 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels Under SCOPE: Scalable and Controllable Routing via Pre-hoc Reasoning
Jan 29, 2026Model routing chooses which language model to use for each query. By sending easy queries to cheaper models and hard queries to stronger ones, it can significantly reduce inference cost while maintaining high accuracy. However, most existing routers treat this as a fixed choice among a small set of models, which makes them hard to adapt to new models or changing budget constraints. In this paper, we propose SCOPE (Scalable and Controllable Outcome Performance Estimator), a routing framework that goes beyond model selection by predicting their cost and performance. Trained with reinforcement learning, SCOPE makes reasoning-based predictions by retrieving how models behave on similar problems, rather than relying on fixed model names, enabling it to work with new, unseen models. Moreover, by explicitly predicting how accurate and how expensive a model will be, it turns routing into a dynamic decision problem, allowing users to easily control the trade-off between accuracy and cost. Experiments show that SCOPE is more than just a cost-saving tool. It flexibly adapts to user needs: it can boost accuracy by up to 25.7% when performance is the priority, or cut costs by up to 95.1% when efficiency matters most.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025
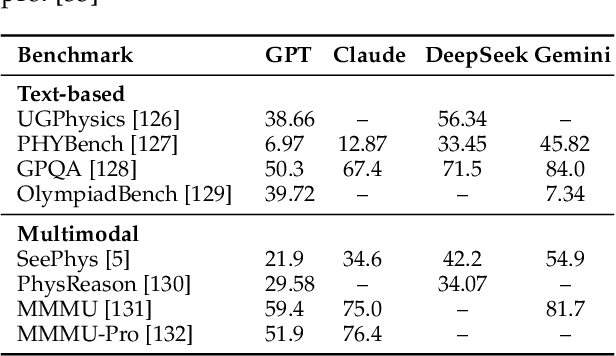

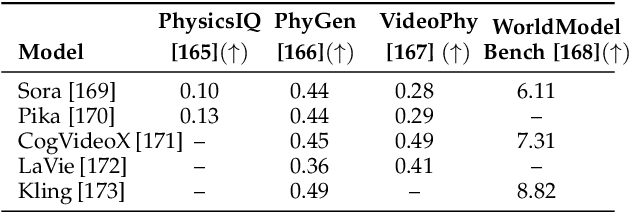
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
LLM-Detector: Improving AI-Generated Chinese Text Detection with Open-Source LLM Instruction Tuning
Feb 02, 2024ChatGPT and other general large language models (LLMs) have achieved remarkable success, but they have also raised concerns about the misuse of AI-generated texts. Existing AI-generated text detection models, such as based on BERT and RoBERTa, are prone to in-domain over-fitting, leading to poor out-of-domain (OOD) detection performance. In this paper, we first collected Chinese text responses generated by human experts and 9 types of LLMs, for which to multiple domains questions, and further created a dataset that mixed human-written sentences and sentences polished by LLMs. We then proposed LLM-Detector, a novel method for both document-level and sentence-level text detection through Instruction Tuning of LLMs. Our method leverages the wealth of knowledge LLMs acquire during pre-training, enabling them to detect the text they generate. Instruction tuning aligns the model's responses with the user's expected text detection tasks. Experimental results show that previous methods struggle with sentence-level AI-generated text detection and OOD detection. In contrast, our proposed method not only significantly outperforms baseline methods in both sentence-level and document-level text detection but also demonstrates strong generalization capabilities. Furthermore, since LLM-Detector is trained based on open-source LLMs, it is easy to customize for deployment.
Aurora:Activating Chinese chat capability for Mixtral-8x7B sparse Mixture-of-Experts through Instruction-Tuning
Jan 01, 2024
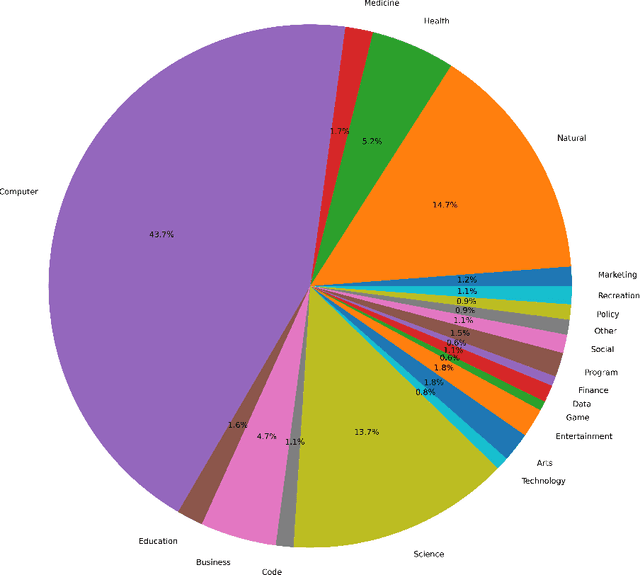

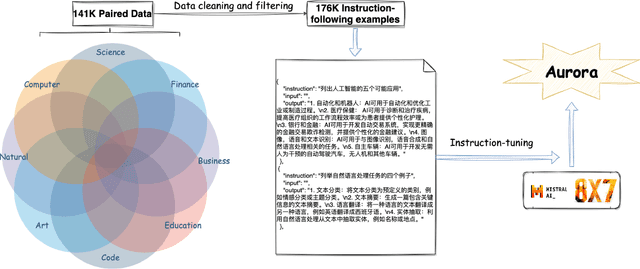
Existing research has demonstrated that refining large language models (LLMs) through the utilization of machine-generated instruction-following data empowers these models to exhibit impressive zero-shot capabilities for novel tasks, without requiring human-authored instructions. In this paper, we systematically investigate, preprocess, and integrate three Chinese instruction-following datasets with the aim of enhancing the Chinese conversational capabilities of Mixtral-8x7B sparse Mixture-of-Experts model. Through instruction fine-tuning on this carefully processed dataset, we successfully construct the Mixtral-8x7B sparse Mixture-of-Experts model named "Aurora." To assess the performance of Aurora, we utilize three widely recognized benchmark tests: C-Eval, MMLU, and CMMLU. Empirical studies validate the effectiveness of instruction fine-tuning applied to Mixtral-8x7B sparse Mixture-of-Experts model. This work is pioneering in the execution of instruction fine-tuning on a sparse expert-mixed model, marking a significant breakthrough in enhancing the capabilities of this model architecture. Our code, data and model are publicly available at https://github.com/WangRongsheng/Aurora