 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNortheastern Uni at Multilingual Counterspeech Generation: Enhancing Counter Speech Generation with LLM Alignment through Direct Preference Optimization
Dec 19, 2024



The automatic generation of counter-speech (CS) is a critical strategy for addressing hate speech by providing constructive and informed responses. However, existing methods often fail to generate high-quality, impactful, and scalable CS, particularly across diverse linguistic contexts. In this paper, we propose a novel methodology to enhance CS generation by aligning Large Language Models (LLMs) using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). Our approach leverages DPO to align LLM outputs with human preferences, ensuring contextually appropriate and linguistically adaptable responses. Additionally, we incorporate knowledge grounding to enhance the factual accuracy and relevance of generated CS. Experimental results demonstrate that DPO-aligned models significantly outperform SFT baselines on CS benchmarks while scaling effectively to multiple languages. These findings highlight the potential of preference-based alignment techniques to advance CS generation across varied linguistic settings. The model supervision and alignment is done in English and the same model is used for reporting metrics across other languages like Basque, Italian, and Spanish.
* 10 pages, 6 tables, 1 figure, The First Workshop on Multilingual Counterspeech Generation (MCG) at The 31st International Conference on Computational Linguistics (COLING 2025)
Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
May 12, 2024



An effective pre-training framework with universal 3D representations is extremely desired in perceiving large-scale dynamic scenes. However, establishing such an ideal framework that is both task-generic and label-efficient poses a challenge in unifying the representation of the same primitive across diverse scenes. The current contrastive 3D pre-training methods typically follow a frame-level consistency, which focuses on the 2D-3D relationships in each detached image. Such inconsiderate consistency greatly hampers the promising path of reaching an universal pre-training framework: (1) The cross-scene semantic self-conflict, i.e., the intense collision between primitive segments of the same semantics from different scenes; (2) Lacking a globally unified bond that pushes the cross-scene semantic consistency into 3D representation learning. To address above challenges, we propose a CSC framework that puts a scene-level semantic consistency in the heart, bridging the connection of the similar semantic segments across various scenes. To achieve this goal, we combine the coherent semantic cues provided by the vision foundation model and the knowledge-rich cross-scene prototypes derived from the complementary multi-modality information. These allow us to train a universal 3D pre-training model that facilitates various downstream tasks with less fine-tuning efforts. Empirically, we achieve consistent improvements over SOTA pre-training approaches in semantic segmentation (+1.4% mIoU), object detection (+1.0% mAP), and panoptic segmentation (+3.0% PQ) using their task-specific 3D network on nuScenes. Code is released at https://github.com/chenhaomingbob/CSC, hoping to inspire future research.
LLM-Detector: Improving AI-Generated Chinese Text Detection with Open-Source LLM Instruction Tuning
Feb 02, 2024ChatGPT and other general large language models (LLMs) have achieved remarkable success, but they have also raised concerns about the misuse of AI-generated texts. Existing AI-generated text detection models, such as based on BERT and RoBERTa, are prone to in-domain over-fitting, leading to poor out-of-domain (OOD) detection performance. In this paper, we first collected Chinese text responses generated by human experts and 9 types of LLMs, for which to multiple domains questions, and further created a dataset that mixed human-written sentences and sentences polished by LLMs. We then proposed LLM-Detector, a novel method for both document-level and sentence-level text detection through Instruction Tuning of LLMs. Our method leverages the wealth of knowledge LLMs acquire during pre-training, enabling them to detect the text they generate. Instruction tuning aligns the model's responses with the user's expected text detection tasks. Experimental results show that previous methods struggle with sentence-level AI-generated text detection and OOD detection. In contrast, our proposed method not only significantly outperforms baseline methods in both sentence-level and document-level text detection but also demonstrates strong generalization capabilities. Furthermore, since LLM-Detector is trained based on open-source LLMs, it is easy to customize for deployment.
Aurora:Activating Chinese chat capability for Mixtral-8x7B sparse Mixture-of-Experts through Instruction-Tuning
Jan 01, 2024
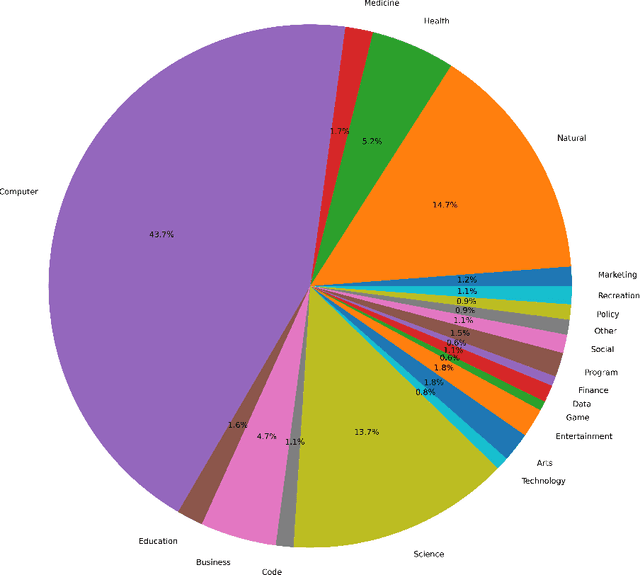

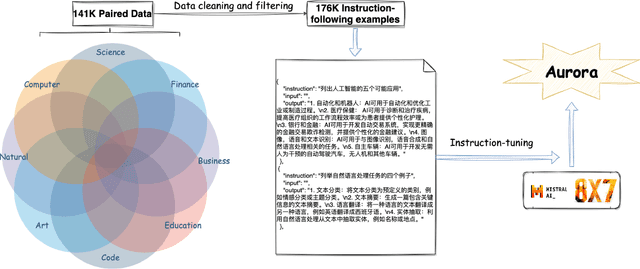
Existing research has demonstrated that refining large language models (LLMs) through the utilization of machine-generated instruction-following data empowers these models to exhibit impressive zero-shot capabilities for novel tasks, without requiring human-authored instructions. In this paper, we systematically investigate, preprocess, and integrate three Chinese instruction-following datasets with the aim of enhancing the Chinese conversational capabilities of Mixtral-8x7B sparse Mixture-of-Experts model. Through instruction fine-tuning on this carefully processed dataset, we successfully construct the Mixtral-8x7B sparse Mixture-of-Experts model named "Aurora." To assess the performance of Aurora, we utilize three widely recognized benchmark tests: C-Eval, MMLU, and CMMLU. Empirical studies validate the effectiveness of instruction fine-tuning applied to Mixtral-8x7B sparse Mixture-of-Experts model. This work is pioneering in the execution of instruction fine-tuning on a sparse expert-mixed model, marking a significant breakthrough in enhancing the capabilities of this model architecture. Our code, data and model are publicly available at https://github.com/WangRongsheng/Aurora
Evaluation of dynamic characteristics of power grid based on GNN and application on knowledge graph
Nov 28, 2023
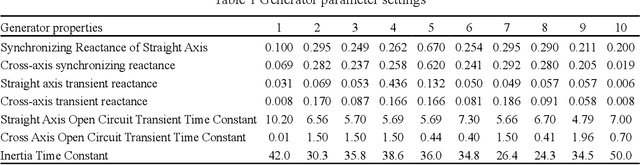
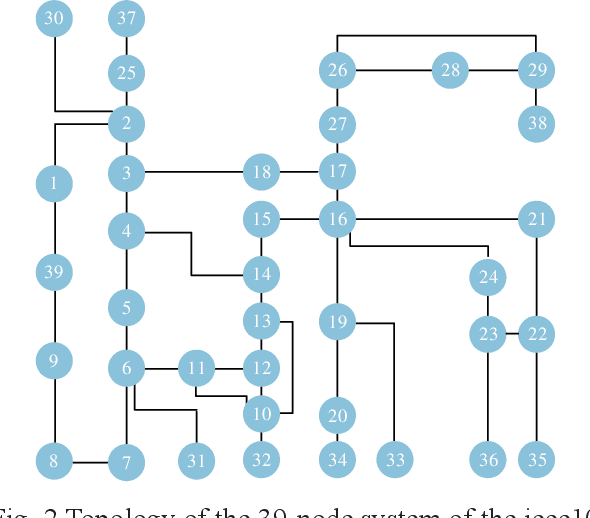

A novel method for detecting faults in power grids using a graph neural network (GNN) has been developed, aimed at enhancing intelligent fault diagnosis in network operation and maintenance. This GNN-based approach identifies faulty nodes within the power grid through a specialized electrical feature extraction model coupled with a knowledge graph. Incorporating temporal data, the method leverages the status of nodes from preceding and subsequent time periods to aid in current fault detection. To validate the effectiveness of this GNN in extracting node features, a correlation analysis of the output features from each node within the neural network layer was conducted. The results from experiments show that this method can accurately locate fault nodes in simulated scenarios with a remarkable 99.53% accuracy. Additionally, the graph neural network's feature modeling allows for a qualitative examination of how faults spread across nodes, providing valuable insights for analyzing fault nodes.
IvyGPT: InteractiVe Chinese pathwaY language model in medical domain
Jul 20, 2023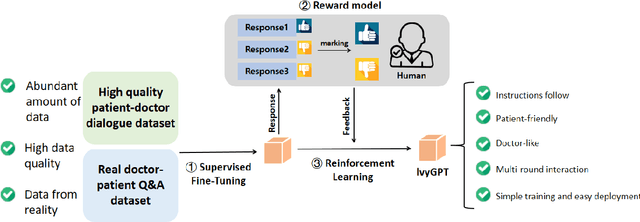
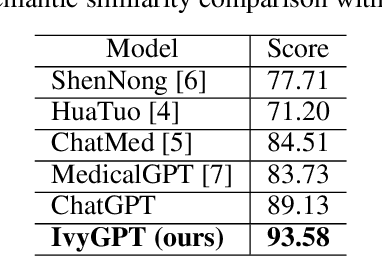
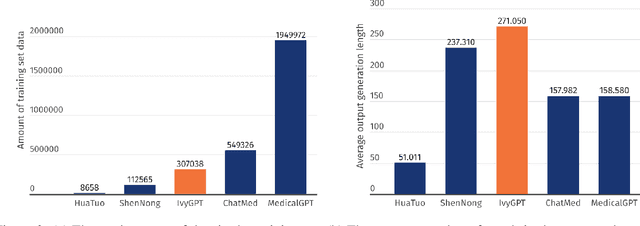
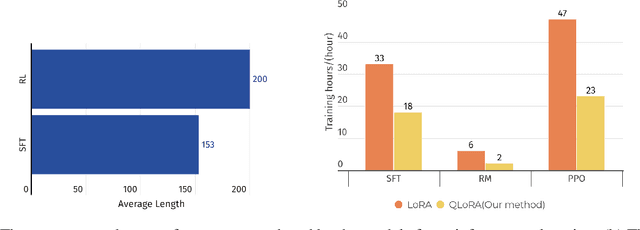
General large language models (LLMs) such as ChatGPT have shown remarkable success. However, such LLMs have not been widely adopted for medical purposes, due to poor accuracy and inability to provide medical advice. We propose IvyGPT, an LLM based on LLaMA that is trained and fine-tuned with high-quality medical question-answer (QA) instances and Reinforcement Learning from Human Feedback (RLHF). After supervised fine-tuning, IvyGPT has good multi-turn conversation capabilities, but it cannot perform like a doctor in other aspects, such as comprehensive diagnosis. Through RLHF, IvyGPT can output richer diagnosis and treatment answers that are closer to human. In the training, we used QLoRA to train 33 billion parameters on a small number of NVIDIA A100 (80GB) GPUs. Experimental results show that IvyGPT has outperformed other medical GPT models.
sMRI-PatchNet: A novel explainable patch-based deep learning network for Alzheimer's disease diagnosis and discriminative atrophy localisation with Structural MRI
Feb 20, 2023



Structural magnetic resonance imaging (sMRI) can identify subtle brain changes due to its high contrast for soft tissues and high spatial resolution. It has been widely used in diagnosing neurological brain diseases, such as Alzheimer disease (AD). However, the size of 3D high-resolution data poses a significant challenge for data analysis and processing. Since only a few areas of the brain show structural changes highly associated with AD, the patch-based methods dividing the whole image data into several small regular patches have shown promising for more efficient sMRI-based image analysis. The major challenges of the patch-based methods on sMRI include identifying the discriminative patches, combining features from the discrete discriminative patches, and designing appropriate classifiers. This work proposes a novel patch-based deep learning network (sMRI-PatchNet) with explainable patch localisation and selection for AD diagnosis using sMRI. Specifically, it consists of two primary components: 1) A fast and efficient explainable patch selection mechanism for determining the most discriminative patches based on computing the SHapley Additive exPlanations (SHAP) contribution to a transfer learning model for AD diagnosis on massive medical data; and 2) A novel patch-based network for extracting deep features and AD classfication from the selected patches with position embeddings to retain position information, capable of capturing the global and local information of inter- and intra-patches. This method has been applied for the AD classification and the prediction of the transitional state moderate cognitive impairment (MCI) conversion with real datasets.
Layer-Wise Partitioning and Merging for Efficient and Scalable Deep Learning
Jul 22, 2022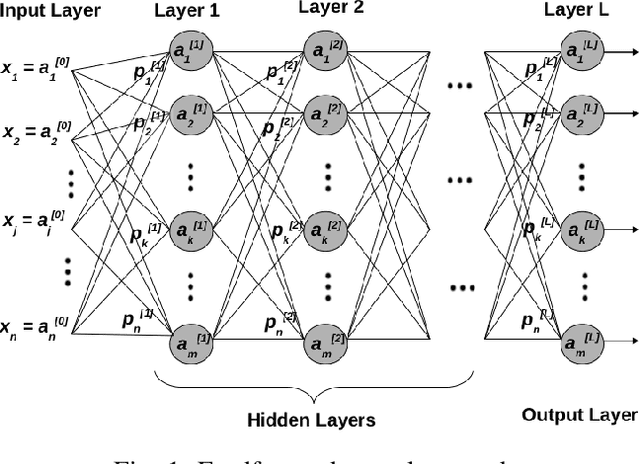
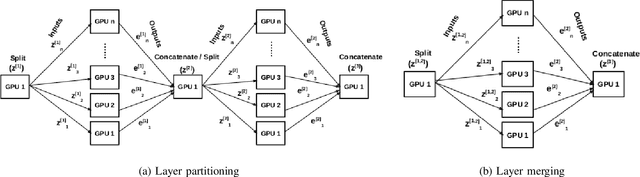

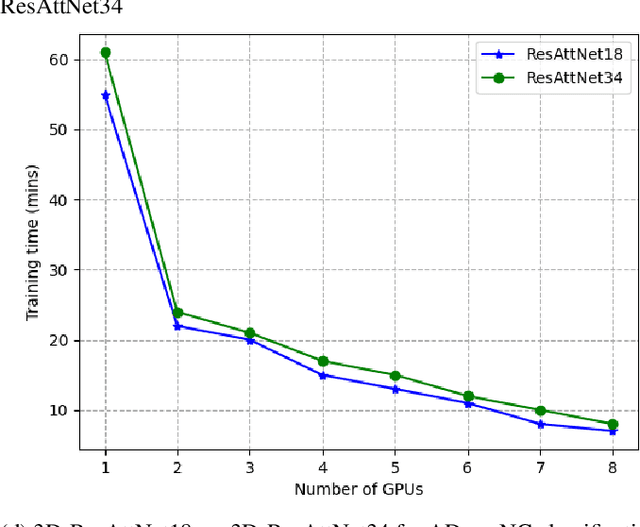
Deep Neural Network (DNN) models are usually trained sequentially from one layer to another, which causes forward, backward and update locking's problems, leading to poor performance in terms of training time. The existing parallel strategies to mitigate these problems provide suboptimal runtime performance. In this work, we have proposed a novel layer-wise partitioning and merging, forward and backward pass parallel framework to provide better training performance. The novelty of the proposed work consists of 1) a layer-wise partition and merging model which can minimise communication overhead between devices without the memory cost of existing strategies during the training process; 2) a forward pass and backward pass parallelisation and optimisation to address the update locking problem and minimise the total training cost. The experimental evaluation on real use cases shows that the proposed method outperforms the state-of-the-art approaches in terms of training speed; and achieves almost linear speedup without compromising the accuracy performance of the non-parallel approach.
2D Human Pose Estimation: A Survey
Apr 15, 2022
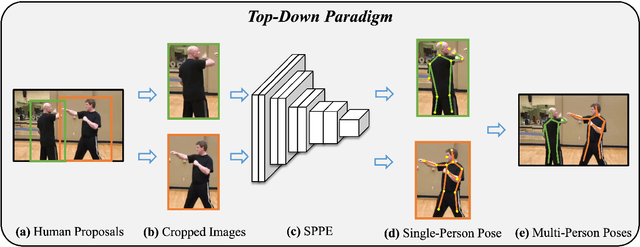
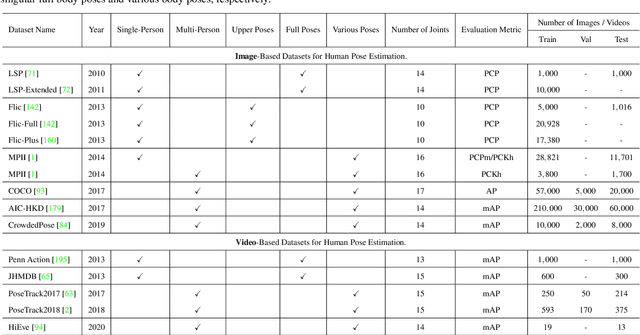
Human pose estimation aims at localizing human anatomical keypoints or body parts in the input data (e.g., images, videos, or signals). It forms a crucial component in enabling machines to have an insightful understanding of the behaviors of humans, and has become a salient problem in computer vision and related fields. Deep learning techniques allow learning feature representations directly from the data, significantly pushing the performance boundary of human pose estimation. In this paper, we reap the recent achievements of 2D human pose estimation methods and present a comprehensive survey. Briefly, existing approaches put their efforts in three directions, namely network architecture design, network training refinement, and post processing. Network architecture design looks at the architecture of human pose estimation models, extracting more robust features for keypoint recognition and localization. Network training refinement tap into the training of neural networks and aims to improve the representational ability of models. Post processing further incorporates model-agnostic polishing strategies to improve the performance of keypoint detection. More than 200 research contributions are involved in this survey, covering methodological frameworks, common benchmark datasets, evaluation metrics, and performance comparisons. We seek to provide researchers with a more comprehensive and systematic review on human pose estimation, allowing them to acquire a grand panorama and better identify future directions.
Temporal Feature Alignment and Mutual Information Maximization for Video-Based Human Pose Estimation
Apr 03, 2022
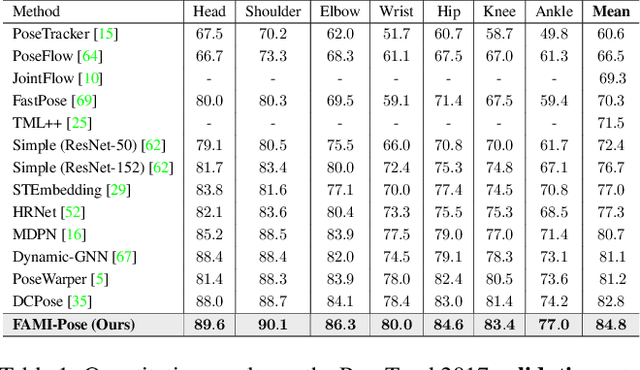
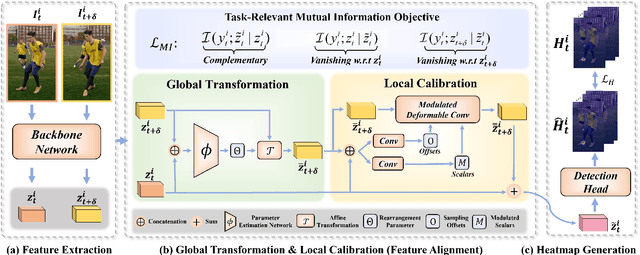
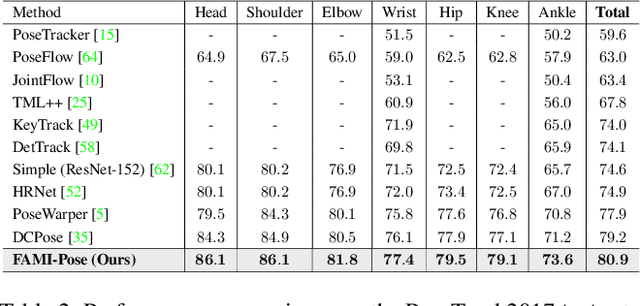
Multi-frame human pose estimation has long been a compelling and fundamental problem in computer vision. This task is challenging due to fast motion and pose occlusion that frequently occur in videos. State-of-the-art methods strive to incorporate additional visual evidences from neighboring frames (supporting frames) to facilitate the pose estimation of the current frame (key frame). One aspect that has been obviated so far, is the fact that current methods directly aggregate unaligned contexts across frames. The spatial-misalignment between pose features of the current frame and neighboring frames might lead to unsatisfactory results. More importantly, existing approaches build upon the straightforward pose estimation loss, which unfortunately cannot constrain the network to fully leverage useful information from neighboring frames. To tackle these problems, we present a novel hierarchical alignment framework, which leverages coarse-to-fine deformations to progressively update a neighboring frame to align with the current frame at the feature level. We further propose to explicitly supervise the knowledge extraction from neighboring frames, guaranteeing that useful complementary cues are extracted. To achieve this goal, we theoretically analyzed the mutual information between the frames and arrived at a loss that maximizes the task-relevant mutual information. These allow us to rank No.1 in the Multi-frame Person Pose Estimation Challenge on benchmark dataset PoseTrack2017, and obtain state-of-the-art performance on benchmarks Sub-JHMDB and Pose-Track2018. Our code is released at https://github. com/Pose-Group/FAMI-Pose, hoping that it will be useful to the community.