 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Video-Avatar 1.5 Technical Report
May 26, 2026Despite advances in audio-driven video generation, achieving commercial-grade stability remains challenging. We present LongCat-Video-Avatar 1.5, an upgraded open-source framework prioritizing systematic engineering and production-readiness over architectural novelty. By upgrading the audio encoder to Whisper Large and meticulously scaling our training recipes, v1.5 achieves accurate lip-synchronization, full-body temporal stability, and robust long-video generation with strict identity consistency. Through rigorous data curation and RLHF Training, the model readily generalizes to stylized domains such as anime and animals, and natively handles complex real-world conditions, such as multi-person interactions and object handling. Furthermore, addressing the practical demands of industrial deployment, we employ advanced step distillation to accelerate inference to an optimal 8 NFE, achieving a favorable trade-off between serving efficiency and visual fidelity. The superiority of our approach is validated through extensive quantitative metrics and a rigorous human evaluation conducted on a comprehensive benchmark of over 500 diverse test cases. Results show that v1.5 achieves competitive or superior performance compared to leading closed-source systems (e.g., HeyGen, OmniHuman 1.5, Kling Avatar 2.0) across human-likeness ratings and expert-level quality assessments on our benchmark. With its open-source release, LongCat-Video-Avatar 1.5 narrows the gap between academic research prototypes and commercial-grade deployment.
Bridging Brain and Semantics: A Hierarchical Framework for Semantically Enhanced fMRI-to-Video Reconstruction
May 14, 2026Reconstructing dynamic visual experiences as videos from functional magnetic resonance imaging (fMRI) is pivotal for advancing the understanding of neural processes. However, current fMRI-to-video reconstruction methods are hindered by a semantic gap between noisy fMRI signals and the rich content of videos, stemming from a reliance on incomplete semantic embeddings that neither capture video-specific cues (e.g., actions) nor integrate prior knowledge. To this end, we draw inspiration from the dual-pathway processing mechanism in human brain and introduce CineNeuron, a novel hierarchical framework for semantically enhanced video reconstruction from fMRI signals with two synergistic stages. First, a bottom-up semantic enrichment stage maps fMRI signals to a rich embedding space that comprehensively captures textual semantics, image contents, action concepts, and object categories. Second, a top-down memory integration stage utilizes the proposed Mixture-of-Memories method to dynamically select relevant "memories" from previously seen data and fuse them with the fMRI embedding to refine the video reconstruction. Extensive experimental results on two fMRI-to-video benchmarks demonstrate that CineNeuron surpasses state-of-the-art methods across various metrics.
ZSG-IAD: A Multimodal Framework for Zero-Shot Grounded Industrial Anomaly Detection
Apr 20, 2026Deep learning-based industrial anomaly detectors often behave as black boxes, making it hard to justify decisions with physically meaningful defect evidence. We propose ZSG-IAD, a multimodal vision-language framework for zero-shot grounded industrial anomaly detection. Given RGB images, sensor images, and 3D point clouds, ZSG-IAD generates structured anomaly reports and pixel-level anomaly masks. ZSG-IAD introduces a language-guided two-hop grounding module: (1) anomaly-related sentences select evidence-like latent slots distilled from multimodal features, yielding coarse spatial support; (2) selected slots modulate feature maps via channel-spatial gating and a lightweight decoder to produce fine-grained masks. To improve reliability, we further apply Executable-Rule GRPO with verifiable rewards to promote structured outputs, anomaly-region consistency, and reasoning-conclusion coherence. Experiments across multiple industrial anomaly benchmarks show strong zero-shot performance and more transparent, physically grounded explanations than prior methods. We will release code and annotations to support future research on trustworthy industrial anomaly detection systems.
PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
Jan 16, 2026Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.
CoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
Jan 16, 2026Character image animation is gaining significant importance across various domains, driven by the demand for robust and flexible multi-subject rendering. While existing methods excel in single-person animation, they struggle to handle arbitrary subject counts, diverse character types, and spatial misalignment between the reference image and the driving poses. We attribute these limitations to an overly rigid spatial binding that forces strict pixel-wise alignment between the pose and reference, and an inability to consistently rebind motion to intended subjects. To address these challenges, we propose CoDance, a novel Unbind-Rebind framework that enables the animation of arbitrary subject counts, types, and spatial configurations conditioned on a single, potentially misaligned pose sequence. Specifically, the Unbind module employs a novel pose shift encoder to break the rigid spatial binding between the pose and the reference by introducing stochastic perturbations to both poses and their latent features, thereby compelling the model to learn a location-agnostic motion representation. To ensure precise control and subject association, we then devise a Rebind module, leveraging semantic guidance from text prompts and spatial guidance from subject masks to direct the learned motion to intended characters. Furthermore, to facilitate comprehensive evaluation, we introduce a new multi-subject CoDanceBench. Extensive experiments on CoDanceBench and existing datasets show that CoDance achieves SOTA performance, exhibiting remarkable generalization across diverse subjects and spatial layouts. The code and weights will be open-sourced.
ESGaussianFace: Emotional and Stylized Audio-Driven Facial Animation via 3D Gaussian Splatting
Jan 05, 2026Most current audio-driven facial animation research primarily focuses on generating videos with neutral emotions. While some studies have addressed the generation of facial videos driven by emotional audio, efficiently generating high-quality talking head videos that integrate both emotional expressions and style features remains a significant challenge. In this paper, we propose ESGaussianFace, an innovative framework for emotional and stylized audio-driven facial animation. Our approach leverages 3D Gaussian Splatting to reconstruct 3D scenes and render videos, ensuring efficient generation of 3D consistent results. We propose an emotion-audio-guided spatial attention method that effectively integrates emotion features with audio content features. Through emotion-guided attention, the model is able to reconstruct facial details across different emotional states more accurately. To achieve emotional and stylized deformations of the 3D Gaussian points through emotion and style features, we introduce two 3D Gaussian deformation predictors. Futhermore, we propose a multi-stage training strategy, enabling the step-by-step learning of the character's lip movements, emotional variations, and style features. Our generated results exhibit high efficiency, high quality, and 3D consistency. Extensive experimental results demonstrate that our method outperforms existing state-of-the-art techniques in terms of lip movement accuracy, expression variation, and style feature expressiveness.
Phys-Liquid: A Physics-Informed Dataset for Estimating 3D Geometry and Volume of Transparent Deformable Liquids
Nov 14, 2025
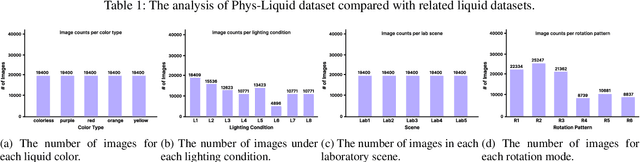
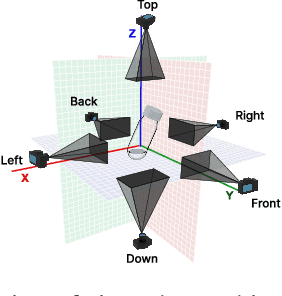

Estimating the geometric and volumetric properties of transparent deformable liquids is challenging due to optical complexities and dynamic surface deformations induced by container movements. Autonomous robots performing precise liquid manipulation tasks, such as dispensing, aspiration, and mixing, must handle containers in ways that inevitably induce these deformations, complicating accurate liquid state assessment. Current datasets lack comprehensive physics-informed simulation data representing realistic liquid behaviors under diverse dynamic scenarios. To bridge this gap, we introduce Phys-Liquid, a physics-informed dataset comprising 97,200 simulation images and corresponding 3D meshes, capturing liquid dynamics across multiple laboratory scenes, lighting conditions, liquid colors, and container rotations. To validate the realism and effectiveness of Phys-Liquid, we propose a four-stage reconstruction and estimation pipeline involving liquid segmentation, multi-view mask generation, 3D mesh reconstruction, and real-world scaling. Experimental results demonstrate improved accuracy and consistency in reconstructing liquid geometry and volume, outperforming existing benchmarks. The dataset and associated validation methods facilitate future advancements in transparent liquid perception tasks. The dataset and code are available at https://dualtransparency.github.io/Phys-Liquid/.
FixTalk: Taming Identity Leakage for High-Quality Talking Head Generation in Extreme Cases
Jul 02, 2025Talking head generation is gaining significant importance across various domains, with a growing demand for high-quality rendering. However, existing methods often suffer from identity leakage (IL) and rendering artifacts (RA), particularly in extreme cases. Through an in-depth analysis of previous approaches, we identify two key insights: (1) IL arises from identity information embedded within motion features, and (2) this identity information can be leveraged to address RA. Building on these findings, this paper introduces FixTalk, a novel framework designed to simultaneously resolve both issues for high-quality talking head generation. Firstly, we propose an Enhanced Motion Indicator (EMI) to effectively decouple identity information from motion features, mitigating the impact of IL on generated talking heads. To address RA, we introduce an Enhanced Detail Indicator (EDI), which utilizes the leaked identity information to supplement missing details, thus fixing the artifacts. Extensive experiments demonstrate that FixTalk effectively mitigates IL and RA, achieving superior performance compared to state-of-the-art methods.
MambaControl: Anatomy Graph-Enhanced Mamba ControlNet with Fourier Refinement for Diffusion-Based Disease Trajectory Prediction
May 15, 2025Modelling disease progression in precision medicine requires capturing complex spatio-temporal dynamics while preserving anatomical integrity. Existing methods often struggle with longitudinal dependencies and structural consistency in progressive disorders. To address these limitations, we introduce MambaControl, a novel framework that integrates selective state-space modelling with diffusion processes for high-fidelity prediction of medical image trajectories. To better capture subtle structural changes over time while maintaining anatomical consistency, MambaControl combines Mamba-based long-range modelling with graph-guided anatomical control to more effectively represent anatomical correlations. Furthermore, we introduce Fourier-enhanced spectral graph representations to capture spatial coherence and multiscale detail, enabling MambaControl to achieve state-of-the-art performance in Alzheimer's disease prediction. Quantitative and regional evaluations demonstrate improved progression prediction quality and anatomical fidelity, highlighting its potential for personalised prognosis and clinical decision support.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.