 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA WDLoRA-Based Multimodal Generative Framework for Clinically Guided Corneal Confocal Microscopy Image Synthesis in Diabetic Neuropathy
Feb 14, 2026Corneal Confocal Microscopy (CCM) is a sensitive tool for assessing small-fiber damage in Diabetic Peripheral Neuropathy (DPN), yet the development of robust, automated deep learning-based diagnostic models is limited by scarce labelled data and fine-grained variability in corneal nerve morphology. Although Artificial Intelligence (AI)-driven foundation generative models excel at natural image synthesis, they often struggle in medical imaging due to limited domain-specific training, compromising the anatomical fidelity required for clinical analysis. To overcome these limitations, we propose a Weight-Decomposed Low-Rank Adaptation (WDLoRA)-based multimodal generative framework for clinically guided CCM image synthesis. WDLoRA is a parameter-efficient fine-tuning (PEFT) mechanism that decouples magnitude and directional weight updates, enabling foundation generative models to independently learn the orientation (nerve topology) and intensity (stromal contrast) required for medical realism. By jointly conditioning on nerve segmentation masks and disease-specific clinical prompts, the model synthesises anatomically coherent images across the DPN spectrum (Control, T1NoDPN, T1DPN). A comprehensive three-pillar evaluation demonstrates that the proposed framework achieves state-of-the-art visual fidelity (Fréchet Inception Distance (FID): 5.18) and structural integrity (Structural Similarity Index Measure (SSIM): 0.630), significantly outperforming GAN and standard diffusion baselines. Crucially, the synthetic images preserve gold-standard clinical biomarkers and are statistically equivalent to real patient data. When used to train automated diagnostic models, the synthetic dataset improves downstream diagnostic accuracy by 2.1% and segmentation performance by 2.2%, validating the framework's potential to alleviate data bottlenecks in medical AI.
AgriPINN: A Process-Informed Neural Network for Interpretable and Scalable Crop Biomass Prediction Under Water Stress
Jan 22, 2026Accurate prediction of crop above-ground biomass (AGB) under water stress is critical for monitoring crop productivity, guiding irrigation, and supporting climate-resilient agriculture. Data-driven models scale well but often lack interpretability and degrade under distribution shift, whereas process-based crop models (e.g. DSSAT, APSIM, LINTUL5) require extensive calibration and are difficult to deploy over large spatial domains. To address these limitations, we propose AgriPINN, a process-informed neural network that integrates a biophysical crop-growth differential equation as a differentiable constraint within a deep learning backbone. This design encourages physiologically consistent biomass dynamics under water-stress conditions while preserving model scalability for spatially distributed AGB prediction. AgriPINN recovers latent physiological variables, including leaf area index (LAI), absorbed photosynthetically active radiation (PAR), radiation use efficiency (RUE), and water-stress factors, without requiring direct supervision. We pretrain AgriPINN on 60 years of historical data across 397 regions in Germany and fine-tune it on three years of field experiments under controlled water treatments. Results show that AgriPINN consistently outperforms state-of-the-art deep-learning baselines (ConvLSTM-ViT, SLTF, CNN-Transformer) and the process-based LINTUL5 model in terms of accuracy (RMSE reductions up to $43\%$) and computational efficiency. By combining the scalability of deep learning with the biophysical rigor of process-based modeling, AgriPINN provides a robust and interpretable framework for spatio-temporal AGB prediction, offering practical value for planning of irrigation infrastructure, yield forecasting, and climate-adaptation planning.
UGOD: Uncertainty-Guided Differentiable Opacity and Soft Dropout for Enhanced Sparse-View 3DGS
Aug 07, 20253D Gaussian Splatting (3DGS) has become a competitive approach for novel view synthesis (NVS) due to its advanced rendering efficiency through 3D Gaussian projection and blending. However, Gaussians are treated equally weighted for rendering in most 3DGS methods, making them prone to overfitting, which is particularly the case in sparse-view scenarios. To address this, we investigate how adaptive weighting of Gaussians affects rendering quality, which is characterised by learned uncertainties proposed. This learned uncertainty serves two key purposes: first, it guides the differentiable update of Gaussian opacity while preserving the 3DGS pipeline integrity; second, the uncertainty undergoes soft differentiable dropout regularisation, which strategically transforms the original uncertainty into continuous drop probabilities that govern the final Gaussian projection and blending process for rendering. Extensive experimental results over widely adopted datasets demonstrate that our method outperforms rivals in sparse-view 3D synthesis, achieving higher quality reconstruction with fewer Gaussians in most datasets compared to existing sparse-view approaches, e.g., compared to DropGaussian, our method achieves 3.27\% PSNR improvements on the MipNeRF 360 dataset.
HMSViT: A Hierarchical Masked Self-Supervised Vision Transformer for Corneal Nerve Segmentation and Diabetic Neuropathy Diagnosis
Jun 24, 2025Diabetic Peripheral Neuropathy (DPN) affects nearly half of diabetes patients, requiring early detection. Corneal Confocal Microscopy (CCM) enables non-invasive diagnosis, but automated methods suffer from inefficient feature extraction, reliance on handcrafted priors, and data limitations. We propose HMSViT, a novel Hierarchical Masked Self-Supervised Vision Transformer (HMSViT) designed for corneal nerve segmentation and DPN diagnosis. Unlike existing methods, HMSViT employs pooling-based hierarchical and dual attention mechanisms with absolute positional encoding, enabling efficient multi-scale feature extraction by capturing fine-grained local details in early layers and integrating global context in deeper layers, all at a lower computational cost. A block-masked self supervised learning framework is designed for the HMSViT that reduces reliance on labelled data, enhancing feature robustness, while a multi-scale decoder is used for segmentation and classification by fusing hierarchical features. Experiments on clinical CCM datasets showed HMSViT achieves state-of-the-art performance, with 61.34% mIoU for nerve segmentation and 70.40% diagnostic accuracy, outperforming leading hierarchical models like the Swin Transformer and HiViT by margins of up to 6.39% in segmentation accuracy while using fewer parameters. Detailed ablation studies further reveal that integrating block-masked SSL with hierarchical multi-scale feature extraction substantially enhances performance compared to conventional supervised training. Overall, these comprehensive experiments confirm that HMSViT delivers excellent, robust, and clinically viable results, demonstrating its potential for scalable deployment in real-world diagnostic applications.
Deep Learning Meets Process-Based Models: A Hybrid Approach to Agricultural Challenges
Apr 22, 2025



Process-based models (PBMs) and deep learning (DL) are two key approaches in agricultural modelling, each offering distinct advantages and limitations. PBMs provide mechanistic insights based on physical and biological principles, ensuring interpretability and scientific rigour. However, they often struggle with scalability, parameterisation, and adaptation to heterogeneous environments. In contrast, DL models excel at capturing complex, nonlinear patterns from large datasets but may suffer from limited interpretability, high computational demands, and overfitting in data-scarce scenarios. This study presents a systematic review of PBMs, DL models, and hybrid PBM-DL frameworks, highlighting their applications in agricultural and environmental modelling. We classify hybrid PBM-DL approaches into DL-informed PBMs, where neural networks refine process-based models, and PBM-informed DL, where physical constraints guide deep learning predictions. Additionally, we conduct a case study on crop dry biomass prediction, comparing hybrid models against standalone PBMs and DL models under varying data quality, sample sizes, and spatial conditions. The results demonstrate that hybrid models consistently outperform traditional PBMs and DL models, offering greater robustness to noisy data and improved generalisation across unseen locations. Finally, we discuss key challenges, including model interpretability, scalability, and data requirements, alongside actionable recommendations for advancing hybrid modelling in agriculture. By integrating domain knowledge with AI-driven approaches, this study contributes to the development of scalable, interpretable, and reproducible agricultural models that support data-driven decision-making for sustainable agriculture.
TabulaTime: A Novel Multimodal Deep Learning Framework for Advancing Acute Coronary Syndrome Prediction through Environmental and Clinical Data Integration
Feb 24, 2025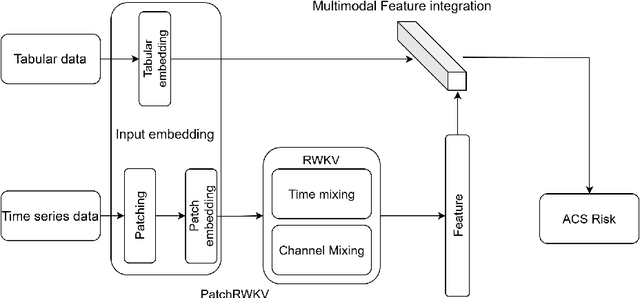

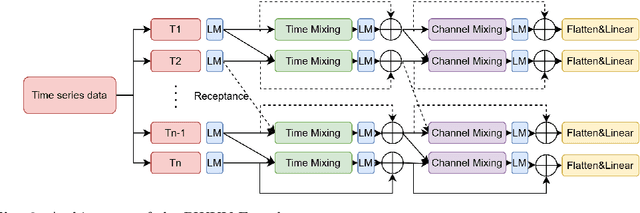

Acute Coronary Syndromes (ACS), including ST-segment elevation myocardial infarctions (STEMI) and non-ST-segment elevation myocardial infarctions (NSTEMI), remain a leading cause of mortality worldwide. Traditional cardiovascular risk scores rely primarily on clinical data, often overlooking environmental influences like air pollution that significantly impact heart health. Moreover, integrating complex time-series environmental data with clinical records is challenging. We introduce TabulaTime, a multimodal deep learning framework that enhances ACS risk prediction by combining clinical risk factors with air pollution data. TabulaTime features three key innovations: First, it integrates time-series air pollution data with clinical tabular data to improve prediction accuracy. Second, its PatchRWKV module automatically extracts complex temporal patterns, overcoming limitations of traditional feature engineering while maintaining linear computational complexity. Third, attention mechanisms enhance interpretability by revealing interactions between clinical and environmental factors. Experimental results show that TabulaTime improves prediction accuracy by over 20% compared to conventional models such as CatBoost, Random Forest, and LightGBM, with air pollution data alone contributing over a 10% improvement. Feature importance analysis identifies critical predictors including previous angina, systolic blood pressure, PM10, and NO2. Overall, TabulaTime bridges clinical and environmental insights, supporting personalized prevention strategies and informing public health policies to mitigate ACS risk.
GP-GS: Gaussian Processes for Enhanced Gaussian Splatting
Feb 05, 2025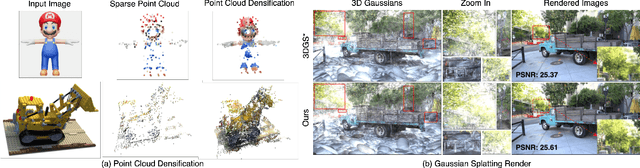
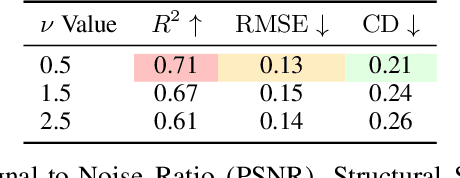
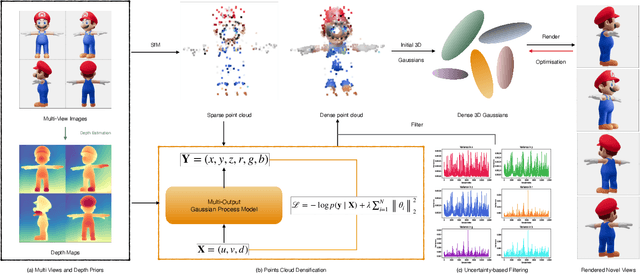
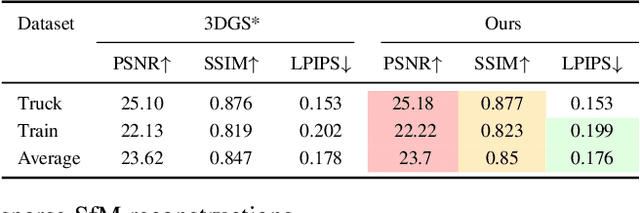
3D Gaussian Splatting has emerged as an efficient photorealistic novel view synthesis method. However, its reliance on sparse Structure-from-Motion (SfM) point clouds consistently compromises the scene reconstruction quality. To address these limitations, this paper proposes a novel 3D reconstruction framework Gaussian Processes Gaussian Splatting (GP-GS), where a multi-output Gaussian Process model is developed to achieve adaptive and uncertainty-guided densification of sparse SfM point clouds. Specifically, we propose a dynamic sampling and filtering pipeline that adaptively expands the SfM point clouds by leveraging GP-based predictions to infer new candidate points from the input 2D pixels and depth maps. The pipeline utilizes uncertainty estimates to guide the pruning of high-variance predictions, ensuring geometric consistency and enabling the generation of dense point clouds. The densified point clouds provide high-quality initial 3D Gaussians to enhance reconstruction performance. Extensive experiments conducted on synthetic and real-world datasets across various scales validate the effectiveness and practicality of the proposed framework.
WaveDiffUR: A diffusion SDE-based solver for ultra magnification super-resolution in remote sensing images
Dec 25, 2024Deep neural networks have recently achieved significant advancements in remote sensing superresolu-tion (SR). However, most existing methods are limited to low magnification rates (e.g., 2 or 4) due to the escalating ill-posedness at higher magnification scales. To tackle this challenge, we redefine high-magnification SR as the ultra-resolution (UR) problem, reframing it as solving a conditional diffusion stochastic differential equation (SDE). In this context, we propose WaveDiffUR, a novel wavelet-domain diffusion UR solver that decomposes the UR process into sequential sub-processes addressing conditional wavelet components. WaveDiffUR iteratively reconstructs low-frequency wavelet details (ensuring global consistency) and high-frequency components (enhancing local fidelity) by incorporating pre-trained SR models as plug-and-play modules. This modularity mitigates the ill-posedness of the SDE and ensures scalability across diverse applications. To address limitations in fixed boundary conditions at extreme magnifications, we introduce the cross-scale pyramid (CSP) constraint, a dynamic and adaptive framework that guides WaveDiffUR in generating fine-grained wavelet details, ensuring consistent and high-fidelity outputs even at extreme magnification rates.
A Novel Spike Transformer Network for Depth Estimation from Event Cameras via Cross-modality Knowledge Distillation
May 01, 2024Depth estimation is crucial for interpreting complex environments, especially in areas such as autonomous vehicle navigation and robotics. Nonetheless, obtaining accurate depth readings from event camera data remains a formidable challenge. Event cameras operate differently from traditional digital cameras, continuously capturing data and generating asynchronous binary spikes that encode time, location, and light intensity. Yet, the unique sampling mechanisms of event cameras render standard image based algorithms inadequate for processing spike data. This necessitates the development of innovative, spike-aware algorithms tailored for event cameras, a task compounded by the irregularity, continuity, noise, and spatial and temporal characteristics inherent in spiking data.Harnessing the strong generalization capabilities of transformer neural networks for spatiotemporal data, we propose a purely spike-driven spike transformer network for depth estimation from spiking camera data. To address performance limitations with Spiking Neural Networks (SNN), we introduce a novel single-stage cross-modality knowledge transfer framework leveraging knowledge from a large vision foundational model of artificial neural networks (ANN) (DINOv2) to enhance the performance of SNNs with limited data. Our experimental results on both synthetic and real datasets show substantial improvements over existing models, with notable gains in Absolute Relative and Square Relative errors (49% and 39.77% improvements over the benchmark model Spike-T, respectively). Besides accuracy, the proposed model also demonstrates reduced power consumptions, a critical factor for practical applications.
A Fast Fourier Convolutional Deep Neural Network For Accurate and Explainable Discrimination Of Wheat Yellow Rust And Nitrogen Deficiency From Sentinel-2 Time-Series Data
Jun 29, 2023Accurate and timely detection of plant stress is essential for yield protection, allowing better-targeted intervention strategies. Recent advances in remote sensing and deep learning have shown great potential for rapid non-invasive detection of plant stress in a fully automated and reproducible manner. However, the existing models always face several challenges: 1) computational inefficiency and the misclassifications between the different stresses with similar symptoms; and 2) the poor interpretability of the host-stress interaction. In this work, we propose a novel fast Fourier Convolutional Neural Network (FFDNN) for accurate and explainable detection of two plant stresses with similar symptoms (i.e. Wheat Yellow Rust And Nitrogen Deficiency). Specifically, unlike the existing CNN models, the main components of the proposed model include: 1) a fast Fourier convolutional block, a newly fast Fourier transformation kernel as the basic perception unit, to substitute the traditional convolutional kernel to capture both local and global responses to plant stress in various time-scale and improve computing efficiency with reduced learning parameters in Fourier domain; 2) Capsule Feature Encoder to encapsulate the extracted features into a series of vector features to represent part-to-whole relationship with the hierarchical structure of the host-stress interactions of the specific stress. In addition, in order to alleviate over-fitting, a photochemical vegetation indices-based filter is placed as pre-processing operator to remove the non-photochemical noises from the input Sentinel-2 time series.