 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
Searching Priors Makes Text-to-Video Synthesis Better
Jun 05, 2024
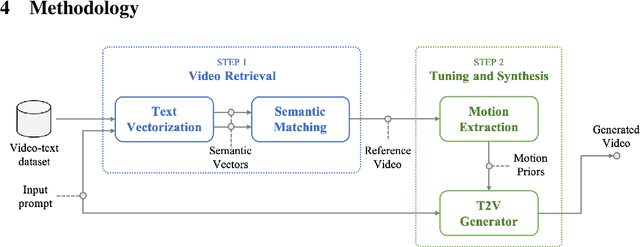


Significant advancements in video diffusion models have brought substantial progress to the field of text-to-video (T2V) synthesis. However, existing T2V synthesis model struggle to accurately generate complex motion dynamics, leading to a reduction in video realism. One possible solution is to collect massive data and train the model on it, but this would be extremely expensive. To alleviate this problem, in this paper, we reformulate the typical T2V generation process as a search-based generation pipeline. Instead of scaling up the model training, we employ existing videos as the motion prior database. Specifically, we divide T2V generation process into two steps: (i) For a given prompt input, we search existing text-video datasets to find videos with text labels that closely match the prompt motions. We propose a tailored search algorithm that emphasizes object motion features. (ii) Retrieved videos are processed and distilled into motion priors to fine-tune a pre-trained base T2V model, followed by generating desired videos using input prompt. By utilizing the priors gleaned from the searched videos, we enhance the realism of the generated videos' motion. All operations can be finished on a single NVIDIA RTX 4090 GPU. We validate our method against state-of-the-art T2V models across diverse prompt inputs. The code will be public.
Regulating Intermediate 3D Features for Vision-Centric Autonomous Driving
Dec 19, 2023



Multi-camera perception tasks have gained significant attention in the field of autonomous driving. However, existing frameworks based on Lift-Splat-Shoot (LSS) in the multi-camera setting cannot produce suitable dense 3D features due to the projection nature and uncontrollable densification process. To resolve this problem, we propose to regulate intermediate dense 3D features with the help of volume rendering. Specifically, we employ volume rendering to process the dense 3D features to obtain corresponding 2D features (e.g., depth maps, semantic maps), which are supervised by associated labels in the training. This manner regulates the generation of dense 3D features on the feature level, providing appropriate dense and unified features for multiple perception tasks. Therefore, our approach is termed Vampire, stands for "Volume rendering As Multi-camera Perception Intermediate feature REgulator". Experimental results on the Occ3D and nuScenes datasets demonstrate that Vampire facilitates fine-grained and appropriate extraction of dense 3D features, and is competitive with existing SOTA methods across diverse downstream perception tasks like 3D occupancy prediction, LiDAR segmentation and 3D objection detection, while utilizing moderate GPU resources. We provide a video demonstration in the supplementary materials and Codes are available at github.com/cskkxjk/Vampire.
Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning
Nov 29, 2023



Recent one-shot video tuning methods, which fine-tune the network on a specific video based on pre-trained text-to-image models (e.g., Stable Diffusion), are popular in the community because of the flexibility. However, these methods often produce videos marred by incoherence and inconsistency. To address these limitations, this paper introduces a simple yet effective noise constraint across video frames. This constraint aims to regulate noise predictions across their temporal neighbors, resulting in smooth latents. It can be simply included as a loss term during the training phase. By applying the loss to existing one-shot video tuning methods, we significantly improve the overall consistency and smoothness of the generated videos. Furthermore, we argue that current video evaluation metrics inadequately capture smoothness. To address this, we introduce a novel metric that considers detailed features and their temporal dynamics. Experimental results validate the effectiveness of our approach in producing smoother videos on various one-shot video tuning baselines. The source codes and video demos are available at \href{https://github.com/SPengLiang/SmoothVideo}{https://github.com/SPengLiang/SmoothVideo}.
Few-shot Hybrid Domain Adaptation of Image Generators
Oct 30, 2023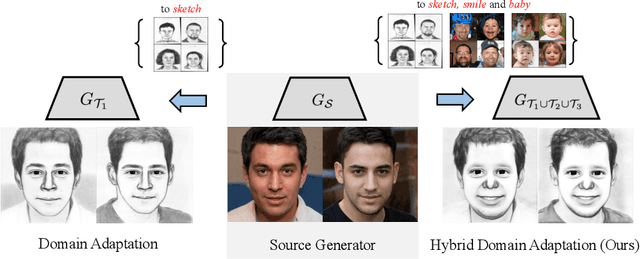
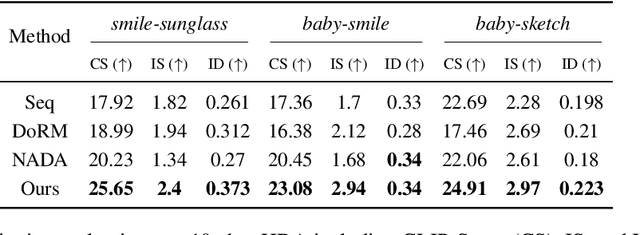
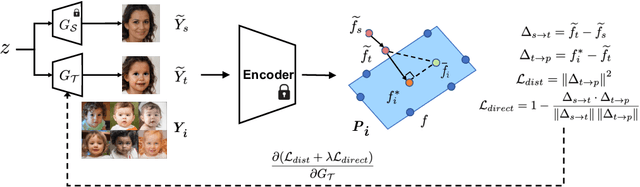
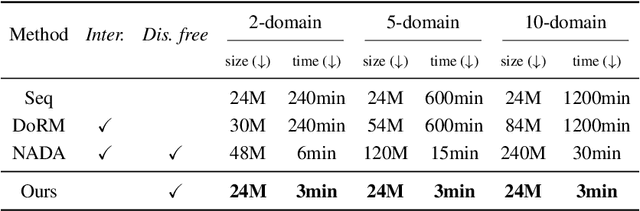
Can a pre-trained generator be adapted to the hybrid of multiple target domains and generate images with integrated attributes of them? In this work, we introduce a new task -- Few-shot Hybrid Domain Adaptation (HDA). Given a source generator and several target domains, HDA aims to acquire an adapted generator that preserves the integrated attributes of all target domains, without overriding the source domain's characteristics. Compared with Domain Adaptation (DA), HDA offers greater flexibility and versatility to adapt generators to more composite and expansive domains. Simultaneously, HDA also presents more challenges than DA as we have access only to images from individual target domains and lack authentic images from the hybrid domain. To address this issue, we introduce a discriminator-free framework that directly encodes different domains' images into well-separable subspaces. To achieve HDA, we propose a novel directional subspace loss comprised of a distance loss and a direction loss. Concretely, the distance loss blends the attributes of all target domains by reducing the distances from generated images to all target subspaces. The direction loss preserves the characteristics from the source domain by guiding the adaptation along the perpendicular to subspaces. Experiments show that our method can obtain numerous domain-specific attributes in a single adapted generator, which surpasses the baseline methods in semantic similarity, image fidelity, and cross-domain consistency.