 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyRPR: Training-Free Physics-Constrained Video Generation
Jan 14, 2026Recent diffusion-based video generation models can synthesize visually plausible videos, yet they often struggle to satisfy physical constraints. A key reason is that most existing approaches remain single-stage: they entangle high-level physical understanding with low-level visual synthesis, making it hard to generate content that require explicit physical reasoning. To address this limitation, we propose a training-free three-stage pipeline,\textit{PhyRPR}:\textit{Phy\uline{R}eason}--\textit{Phy\uline{P}lan}--\textit{Phy\uline{R}efine}, which decouples physical understanding from visual synthesis. Specifically, \textit{PhyReason} uses a large multimodal model for physical state reasoning and an image generator for keyframe synthesis; \textit{PhyPlan} deterministically synthesizes a controllable coarse motion scaffold; and \textit{PhyRefine} injects this scaffold into diffusion sampling via a latent fusion strategy to refine appearance while preserving the planned dynamics. This staged design enables explicit physical control during generation. Extensive experiments under physics constraints show that our method consistently improves physical plausibility and motion controllability.
ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
Jan 06, 2026Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization
Mar 16, 2025
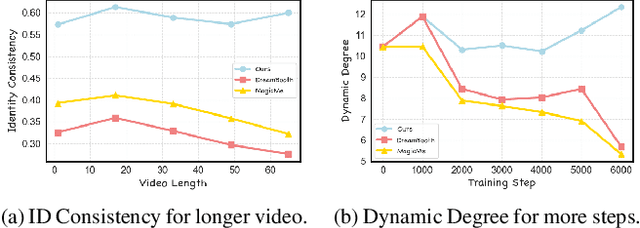

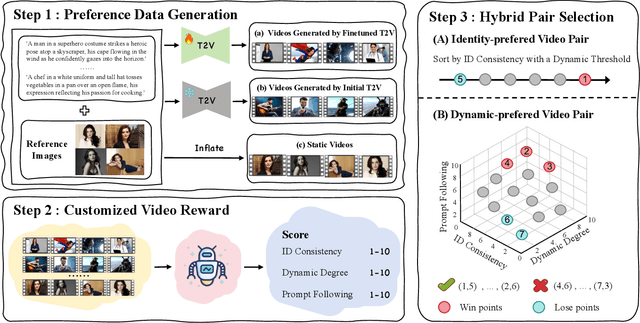
Video identity customization seeks to produce high-fidelity videos that maintain consistent identity and exhibit significant dynamics based on users' reference images. However, existing approaches face two key challenges: identity degradation over extended video length and reduced dynamics during training, primarily due to their reliance on traditional self-reconstruction training with static images. To address these issues, we introduce $\textbf{MagicID}$, a novel framework designed to directly promote the generation of identity-consistent and dynamically rich videos tailored to user preferences. Specifically, we propose constructing pairwise preference video data with explicit identity and dynamic rewards for preference learning, instead of sticking to the traditional self-reconstruction. To address the constraints of customized preference data, we introduce a hybrid sampling strategy. This approach first prioritizes identity preservation by leveraging static videos derived from reference images, then enhances dynamic motion quality in the generated videos using a Frontier-based sampling method. By utilizing these hybrid preference pairs, we optimize the model to align with the reward differences between pairs of customized preferences. Extensive experiments show that MagicID successfully achieves consistent identity and natural dynamics, surpassing existing methods across various metrics.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.
SAMRefiner: Taming Segment Anything Model for Universal Mask Refinement
Feb 10, 2025



In this paper, we explore a principal way to enhance the quality of widely pre-existing coarse masks, enabling them to serve as reliable training data for segmentation models to reduce the annotation cost. In contrast to prior refinement techniques that are tailored to specific models or tasks in a close-world manner, we propose SAMRefiner, a universal and efficient approach by adapting SAM to the mask refinement task. The core technique of our model is the noise-tolerant prompting scheme. Specifically, we introduce a multi-prompt excavation strategy to mine diverse input prompts for SAM (i.e., distance-guided points, context-aware elastic bounding boxes, and Gaussian-style masks) from initial coarse masks. These prompts can collaborate with each other to mitigate the effect of defects in coarse masks. In particular, considering the difficulty of SAM to handle the multi-object case in semantic segmentation, we introduce a split-then-merge (STM) pipeline. Additionally, we extend our method to SAMRefiner++ by introducing an additional IoU adaption step to further boost the performance of the generic SAMRefiner on the target dataset. This step is self-boosted and requires no additional annotation. The proposed framework is versatile and can flexibly cooperate with existing segmentation methods. We evaluate our mask framework on a wide range of benchmarks under different settings, demonstrating better accuracy and efficiency. SAMRefiner holds significant potential to expedite the evolution of refinement tools. Our code is available at https://github.com/linyq2117/SAMRefiner.
GCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024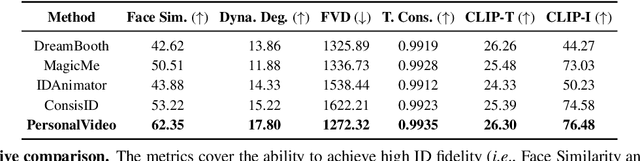
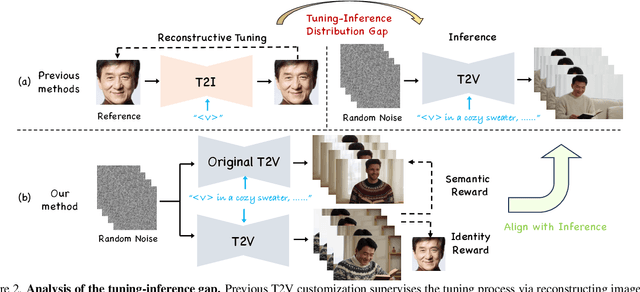
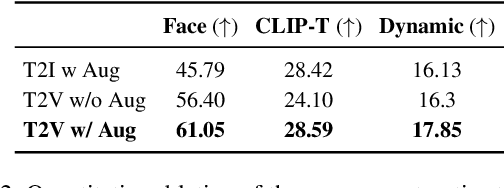
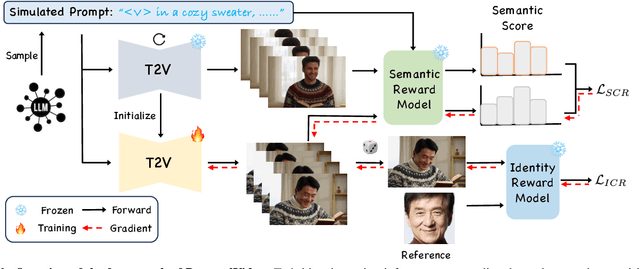
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.
Searching Priors Makes Text-to-Video Synthesis Better
Jun 05, 2024
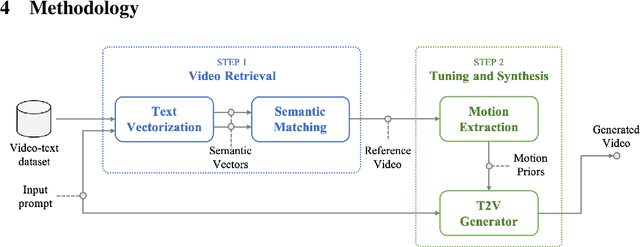


Significant advancements in video diffusion models have brought substantial progress to the field of text-to-video (T2V) synthesis. However, existing T2V synthesis model struggle to accurately generate complex motion dynamics, leading to a reduction in video realism. One possible solution is to collect massive data and train the model on it, but this would be extremely expensive. To alleviate this problem, in this paper, we reformulate the typical T2V generation process as a search-based generation pipeline. Instead of scaling up the model training, we employ existing videos as the motion prior database. Specifically, we divide T2V generation process into two steps: (i) For a given prompt input, we search existing text-video datasets to find videos with text labels that closely match the prompt motions. We propose a tailored search algorithm that emphasizes object motion features. (ii) Retrieved videos are processed and distilled into motion priors to fine-tune a pre-trained base T2V model, followed by generating desired videos using input prompt. By utilizing the priors gleaned from the searched videos, we enhance the realism of the generated videos' motion. All operations can be finished on a single NVIDIA RTX 4090 GPU. We validate our method against state-of-the-art T2V models across diverse prompt inputs. The code will be public.
Pseudo Label Refinery for Unsupervised Domain Adaptation on Cross-dataset 3D Object Detection
Apr 30, 2024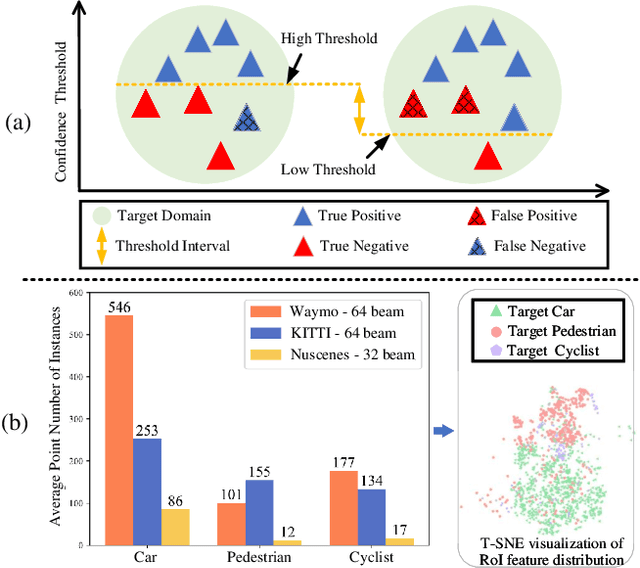
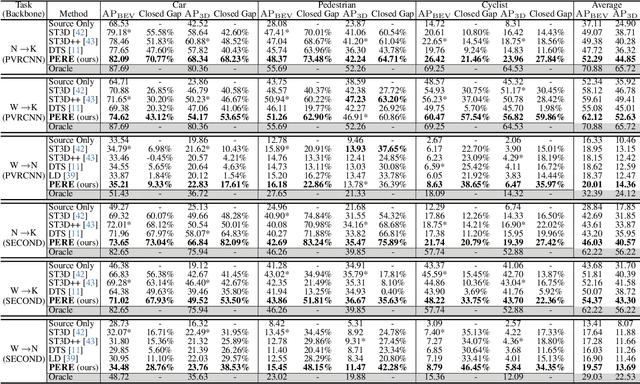
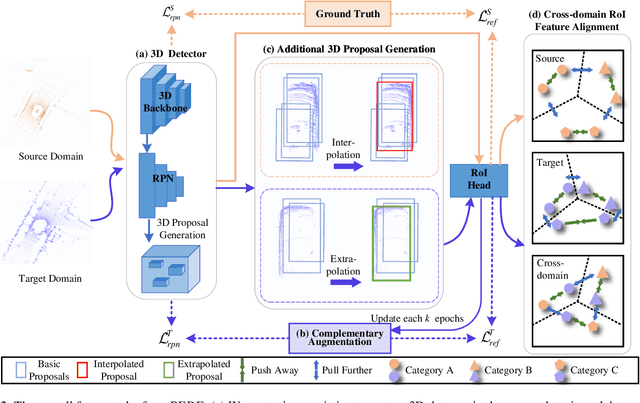
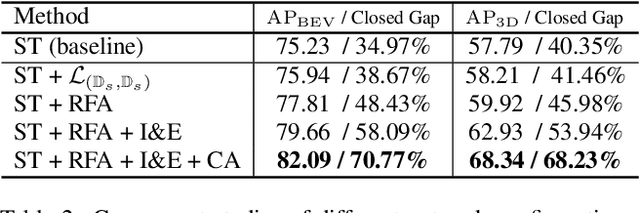
Recent self-training techniques have shown notable improvements in unsupervised domain adaptation for 3D object detection (3D UDA). These techniques typically select pseudo labels, i.e., 3D boxes, to supervise models for the target domain. However, this selection process inevitably introduces unreliable 3D boxes, in which 3D points cannot be definitively assigned as foreground or background. Previous techniques mitigate this by reweighting these boxes as pseudo labels, but these boxes can still poison the training process. To resolve this problem, in this paper, we propose a novel pseudo label refinery framework. Specifically, in the selection process, to improve the reliability of pseudo boxes, we propose a complementary augmentation strategy. This strategy involves either removing all points within an unreliable box or replacing it with a high-confidence box. Moreover, the point numbers of instances in high-beam datasets are considerably higher than those in low-beam datasets, also degrading the quality of pseudo labels during the training process. We alleviate this issue by generating additional proposals and aligning RoI features across different domains. Experimental results demonstrate that our method effectively enhances the quality of pseudo labels and consistently surpasses the state-of-the-art methods on six autonomous driving benchmarks. Code will be available at https://github.com/Zhanwei-Z/PERE.
LoRA-Composer: Leveraging Low-Rank Adaptation for Multi-Concept Customization in Training-Free Diffusion Models
Mar 18, 2024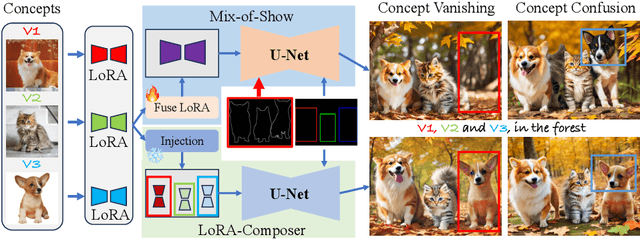
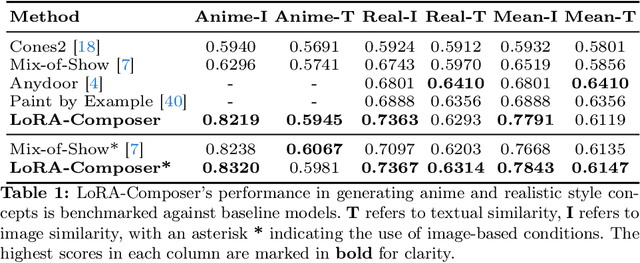
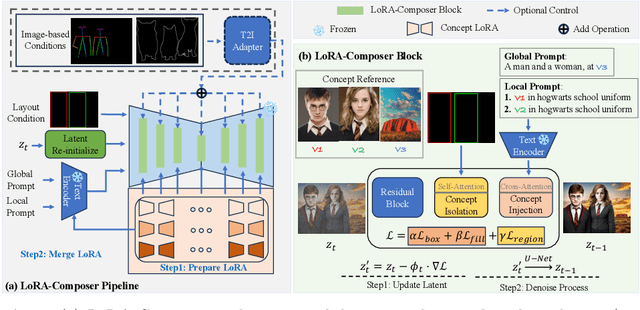
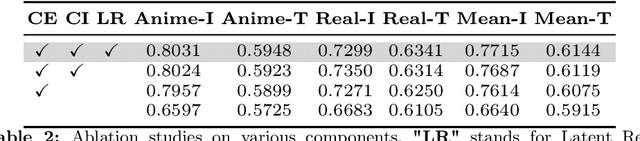
Customization generation techniques have significantly advanced the synthesis of specific concepts across varied contexts. Multi-concept customization emerges as the challenging task within this domain. Existing approaches often rely on training a Low-Rank Adaptations (LoRA) fusion matrix of multiple LoRA to merge various concepts into a single image. However, we identify this straightforward method faces two major challenges: 1) concept confusion, which occurs when the model cannot preserve distinct individual characteristics, and 2) concept vanishing, where the model fails to generate the intended subjects. To address these issues, we introduce LoRA-Composer, a training-free framework designed for seamlessly integrating multiple LoRAs, thereby enhancing the harmony among different concepts within generated images. LoRA-Composer addresses concept vanishing through Concept Injection Constraints, enhancing concept visibility via an expanded cross-attention mechanism. To combat concept confusion, Concept Isolation Constraints are introduced, refining the self-attention computation. Furthermore, Latent Re-initialization is proposed to effectively stimulate concept-specific latent within designated regions. Our extensive testing showcases a notable enhancement in LoRA-Composer's performance compared to standard baselines, especially when eliminating the image-based conditions like canny edge or pose estimations. Code is released at https://github.com/Young98CN/LoRA\_Composer.