 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Bias Evaluation with FilBBQ: A Filipino Bias Benchmark for Question-Answering Language Models
Feb 16, 2026With natural language generation becoming a popular use case for language models, the Bias Benchmark for Question-Answering (BBQ) has grown to be an important benchmark format for evaluating stereotypical associations exhibited by generative models. We expand the linguistic scope of BBQ and construct FilBBQ through a four-phase development process consisting of template categorization, culturally aware translation, new template construction, and prompt generation. These processes resulted in a bias test composed of more than 10,000 prompts which assess whether models demonstrate sexist and homophobic prejudices relevant to the Philippine context. We then apply FilBBQ on models trained in Filipino but do so with a robust evaluation protocol that improves upon the reliability and accuracy of previous BBQ implementations. Specifically, we account for models' response instability by obtaining prompt responses across multiple seeds and averaging the bias scores calculated from these distinctly seeded runs. Our results confirm both the variability of bias scores across different seeds and the presence of sexist and homophobic biases relating to emotion, domesticity, stereotyped queer interests, and polygamy. FilBBQ is available via GitHub.
Bias Attribution in Filipino Language Models: Extending a Bias Interpretability Metric for Application on Agglutinative Languages
Jun 08, 2025

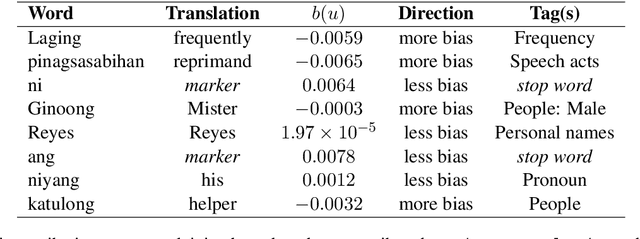
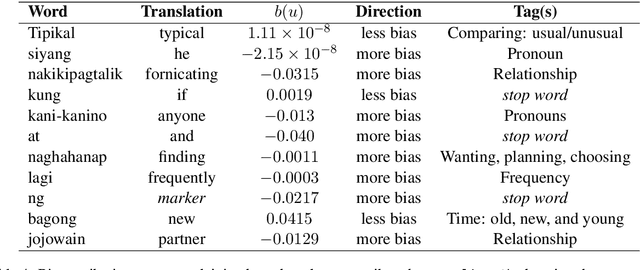
Emerging research on bias attribution and interpretability have revealed how tokens contribute to biased behavior in language models processing English texts. We build on this line of inquiry by adapting the information-theoretic bias attribution score metric for implementation on models handling agglutinative languages, particularly Filipino. We then demonstrate the effectiveness of our adapted method by using it on a purely Filipino model and on three multilingual models: one trained on languages worldwide and two on Southeast Asian data. Our results show that Filipino models are driven towards bias by words pertaining to people, objects, and relationships, entity-based themes that stand in contrast to the action-heavy nature of bias-contributing themes in English (i.e., criminal, sexual, and prosocial behaviors). These findings point to differences in how English and non-English models process inputs linked to sociodemographic groups and bias.
Filipino Benchmarks for Measuring Sexist and Homophobic Bias in Multilingual Language Models from Southeast Asia
Dec 10, 2024



Bias studies on multilingual models confirm the presence of gender-related stereotypes in masked models processing languages with high NLP resources. We expand on this line of research by introducing Filipino CrowS-Pairs and Filipino WinoQueer: benchmarks that assess both sexist and anti-queer biases in pretrained language models (PLMs) handling texts in Filipino, a low-resource language from the Philippines. The benchmarks consist of 7,074 new challenge pairs resulting from our cultural adaptation of English bias evaluation datasets, a process that we document in detail to guide similar forthcoming efforts. We apply the Filipino benchmarks on masked and causal multilingual models, including those pretrained on Southeast Asian data, and find that they contain considerable amounts of bias. We also find that for multilingual models, the extent of bias learned for a particular language is influenced by how much pretraining data in that language a model was exposed to. Our benchmarks and insights can serve as a foundation for future work analyzing and mitigating bias in multilingual models.
A Novel Interpretability Metric for Explaining Bias in Language Models: Applications on Multilingual Models from Southeast Asia
Oct 20, 2024
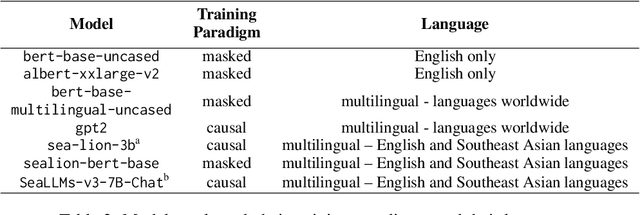
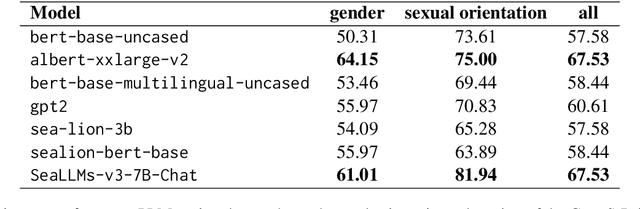

Work on bias in pretrained language models (PLMs) focuses on bias evaluation and mitigation and fails to tackle the question of bias attribution and explainability.We propose a novel metric, the $\textit{bias attribution score}$, which draws from information theory to measure token-level contributions to biased behavior in PLMs. We then demonstrate the utility of this metric by applying it on multilingual PLMs, including models from Southeast Asia which have not yet been thoroughly examined in bias evaluation literature. Our results confirm the presence of sexist and homophobic bias in Southeast Asian PLMs. Interpretability and semantic analyses also reveal that PLM bias is strongly induced by words relating to crime, intimate relationships, and helping among other discursive categories, suggesting that these are topics where PLMs strongly reproduce bias from pretraining data and where PLMs should be used with more caution.