 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Paper and Code
Dec 23, 2022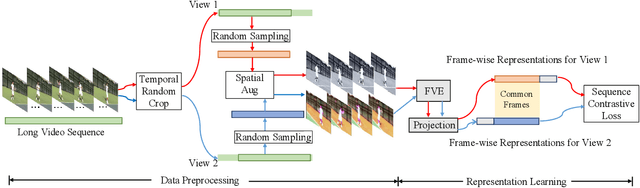
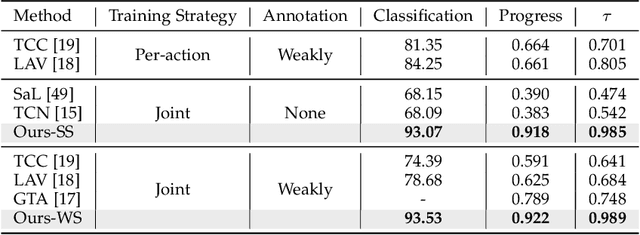
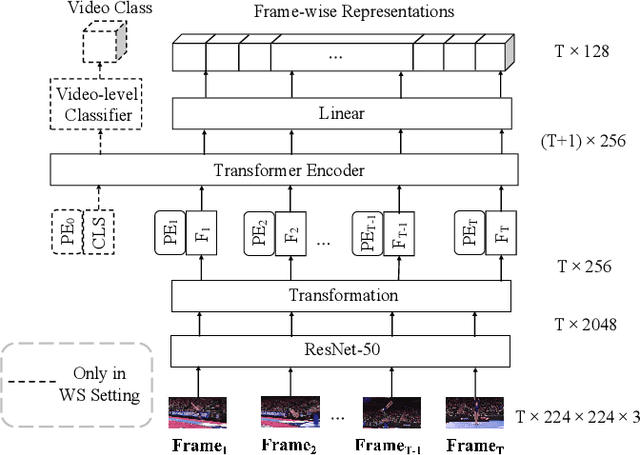
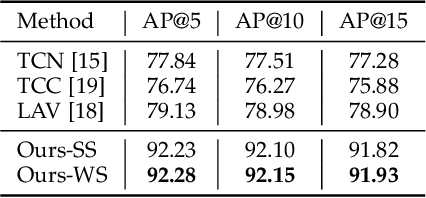
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.