 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Attribution in Filipino Language Models: Extending a Bias Interpretability Metric for Application on Agglutinative Languages
Jun 08, 2025

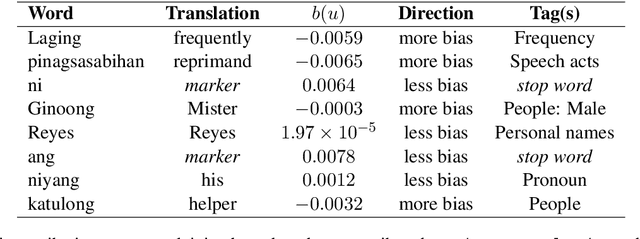
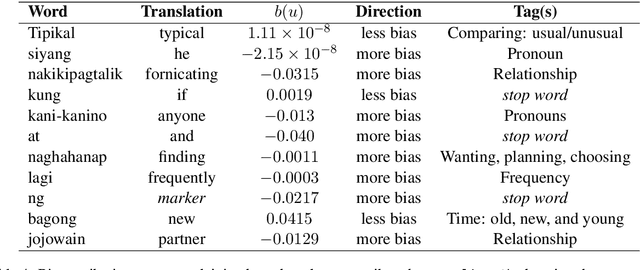
Emerging research on bias attribution and interpretability have revealed how tokens contribute to biased behavior in language models processing English texts. We build on this line of inquiry by adapting the information-theoretic bias attribution score metric for implementation on models handling agglutinative languages, particularly Filipino. We then demonstrate the effectiveness of our adapted method by using it on a purely Filipino model and on three multilingual models: one trained on languages worldwide and two on Southeast Asian data. Our results show that Filipino models are driven towards bias by words pertaining to people, objects, and relationships, entity-based themes that stand in contrast to the action-heavy nature of bias-contributing themes in English (i.e., criminal, sexual, and prosocial behaviors). These findings point to differences in how English and non-English models process inputs linked to sociodemographic groups and bias.
Delta Decompression for MoE-based LLMs Compression
Feb 24, 2025



Mixture-of-Experts (MoE) architectures in large language models (LLMs) achieve exceptional performance, but face prohibitive storage and memory requirements. To address these challenges, we present $D^2$-MoE, a new delta decompression compressor for reducing the parameters of MoE LLMs. Based on observations of expert diversity, we decompose their weights into a shared base weight and unique delta weights. Specifically, our method first merges each expert's weight into the base weight using the Fisher information matrix to capture shared components. Then, we compress delta weights through Singular Value Decomposition (SVD) by exploiting their low-rank properties. Finally, we introduce a semi-dynamical structured pruning strategy for the base weights, combining static and dynamic redundancy analysis to achieve further parameter reduction while maintaining input adaptivity. In this way, our $D^2$-MoE successfully compact MoE LLMs to high compression ratios without additional training. Extensive experiments highlight the superiority of our approach, with over 13% performance gains than other compressors on Mixtral|Phi-3.5|DeepSeek|Qwen2 MoE LLMs at 40$\sim$60% compression rates. Codes are available in https://github.com/lliai/D2MoE.
Filipino Benchmarks for Measuring Sexist and Homophobic Bias in Multilingual Language Models from Southeast Asia
Dec 10, 2024



Bias studies on multilingual models confirm the presence of gender-related stereotypes in masked models processing languages with high NLP resources. We expand on this line of research by introducing Filipino CrowS-Pairs and Filipino WinoQueer: benchmarks that assess both sexist and anti-queer biases in pretrained language models (PLMs) handling texts in Filipino, a low-resource language from the Philippines. The benchmarks consist of 7,074 new challenge pairs resulting from our cultural adaptation of English bias evaluation datasets, a process that we document in detail to guide similar forthcoming efforts. We apply the Filipino benchmarks on masked and causal multilingual models, including those pretrained on Southeast Asian data, and find that they contain considerable amounts of bias. We also find that for multilingual models, the extent of bias learned for a particular language is influenced by how much pretraining data in that language a model was exposed to. Our benchmarks and insights can serve as a foundation for future work analyzing and mitigating bias in multilingual models.
A Novel Interpretability Metric for Explaining Bias in Language Models: Applications on Multilingual Models from Southeast Asia
Oct 20, 2024
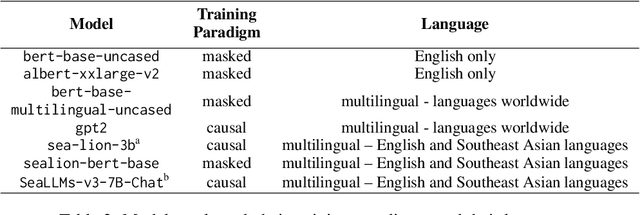
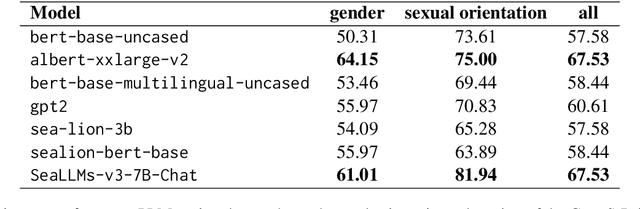

Work on bias in pretrained language models (PLMs) focuses on bias evaluation and mitigation and fails to tackle the question of bias attribution and explainability.We propose a novel metric, the $\textit{bias attribution score}$, which draws from information theory to measure token-level contributions to biased behavior in PLMs. We then demonstrate the utility of this metric by applying it on multilingual PLMs, including models from Southeast Asia which have not yet been thoroughly examined in bias evaluation literature. Our results confirm the presence of sexist and homophobic bias in Southeast Asian PLMs. Interpretability and semantic analyses also reveal that PLM bias is strongly induced by words relating to crime, intimate relationships, and helping among other discursive categories, suggesting that these are topics where PLMs strongly reproduce bias from pretraining data and where PLMs should be used with more caution.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training
May 23, 2024



Mixture-of-Experts (MoE) enjoys performance gain by increasing model capacity while keeping computation cost constant. When comparing MoE to dense models, prior work typically adopt the following setting: 1) use FLOPs or activated parameters as a measure of model complexity; 2) train all models to the same number of tokens. We argue that this setting favors MoE as FLOPs and activated parameters do not accurately measure the communication overhead in sparse layers, leading to a larger actual training budget for MoE. In this work, we revisit the settings by adopting step time as a more accurate measure of model complexity, and by determining the total compute budget under the Chinchilla compute-optimal settings. To efficiently run MoE on modern accelerators, we adopt a 3D sharding method that keeps the dense-to-MoE step time increase within a healthy range. We evaluate MoE and dense LLMs on a set of nine 0-shot and two 1-shot English tasks, as well as MMLU 5-shot and GSM8K 8-shot across three model scales at 6.4B, 12.6B, and 29.6B. Experimental results show that even under these settings, MoE consistently outperform dense LLMs on the speed-accuracy trade-off curve with meaningful gaps. Our full model implementation and sharding strategy will be released at~\url{https://github.com/apple/axlearn}
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 22, 2024



In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Code-Mixed Probes Show How Pre-Trained Models Generalise On Code-Switched Text
Mar 07, 2024



Code-switching is a prevalent linguistic phenomenon in which multilingual individuals seamlessly alternate between languages. Despite its widespread use online and recent research trends in this area, research in code-switching presents unique challenges, primarily stemming from the scarcity of labelled data and available resources. In this study we investigate how pre-trained Language Models handle code-switched text in three dimensions: a) the ability of PLMs to detect code-switched text, b) variations in the structural information that PLMs utilise to capture code-switched text, and c) the consistency of semantic information representation in code-switched text. To conduct a systematic and controlled evaluation of the language models in question, we create a novel dataset of well-formed naturalistic code-switched text along with parallel translations into the source languages. Our findings reveal that pre-trained language models are effective in generalising to code-switched text, shedding light on the abilities of these models to generalise representations to CS corpora. We release all our code and data including the novel corpus at https://github.com/francesita/code-mixed-probes.
The channel-spatial attention-based vision transformer network for automated, accurate prediction of crop nitrogen status from UAV imagery
Nov 12, 2021
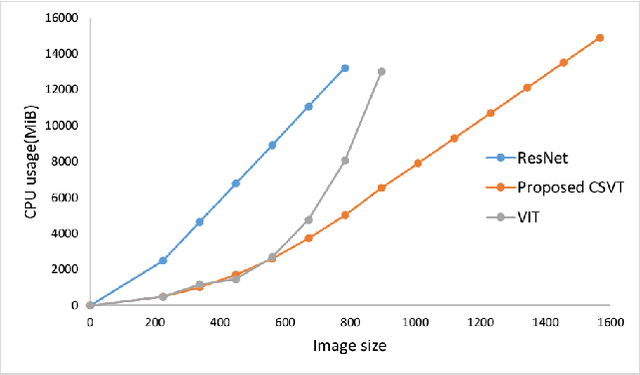
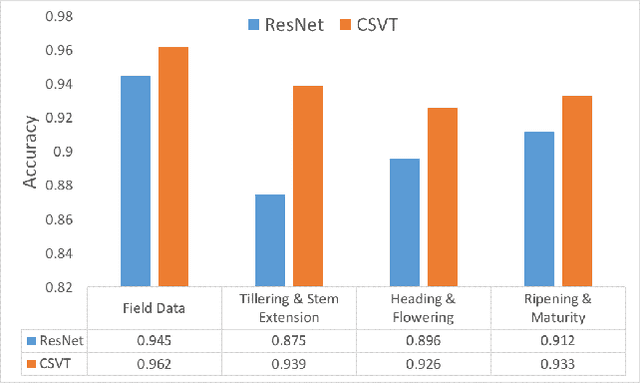
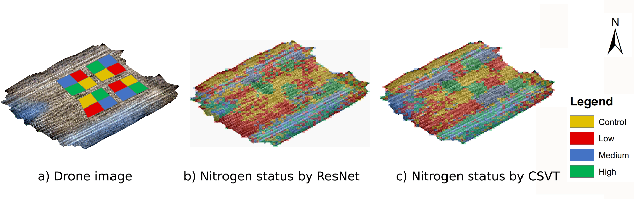
Nitrogen (N) fertiliser is routinely applied by farmers to increase crop yields. At present, farmers often over-apply N fertilizer in some locations or timepoints because they do not have high-resolution crop N status data. N-use efficiency can be low, with the remaining N lost to the environment, resulting in high production costs and environmental pollution. Accurate and timely estimation of N status in crops is crucial to improving cropping systems' economic and environmental sustainability. The conventional approaches based on tissue analysis in the laboratory for estimating N status in plants are time consuming and destructive. Recent advances in remote sensing and machine learning have shown promise in addressing the aforementioned challenges in a non-destructive way. We propose a novel deep learning framework: a channel-spatial attention-based vision transformer (CSVT) for estimating crop N status from large images collected from a UAV in a wheat field. Unlike the existing works, the proposed CSVT introduces a Channel Attention Block (CAB) and a Spatial Interaction Block (SIB), which allows capturing nonlinear characteristics of spatial-wise and channel-wise features from UAV digital aerial imagery, for accurate N status prediction in wheat crops. Moreover, since acquiring labeled data is time consuming and costly, local-to-global self-supervised learning is introduced to pre-train the CSVT with extensive unlabelled data. The proposed CSVT has been compared with the state-of-the-art models, tested and validated on both testing and independent datasets. The proposed approach achieved high accuracy (0.96) with good generalizability and reproducibility for wheat N status estimation.
Can vectors read minds better than experts? Comparing data augmentation strategies for the automated scoring of children's mindreading ability
Jun 03, 2021



In this paper we implement and compare 7 different data augmentation strategies for the task of automatic scoring of children's ability to understand others' thoughts, feelings, and desires (or "mindreading"). We recruit in-domain experts to re-annotate augmented samples and determine to what extent each strategy preserves the original rating. We also carry out multiple experiments to measure how much each augmentation strategy improves the performance of automatic scoring systems. To determine the capabilities of automatic systems to generalize to unseen data, we create UK-MIND-20 - a new corpus of children's performance on tests of mindreading, consisting of 10,320 question-answer pairs. We obtain a new state-of-the-art performance on the MIND-CA corpus, improving macro-F1-score by 6 points. Results indicate that both the number of training examples and the quality of the augmentation strategies affect the performance of the systems. The task-specific augmentations generally outperform task-agnostic augmentations. Automatic augmentations based on vectors (GloVe, FastText) perform the worst. We find that systems trained on MIND-CA generalize well to UK-MIND-20. We demonstrate that data augmentation strategies also improve the performance on unseen data.