 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaControl: Anatomy Graph-Enhanced Mamba ControlNet with Fourier Refinement for Diffusion-Based Disease Trajectory Prediction
May 15, 2025Modelling disease progression in precision medicine requires capturing complex spatio-temporal dynamics while preserving anatomical integrity. Existing methods often struggle with longitudinal dependencies and structural consistency in progressive disorders. To address these limitations, we introduce MambaControl, a novel framework that integrates selective state-space modelling with diffusion processes for high-fidelity prediction of medical image trajectories. To better capture subtle structural changes over time while maintaining anatomical consistency, MambaControl combines Mamba-based long-range modelling with graph-guided anatomical control to more effectively represent anatomical correlations. Furthermore, we introduce Fourier-enhanced spectral graph representations to capture spatial coherence and multiscale detail, enabling MambaControl to achieve state-of-the-art performance in Alzheimer's disease prediction. Quantitative and regional evaluations demonstrate improved progression prediction quality and anatomical fidelity, highlighting its potential for personalised prognosis and clinical decision support.
Aurora:Activating Chinese chat capability for Mixtral-8x7B sparse Mixture-of-Experts through Instruction-Tuning
Jan 01, 2024
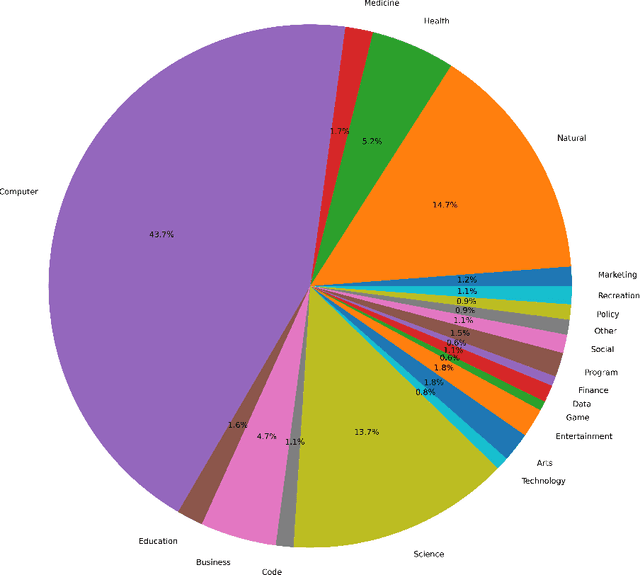

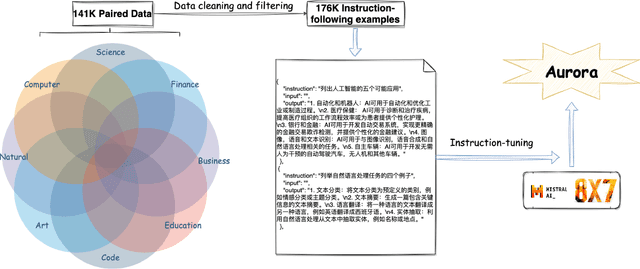
Existing research has demonstrated that refining large language models (LLMs) through the utilization of machine-generated instruction-following data empowers these models to exhibit impressive zero-shot capabilities for novel tasks, without requiring human-authored instructions. In this paper, we systematically investigate, preprocess, and integrate three Chinese instruction-following datasets with the aim of enhancing the Chinese conversational capabilities of Mixtral-8x7B sparse Mixture-of-Experts model. Through instruction fine-tuning on this carefully processed dataset, we successfully construct the Mixtral-8x7B sparse Mixture-of-Experts model named "Aurora." To assess the performance of Aurora, we utilize three widely recognized benchmark tests: C-Eval, MMLU, and CMMLU. Empirical studies validate the effectiveness of instruction fine-tuning applied to Mixtral-8x7B sparse Mixture-of-Experts model. This work is pioneering in the execution of instruction fine-tuning on a sparse expert-mixed model, marking a significant breakthrough in enhancing the capabilities of this model architecture. Our code, data and model are publicly available at https://github.com/WangRongsheng/Aurora
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.