 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Video Generation: Shaping Video Generation Across Time and Space
May 20, 2026Diffusion models have achieved impressive performance in video generation, but their iterative denoising process remains computationally expensive due to the large number of tokens processed at each timestep. Recently, progressive resolution sampling has emerged as a promising acceleration approach by reducing latent resolution in early stages. However, scaling this idea to video generation remains challenging, as the additional temporal dimension introduces diverse spatio-temporal demands across different videos, and compressing only a single dimension often leads to limited acceleration or degraded quality. Therefore, we propose DVG, a Dynamic Video Generation framework that jointly allocates computation across time and space, automatically selecting content-aware acceleration strategies without manual tuning or retraining. DVG achieves near-lossless acceleration across models and tasks, reaching up to 7 times speedup on HunyuanVideo and HunyuanVideo-1.5, and 18 times when combined with distillation, demonstrating its potential as a key component in today's large-scale efficient video generation systems. Our code is in supplementary material and will be released on Github.
SpecEdit: Training-Free Acceleration for Diffusion based Image Editing via Semantic Locking
May 04, 2026Diffusion-based image editing offers strong semantic controllability, but remains computationally expensive due to iterative high-resolution denoising over all spatial tokens. Dynamic-resolution sampling reduces this cost by performing early steps at reduced resolution. However, existing approaches prioritize upsampling using low-level heuristics such as edge detection or channel variance, which are weakly aligned with editing semantics and may lead to structural inconsistency. Moreover, spatial regions are often upsampled without verifying whether semantic modification is actually required, resulting in redundant high-resolution computation and accumulated errors. Therefore, we propose SpecEdit, a training-free dynamic-resolution framework tailored for diffusion-based image editing. SpecEdit follows a draft-and-verify scheme: a low-resolution draft first estimates the semantic outcome, after which token-level discrepancies are used to identify edit-relevant tokens for high-resolution denoising, while the remaining tokens stay at a coarse resolution. Experiments on Qwen-Image-Edit and FLUX.1-Kontext-dev demonstrate up to 10x and 7x acceleration, while maintaining strong quality. SpecEdit is complementary to step distillation and other acceleration techniques, achieving up to 13x speedup when combined with existing methods. Our code is in supplementary material and will be released on GitHub.
From Sketch to Fresco: Efficient Diffusion Transformer with Progressive Resolution
Jan 12, 2026Diffusion Transformers achieve impressive generative quality but remain computationally expensive due to iterative sampling. Recently, dynamic resolution sampling has emerged as a promising acceleration technique by reducing the resolution of early sampling steps. However, existing methods rely on heuristic re-noising at every resolution transition, injecting noise that breaks cross-stage consistency and forces the model to relearn global structure. In addition, these methods indiscriminately upsample the entire latent space at once without checking which regions have actually converged, causing accumulated errors, and visible artifacts. Therefore, we propose \textbf{Fresco}, a dynamic resolution framework that unifies re-noise and global structure across stages with progressive upsampling, preserving both the efficiency of low-resolution drafting and the fidelity of high-resolution refinement, with all stages aligned toward the same final target. Fresco achieves near-lossless acceleration across diverse domains and models, including 10$\times$ speedup on FLUX, and 5$\times$ on HunyuanVideo, while remaining orthogonal to distillation, quantization and feature caching, reaching 22$\times$ speedup when combined with distilled models. Our code is in supplementary material and will be released on Github.
Forecast the Principal, Stabilize the Residual: Subspace-Aware Feature Caching for Efficient Diffusion Transformers
Jan 12, 2026Diffusion Transformer (DiT) models have achieved unprecedented quality in image and video generation, yet their iterative sampling process remains computationally prohibitive. To accelerate inference, feature caching methods have emerged by reusing intermediate representations across timesteps. However, existing caching approaches treat all feature components uniformly. We reveal that DiT feature spaces contain distinct principal and residual subspaces with divergent temporal behavior: the principal subspace evolves smoothly and predictably, while the residual subspace exhibits volatile, low-energy oscillations that resist accurate prediction. Building on this insight, we propose SVD-Cache, a subspace-aware caching framework that decomposes diffusion features via Singular Value Decomposition (SVD), applies exponential moving average (EMA) prediction to the dominant low-rank components, and directly reuses the residual subspace. Extensive experiments demonstrate that SVD-Cache achieves near-lossless across diverse models and methods, including 5.55$\times$ speedup on FLUX and HunyuanVideo, and compatibility with model acceleration techniques including distillation, quantization and sparse attention. Our code is in supplementary material and will be released on Github.
HiCache: Training-free Acceleration of Diffusion Models via Hermite Polynomial-based Feature Caching
Aug 23, 2025Diffusion models have achieved remarkable success in content generation but suffer from prohibitive computational costs due to iterative sampling. While recent feature caching methods tend to accelerate inference through temporal extrapolation, these methods still suffer from server quality loss due to the failure in modeling the complex dynamics of feature evolution. To solve this problem, this paper presents HiCache, a training-free acceleration framework that fundamentally improves feature prediction by aligning mathematical tools with empirical properties. Our key insight is that feature derivative approximations in Diffusion Transformers exhibit multivariate Gaussian characteristics, motivating the use of Hermite polynomials-the potentially theoretically optimal basis for Gaussian-correlated processes. Besides, We further introduce a dual-scaling mechanism that ensures numerical stability while preserving predictive accuracy. Extensive experiments demonstrate HiCache's superiority: achieving 6.24x speedup on FLUX.1-dev while exceeding baseline quality, maintaining strong performance across text-to-image, video generation, and super-resolution tasks. Core implementation is provided in the appendix, with complete code to be released upon acceptance.
SAMRefiner: Taming Segment Anything Model for Universal Mask Refinement
Feb 10, 2025



In this paper, we explore a principal way to enhance the quality of widely pre-existing coarse masks, enabling them to serve as reliable training data for segmentation models to reduce the annotation cost. In contrast to prior refinement techniques that are tailored to specific models or tasks in a close-world manner, we propose SAMRefiner, a universal and efficient approach by adapting SAM to the mask refinement task. The core technique of our model is the noise-tolerant prompting scheme. Specifically, we introduce a multi-prompt excavation strategy to mine diverse input prompts for SAM (i.e., distance-guided points, context-aware elastic bounding boxes, and Gaussian-style masks) from initial coarse masks. These prompts can collaborate with each other to mitigate the effect of defects in coarse masks. In particular, considering the difficulty of SAM to handle the multi-object case in semantic segmentation, we introduce a split-then-merge (STM) pipeline. Additionally, we extend our method to SAMRefiner++ by introducing an additional IoU adaption step to further boost the performance of the generic SAMRefiner on the target dataset. This step is self-boosted and requires no additional annotation. The proposed framework is versatile and can flexibly cooperate with existing segmentation methods. We evaluate our mask framework on a wide range of benchmarks under different settings, demonstrating better accuracy and efficiency. SAMRefiner holds significant potential to expedite the evolution of refinement tools. Our code is available at https://github.com/linyq2117/SAMRefiner.
GATE OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation
Dec 01, 2024Multimodal Large Language Models (MLLMs) have made significant strides in visual understanding and generation tasks. However, generating interleaved image-text content remains a challenge, which requires integrated multimodal understanding and generation abilities. While the progress in unified models offers new solutions, existing benchmarks are insufficient for evaluating these methods due to data size and diversity limitations. To bridge this gap, we introduce GATE OpenING (OpenING), a comprehensive benchmark comprising 5,400 high-quality human-annotated instances across 56 real-world tasks. OpenING covers diverse daily scenarios such as travel guide, design, and brainstorming, offering a robust platform for challenging interleaved generation methods. In addition, we present IntJudge, a judge model for evaluating open-ended multimodal generation methods. Trained with a novel data pipeline, our IntJudge achieves an agreement rate of 82. 42% with human judgments, outperforming GPT-based evaluators by 11.34%. Extensive experiments on OpenING reveal that current interleaved generation methods still have substantial room for improvement. Key findings on interleaved image-text generation are further presented to guide the development of next-generation models. The OpenING is open-sourced at https://opening-benchmark.github.io.
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024



Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
UniHDA: Towards Universal Hybrid Domain Adaptation of Image Generators
Jan 23, 2024

Generative domain adaptation has achieved remarkable progress, enabling us to adapt a pre-trained generator to a new target domain. However, existing methods simply adapt the generator to a single target domain and are limited to a single modality, either text-driven or image-driven. Moreover, they are prone to overfitting domain-specific attributes, which inevitably compromises cross-domain consistency. In this paper, we propose UniHDA, a unified and versatile framework for generative hybrid domain adaptation with multi-modal references from multiple domains. We use CLIP encoder to project multi-modal references into a unified embedding space and then linear interpolate the direction vectors from multiple target domains to achieve hybrid domain adaptation. To ensure the cross-domain consistency, we propose a novel cross-domain spatial structure (CSS) loss that maintains detailed spatial structure information between source and target generator. Experiments show that the adapted generator can synthesise realistic images with various attribute compositions. Additionally, our framework is versatile to multiple generators, \eg, StyleGAN2 and Diffusion Models.
TagCLIP: A Local-to-Global Framework to Enhance Open-Vocabulary Multi-Label Classification of CLIP Without Training
Dec 20, 2023

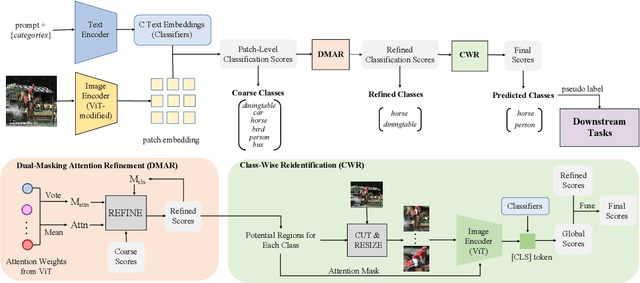
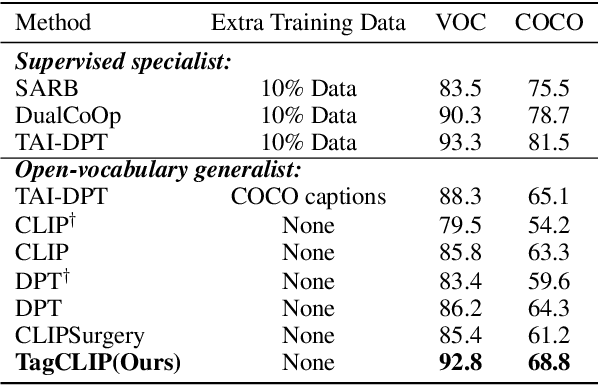
Contrastive Language-Image Pre-training (CLIP) has demonstrated impressive capabilities in open-vocabulary classification. The class token in the image encoder is trained to capture the global features to distinguish different text descriptions supervised by contrastive loss, making it highly effective for single-label classification. However, it shows poor performance on multi-label datasets because the global feature tends to be dominated by the most prominent class and the contrastive nature of softmax operation aggravates it. In this study, we observe that the multi-label classification results heavily rely on discriminative local features but are overlooked by CLIP. As a result, we dissect the preservation of patch-wise spatial information in CLIP and proposed a local-to-global framework to obtain image tags. It comprises three steps: (1) patch-level classification to obtain coarse scores; (2) dual-masking attention refinement (DMAR) module to refine the coarse scores; (3) class-wise reidentification (CWR) module to remedy predictions from a global perspective. This framework is solely based on frozen CLIP and significantly enhances its multi-label classification performance on various benchmarks without dataset-specific training. Besides, to comprehensively assess the quality and practicality of generated tags, we extend their application to the downstream task, i.e., weakly supervised semantic segmentation (WSSS) with generated tags as image-level pseudo labels. Experiments demonstrate that this classify-then-segment paradigm dramatically outperforms other annotation-free segmentation methods and validates the effectiveness of generated tags. Our code is available at https://github.com/linyq2117/TagCLIP.