method provides little-to-no benefit over much simpler baselines. These results demonstrate the need for a benchmark such as NAS-Bench-360 to help develop NAS approaches that work well on a variety of tasks, a crucial component of a truly robust and automated pipeline. We conclude with a demonstration of the kind of future research our suite of tasks will enable. All data and code is made publicly available.
Federated Hyperparameter Tuning: Challenges, Baselines, and Connections to Weight-Sharing
Jun 08, 2021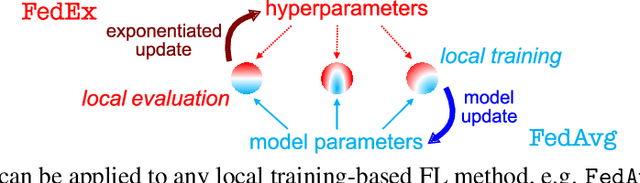
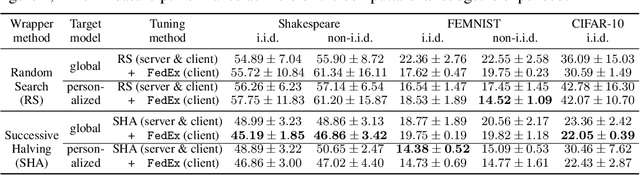
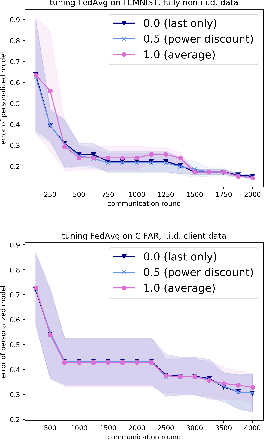

Tuning hyperparameters is a crucial but arduous part of the machine learning pipeline. Hyperparameter optimization is even more challenging in federated learning, where models are learned over a distributed network of heterogeneous devices; here, the need to keep data on device and perform local training makes it difficult to efficiently train and evaluate configurations. In this work, we investigate the problem of federated hyperparameter tuning. We first identify key challenges and show how standard approaches may be adapted to form baselines for the federated setting. Then, by making a novel connection to the neural architecture search technique of weight-sharing, we introduce a new method, FedEx, to accelerate federated hyperparameter tuning that is applicable to widely-used federated optimization methods such as FedAvg and recent variants. Theoretically, we show that a FedEx variant correctly tunes the on-device learning rate in the setting of online convex optimization across devices. Empirically, we show that FedEx can outperform natural baselines for federated hyperparameter tuning by several percentage points on the Shakespeare, FEMNIST, and CIFAR-10 benchmarks, obtaining higher accuracy using the same training budget.
Towards Deeper Generative Architectures for GANs using Dense connections
Apr 30, 2018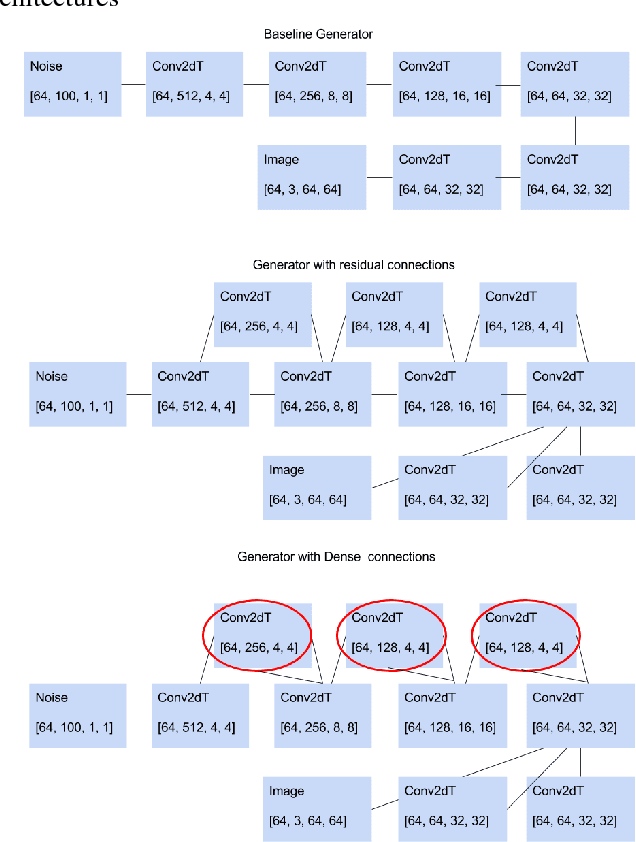
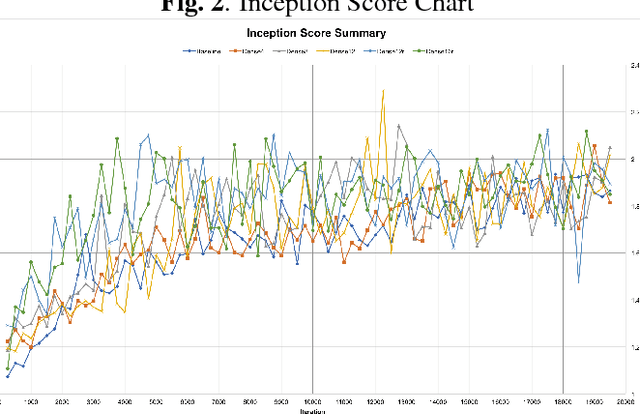

In this paper, we present the result of adopting skip connections and dense layers, previously used in image classification tasks, in the Fisher GAN implementation. We have experimented with different numbers of layers and inserting these connections in different sections of the network. Our findings suggests that networks implemented with the connections produce better images than the baseline, and the number of connections added has only slight effect on the result.