 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriPINN: A Process-Informed Neural Network for Interpretable and Scalable Crop Biomass Prediction Under Water Stress
Jan 22, 2026Accurate prediction of crop above-ground biomass (AGB) under water stress is critical for monitoring crop productivity, guiding irrigation, and supporting climate-resilient agriculture. Data-driven models scale well but often lack interpretability and degrade under distribution shift, whereas process-based crop models (e.g. DSSAT, APSIM, LINTUL5) require extensive calibration and are difficult to deploy over large spatial domains. To address these limitations, we propose AgriPINN, a process-informed neural network that integrates a biophysical crop-growth differential equation as a differentiable constraint within a deep learning backbone. This design encourages physiologically consistent biomass dynamics under water-stress conditions while preserving model scalability for spatially distributed AGB prediction. AgriPINN recovers latent physiological variables, including leaf area index (LAI), absorbed photosynthetically active radiation (PAR), radiation use efficiency (RUE), and water-stress factors, without requiring direct supervision. We pretrain AgriPINN on 60 years of historical data across 397 regions in Germany and fine-tune it on three years of field experiments under controlled water treatments. Results show that AgriPINN consistently outperforms state-of-the-art deep-learning baselines (ConvLSTM-ViT, SLTF, CNN-Transformer) and the process-based LINTUL5 model in terms of accuracy (RMSE reductions up to $43\%$) and computational efficiency. By combining the scalability of deep learning with the biophysical rigor of process-based modeling, AgriPINN provides a robust and interpretable framework for spatio-temporal AGB prediction, offering practical value for planning of irrigation infrastructure, yield forecasting, and climate-adaptation planning.
Deep Learning Meets Process-Based Models: A Hybrid Approach to Agricultural Challenges
Apr 22, 2025



Process-based models (PBMs) and deep learning (DL) are two key approaches in agricultural modelling, each offering distinct advantages and limitations. PBMs provide mechanistic insights based on physical and biological principles, ensuring interpretability and scientific rigour. However, they often struggle with scalability, parameterisation, and adaptation to heterogeneous environments. In contrast, DL models excel at capturing complex, nonlinear patterns from large datasets but may suffer from limited interpretability, high computational demands, and overfitting in data-scarce scenarios. This study presents a systematic review of PBMs, DL models, and hybrid PBM-DL frameworks, highlighting their applications in agricultural and environmental modelling. We classify hybrid PBM-DL approaches into DL-informed PBMs, where neural networks refine process-based models, and PBM-informed DL, where physical constraints guide deep learning predictions. Additionally, we conduct a case study on crop dry biomass prediction, comparing hybrid models against standalone PBMs and DL models under varying data quality, sample sizes, and spatial conditions. The results demonstrate that hybrid models consistently outperform traditional PBMs and DL models, offering greater robustness to noisy data and improved generalisation across unseen locations. Finally, we discuss key challenges, including model interpretability, scalability, and data requirements, alongside actionable recommendations for advancing hybrid modelling in agriculture. By integrating domain knowledge with AI-driven approaches, this study contributes to the development of scalable, interpretable, and reproducible agricultural models that support data-driven decision-making for sustainable agriculture.
A Novel Spike Transformer Network for Depth Estimation from Event Cameras via Cross-modality Knowledge Distillation
May 01, 2024Depth estimation is crucial for interpreting complex environments, especially in areas such as autonomous vehicle navigation and robotics. Nonetheless, obtaining accurate depth readings from event camera data remains a formidable challenge. Event cameras operate differently from traditional digital cameras, continuously capturing data and generating asynchronous binary spikes that encode time, location, and light intensity. Yet, the unique sampling mechanisms of event cameras render standard image based algorithms inadequate for processing spike data. This necessitates the development of innovative, spike-aware algorithms tailored for event cameras, a task compounded by the irregularity, continuity, noise, and spatial and temporal characteristics inherent in spiking data.Harnessing the strong generalization capabilities of transformer neural networks for spatiotemporal data, we propose a purely spike-driven spike transformer network for depth estimation from spiking camera data. To address performance limitations with Spiking Neural Networks (SNN), we introduce a novel single-stage cross-modality knowledge transfer framework leveraging knowledge from a large vision foundational model of artificial neural networks (ANN) (DINOv2) to enhance the performance of SNNs with limited data. Our experimental results on both synthetic and real datasets show substantial improvements over existing models, with notable gains in Absolute Relative and Square Relative errors (49% and 39.77% improvements over the benchmark model Spike-T, respectively). Besides accuracy, the proposed model also demonstrates reduced power consumptions, a critical factor for practical applications.
The channel-spatial attention-based vision transformer network for automated, accurate prediction of crop nitrogen status from UAV imagery
Nov 12, 2021
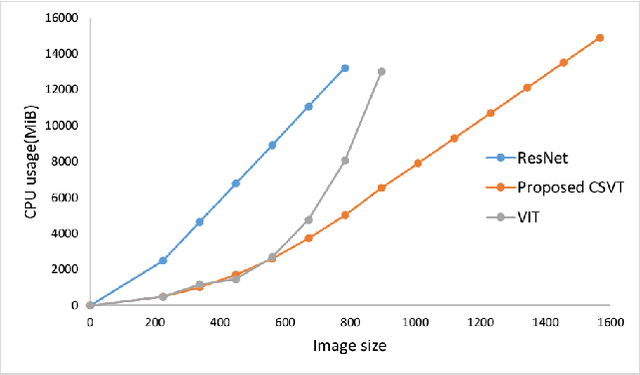
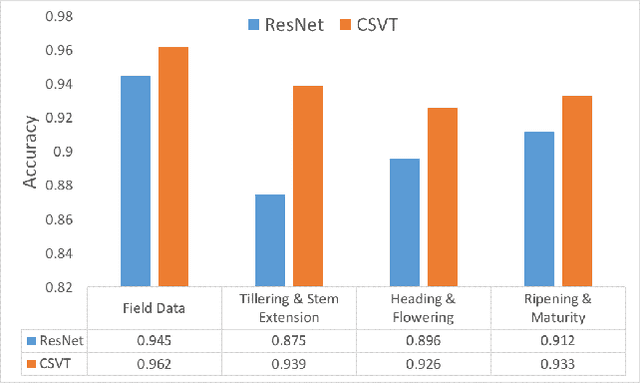
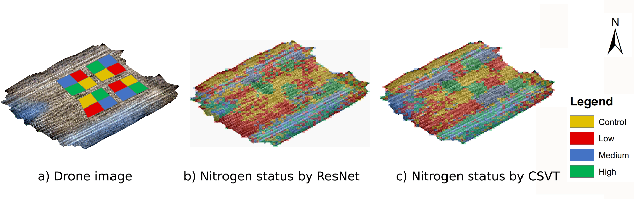
Nitrogen (N) fertiliser is routinely applied by farmers to increase crop yields. At present, farmers often over-apply N fertilizer in some locations or timepoints because they do not have high-resolution crop N status data. N-use efficiency can be low, with the remaining N lost to the environment, resulting in high production costs and environmental pollution. Accurate and timely estimation of N status in crops is crucial to improving cropping systems' economic and environmental sustainability. The conventional approaches based on tissue analysis in the laboratory for estimating N status in plants are time consuming and destructive. Recent advances in remote sensing and machine learning have shown promise in addressing the aforementioned challenges in a non-destructive way. We propose a novel deep learning framework: a channel-spatial attention-based vision transformer (CSVT) for estimating crop N status from large images collected from a UAV in a wheat field. Unlike the existing works, the proposed CSVT introduces a Channel Attention Block (CAB) and a Spatial Interaction Block (SIB), which allows capturing nonlinear characteristics of spatial-wise and channel-wise features from UAV digital aerial imagery, for accurate N status prediction in wheat crops. Moreover, since acquiring labeled data is time consuming and costly, local-to-global self-supervised learning is introduced to pre-train the CSVT with extensive unlabelled data. The proposed CSVT has been compared with the state-of-the-art models, tested and validated on both testing and independent datasets. The proposed approach achieved high accuracy (0.96) with good generalizability and reproducibility for wheat N status estimation.
CXR-Net: An Encoder-Decoder-Encoder Multitask Deep Neural Network for Explainable and Accurate Diagnosis of COVID-19 pneumonia with Chest X-ray Images
Oct 20, 2021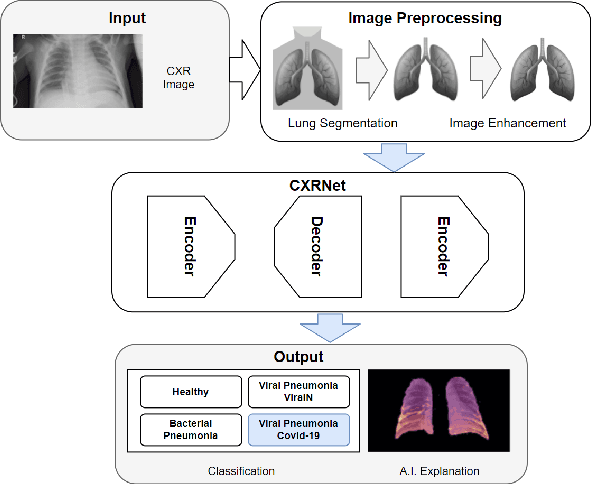
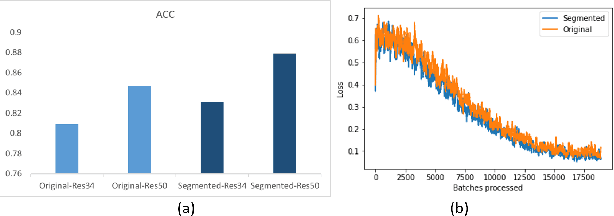
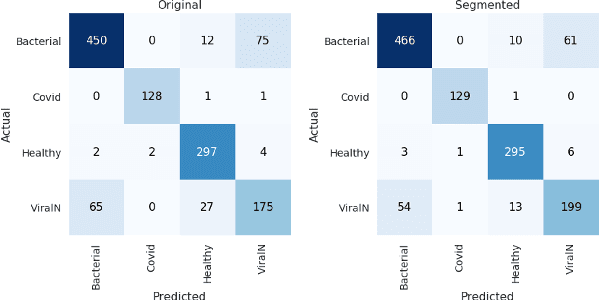
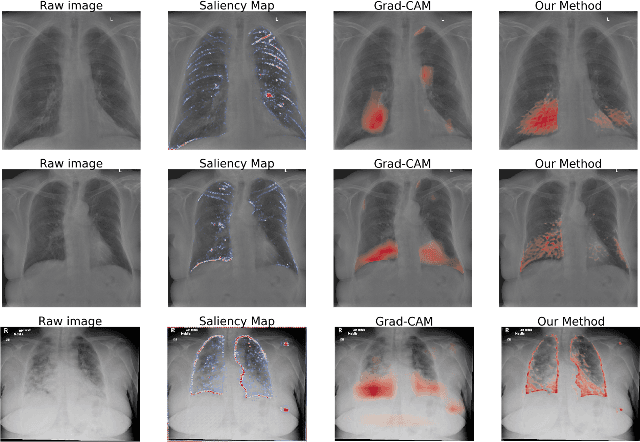
Accurate and rapid detection of COVID-19 pneumonia is crucial for optimal patient treatment. Chest X-Ray (CXR) is the first line imaging test for COVID-19 pneumonia diagnosis as it is fast, cheap and easily accessible. Inspired by the success of deep learning (DL) in computer vision, many DL-models have been proposed to detect COVID-19 pneumonia using CXR images. Unfortunately, these deep classifiers lack the transparency in interpreting findings, which may limit their applications in clinical practice. The existing commonly used visual explanation methods are either too noisy or imprecise, with low resolution, and hence are unsuitable for diagnostic purposes. In this work, we propose a novel explainable deep learning framework (CXRNet) for accurate COVID-19 pneumonia detection with an enhanced pixel-level visual explanation from CXR images. The proposed framework is based on a new Encoder-Decoder-Encoder multitask architecture, allowing for both disease classification and visual explanation. The method has been evaluated on real world CXR datasets from both public and private data sources, including: healthy, bacterial pneumonia, viral pneumonia and COVID-19 pneumonia cases The experimental results demonstrate that the proposed method can achieve a satisfactory level of accuracy and provide fine-resolution classification activation maps for visual explanation in lung disease detection. The Average Accuracy, the Precision, Recall and F1-score of COVID-19 pneumonia reached 0.879, 0.985, 0.992 and 0.989, respectively. We have also found that using lung segmented (CXR) images can help improve the performance of the model. The proposed method can provide more detailed high resolution visual explanation for the classification decision, compared to current state-of-the-art visual explanation methods and has a great potential to be used in clinical practice for COVID-19 pneumonia diagnosis.