 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Bias Evaluation with FilBBQ: A Filipino Bias Benchmark for Question-Answering Language Models
Feb 16, 2026With natural language generation becoming a popular use case for language models, the Bias Benchmark for Question-Answering (BBQ) has grown to be an important benchmark format for evaluating stereotypical associations exhibited by generative models. We expand the linguistic scope of BBQ and construct FilBBQ through a four-phase development process consisting of template categorization, culturally aware translation, new template construction, and prompt generation. These processes resulted in a bias test composed of more than 10,000 prompts which assess whether models demonstrate sexist and homophobic prejudices relevant to the Philippine context. We then apply FilBBQ on models trained in Filipino but do so with a robust evaluation protocol that improves upon the reliability and accuracy of previous BBQ implementations. Specifically, we account for models' response instability by obtaining prompt responses across multiple seeds and averaging the bias scores calculated from these distinctly seeded runs. Our results confirm both the variability of bias scores across different seeds and the presence of sexist and homophobic biases relating to emotion, domesticity, stereotyped queer interests, and polygamy. FilBBQ is available via GitHub.
MoniTor: Exploiting Large Language Models with Instruction for Online Video Anomaly Detection
Oct 24, 2025Video Anomaly Detection (VAD) aims to locate unusual activities or behaviors within videos. Recently, offline VAD has garnered substantial research attention, which has been invigorated by the progress in large language models (LLMs) and vision-language models (VLMs), offering the potential for a more nuanced understanding of anomalies. However, online VAD has seldom received attention due to real-time constraints and computational intensity. In this paper, we introduce a novel Memory-based online scoring queue scheme for Training-free VAD (MoniTor), to address the inherent complexities in online VAD. Specifically, MoniTor applies a streaming input to VLMs, leveraging the capabilities of pre-trained large-scale models. To capture temporal dependencies more effectively, we incorporate a novel prediction mechanism inspired by Long Short-Term Memory (LSTM) networks. This ensures the model can effectively model past states and leverage previous predictions to identify anomalous behaviors. Thereby, it better understands the current frame. Moreover, we design a scoring queue and an anomaly prior to dynamically store recent scores and cover all anomalies in the monitoring scenario, providing guidance for LLMs to distinguish between normal and abnormal behaviors over time. We evaluate MoniTor on two large datasets (i.e., UCF-Crime and XD-Violence) containing various surveillance and real-world scenarios. The results demonstrate that MoniTor outperforms state-of-the-art methods and is competitive with weakly supervised methods without training. Code is available at https://github.com/YsTvT/MoniTor.
Bias Attribution in Filipino Language Models: Extending a Bias Interpretability Metric for Application on Agglutinative Languages
Jun 08, 2025

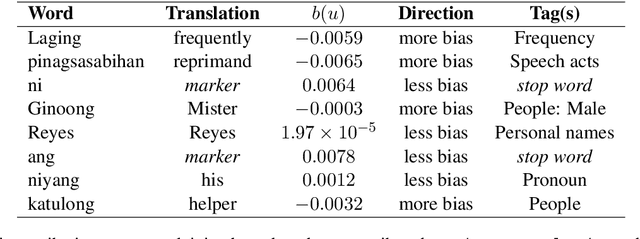
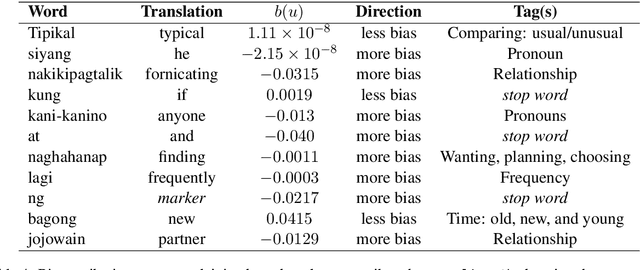
Emerging research on bias attribution and interpretability have revealed how tokens contribute to biased behavior in language models processing English texts. We build on this line of inquiry by adapting the information-theoretic bias attribution score metric for implementation on models handling agglutinative languages, particularly Filipino. We then demonstrate the effectiveness of our adapted method by using it on a purely Filipino model and on three multilingual models: one trained on languages worldwide and two on Southeast Asian data. Our results show that Filipino models are driven towards bias by words pertaining to people, objects, and relationships, entity-based themes that stand in contrast to the action-heavy nature of bias-contributing themes in English (i.e., criminal, sexual, and prosocial behaviors). These findings point to differences in how English and non-English models process inputs linked to sociodemographic groups and bias.
Direct Retrieval-augmented Optimization: Synergizing Knowledge Selection and Language Models
May 05, 2025Retrieval-augmented generation (RAG) integrates large language models ( LLM s) with retrievers to access external knowledge, improving the factuality of LLM generation in knowledge-grounded tasks. To optimize the RAG performance, most previous work independently fine-tunes the retriever to adapt to frozen LLM s or trains the LLMs to use documents retrieved by off-the-shelf retrievers, lacking end-to-end training supervision. Recent work addresses this limitation by jointly training these two components but relies on overly simplifying assumptions of document independence, which has been criticized for being far from real-world scenarios. Thus, effectively optimizing the overall RAG performance remains a critical challenge. We propose a direct retrieval-augmented optimization framework, named DRO, that enables end-to-end training of two key components: (i) a generative knowledge selection model and (ii) an LLM generator. DRO alternates between two phases: (i) document permutation estimation and (ii) re-weighted maximization, progressively improving RAG components through a variational approach. In the estimation step, we treat document permutation as a latent variable and directly estimate its distribution from the selection model by applying an importance sampling strategy. In the maximization step, we calibrate the optimization expectation using importance weights and jointly train the selection model and LLM generator. Our theoretical analysis reveals that DRO is analogous to policy-gradient methods in reinforcement learning. Extensive experiments conducted on five datasets illustrate that DRO outperforms the best baseline with 5%-15% improvements in EM and F1. We also provide in-depth experiments to qualitatively analyze the stability, convergence, and variance of DRO.
An Empirical Study of Qwen3 Quantization
May 04, 2025



The Qwen series has emerged as a leading family of open-source Large Language Models (LLMs), demonstrating remarkable capabilities in natural language understanding tasks. With the recent release of Qwen3, which exhibits superior performance across diverse benchmarks, there is growing interest in deploying these models efficiently in resource-constrained environments. Low-bit quantization presents a promising solution, yet its impact on Qwen3's performance remains underexplored. This study conducts a systematic evaluation of Qwen3's robustness under various quantization settings, aiming to uncover both opportunities and challenges in compressing this state-of-the-art model. We rigorously assess 5 existing classic post-training quantization techniques applied to Qwen3, spanning bit-widths from 1 to 8 bits, and evaluate their effectiveness across multiple datasets. Our findings reveal that while Qwen3 maintains competitive performance at moderate bit-widths, it experiences notable degradation in linguistic tasks under ultra-low precision, underscoring the persistent hurdles in LLM compression. These results emphasize the need for further research to mitigate performance loss in extreme quantization scenarios. We anticipate that this empirical analysis will provide actionable insights for advancing quantization methods tailored to Qwen3 and future LLMs, ultimately enhancing their practicality without compromising accuracy. Our project is released on https://github.com/Efficient-ML/Qwen3-Quantization and https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b.
The 1st EReL@MIR Workshop on Efficient Representation Learning for Multimodal Information Retrieval
Apr 21, 2025Multimodal representation learning has garnered significant attention in the AI community, largely due to the success of large pre-trained multimodal foundation models like LLaMA, GPT, Mistral, and CLIP. These models have achieved remarkable performance across various tasks of multimodal information retrieval (MIR), including web search, cross-modal retrieval, and recommender systems, etc. However, due to their enormous parameter sizes, significant efficiency challenges emerge across training, deployment, and inference stages when adapting these models' representation for IR tasks. These challenges present substantial obstacles to the practical adaptation of foundation models for representation learning in information retrieval tasks. To address these pressing issues, we propose organizing the first EReL@MIR workshop at the Web Conference 2025, inviting participants to explore novel solutions, emerging problems, challenges, efficiency evaluation metrics and benchmarks. This workshop aims to provide a platform for both academic and industry researchers to engage in discussions, share insights, and foster collaboration toward achieving efficient and effective representation learning for multimodal information retrieval in the era of large foundation models.
PolicyEvol-Agent: Evolving Policy via Environment Perception and Self-Awareness with Theory of Mind
Apr 20, 2025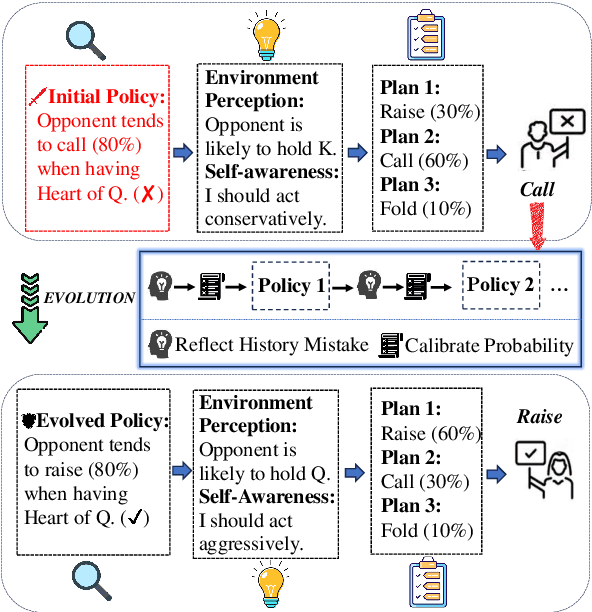



Multi-agents has exhibited significant intelligence in real-word simulations with Large language models (LLMs) due to the capabilities of social cognition and knowledge retrieval. However, existing research on agents equipped with effective cognition chains including reasoning, planning, decision-making and reflecting remains limited, especially in the dynamically interactive scenarios. In addition, unlike human, prompt-based responses face challenges in psychological state perception and empirical calibration during uncertain gaming process, which can inevitably lead to cognition bias. In light of above, we introduce PolicyEvol-Agent, a comprehensive LLM-empowered framework characterized by systematically acquiring intentions of others and adaptively optimizing irrational strategies for continual enhancement. Specifically, PolicyEvol-Agent first obtains reflective expertise patterns and then integrates a range of cognitive operations with Theory of Mind alongside internal and external perspectives. Simulation results, outperforming RL-based models and agent-based methods, demonstrate the superiority of PolicyEvol-Agent for final gaming victory. Moreover, the policy evolution mechanism reveals the effectiveness of dynamic guideline adjustments in both automatic and human evaluation.
UoB-NLP at SemEval-2025 Task 11: Leveraging Adapters for Multilingual and Cross-Lingual Emotion Detection
Apr 11, 2025Emotion detection in natural language processing is a challenging task due to the complexity of human emotions and linguistic diversity. While significant progress has been made in high-resource languages, emotion detection in low-resource languages remains underexplored. In this work, we address multilingual and cross-lingual emotion detection by leveraging adapter-based fine-tuning with multilingual pre-trained language models. Adapters introduce a small number of trainable parameters while keeping the pre-trained model weights fixed, offering a parameter-efficient approach to adaptation. We experiment with different adapter tuning strategies, including task-only adapters, target-language-ready task adapters, and language-family-based adapters. Our results show that target-language-ready task adapters achieve the best overall performance, particularly for low-resource African languages with our team ranking 7th for Tigrinya, and 8th for Kinyarwanda in Track A. In Track C, our system ranked 3rd for Amharic, and 4th for Oromo, Tigrinya, Kinyarwanda, Hausa, and Igbo. Our approach outperforms large language models in 11 languages and matches their performance in four others, despite our models having significantly fewer parameters. Furthermore, we find that adapter-based models retain cross-linguistic transfer capabilities while requiring fewer computational resources compared to full fine-tuning for each language.
Cognitive Debiasing Large Language Models for Decision-Making
Apr 10, 2025



Large language models (LLMs) have shown potential in supporting decision-making applications, particularly as personal conversational assistants in the financial, healthcare, and legal domains. While prompt engineering strategies have enhanced the capabilities of LLMs in decision-making, cognitive biases inherent to LLMs present significant challenges. Cognitive biases are systematic patterns of deviation from norms or rationality in decision-making that can lead to the production of inaccurate outputs. Existing cognitive bias mitigation strategies assume that input prompts contain (exactly) one type of cognitive bias and therefore fail to perform well in realistic settings where there maybe any number of biases. To fill this gap, we propose a cognitive debiasing approach, called self-debiasing, that enhances the reliability of LLMs by iteratively refining prompts. Our method follows three sequential steps -- bias determination, bias analysis, and cognitive debiasing -- to iteratively mitigate potential cognitive biases in prompts. Experimental results on finance, healthcare, and legal decision-making tasks, using both closed-source and open-source LLMs, demonstrate that the proposed self-debiasing method outperforms both advanced prompt engineering methods and existing cognitive debiasing techniques in average accuracy under no-bias, single-bias, and multi-bias settings.
Device-aware Optical Adversarial Attack for a Portable Projector-camera System
Jan 23, 2025



Deep-learning-based face recognition (FR) systems are susceptible to adversarial examples in both digital and physical domains. Physical attacks present a greater threat to deployed systems as adversaries can easily access the input channel, allowing them to provide malicious inputs to impersonate a victim. This paper addresses the limitations of existing projector-camera-based adversarial light attacks in practical FR setups. By incorporating device-aware adaptations into the digital attack algorithm, such as resolution-aware and color-aware adjustments, we mitigate the degradation from digital to physical domains. Experimental validation showcases the efficacy of our proposed algorithm against real and spoof adversaries, achieving high physical similarity scores in FR models and state-of-the-art commercial systems. On average, there is only a 14% reduction in scores from digital to physical attacks, with high attack success rate in both white- and black-box scenarios.