 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deepfake Detection with RL Enhanced Self-Blended Images
Jan 22, 2026Most prior deepfake detection methods lack explainable outputs. With the growing interest in multimodal large language models (MLLMs), researchers have started exploring their use in interpretable deepfake detection. However, a major obstacle in applying MLLMs to this task is the scarcity of high-quality datasets with detailed forgery attribution annotations, as textual annotation is both costly and challenging - particularly for high-fidelity forged images or videos. Moreover, multiple studies have shown that reinforcement learning (RL) can substantially enhance performance in visual tasks, especially in improving cross-domain generalization. To facilitate the adoption of mainstream MLLM frameworks in deepfake detection with reduced annotation cost, and to investigate the potential of RL in this context, we propose an automated Chain-of-Thought (CoT) data generation framework based on Self-Blended Images, along with an RL-enhanced deepfake detection framework. Extensive experiments validate the effectiveness of our CoT data construction pipeline, tailored reward mechanism, and feedback-driven synthetic data generation approach. Our method achieves performance competitive with state-of-the-art (SOTA) approaches across multiple cross-dataset benchmarks. Implementation details are available at https://github.com/deon1219/rlsbi.
Device-aware Optical Adversarial Attack for a Portable Projector-camera System
Jan 23, 2025Deep-learning-based face recognition (FR) systems are susceptible to adversarial examples in both digital and physical domains. Physical attacks present a greater threat to deployed systems as adversaries can easily access the input channel, allowing them to provide malicious inputs to impersonate a victim. This paper addresses the limitations of existing projector-camera-based adversarial light attacks in practical FR setups. By incorporating device-aware adaptations into the digital attack algorithm, such as resolution-aware and color-aware adjustments, we mitigate the degradation from digital to physical domains. Experimental validation showcases the efficacy of our proposed algorithm against real and spoof adversaries, achieving high physical similarity scores in FR models and state-of-the-art commercial systems. On average, there is only a 14% reduction in scores from digital to physical attacks, with high attack success rate in both white- and black-box scenarios.
Unified Physical-Digital Face Attack Detection
Jan 31, 2024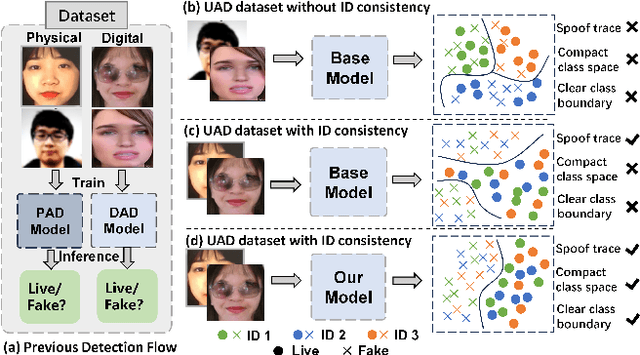
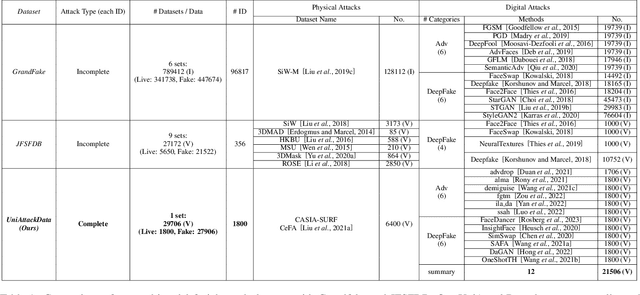
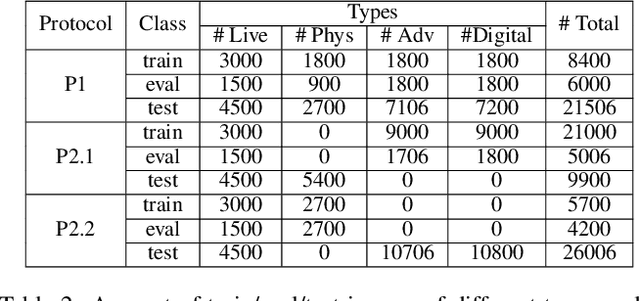

Face Recognition (FR) systems can suffer from physical (i.e., print photo) and digital (i.e., DeepFake) attacks. However, previous related work rarely considers both situations at the same time. This implies the deployment of multiple models and thus more computational burden. The main reasons for this lack of an integrated model are caused by two factors: (1) The lack of a dataset including both physical and digital attacks with ID consistency which means the same ID covers the real face and all attack types; (2) Given the large intra-class variance between these two attacks, it is difficult to learn a compact feature space to detect both attacks simultaneously. To address these issues, we collect a Unified physical-digital Attack dataset, called UniAttackData. The dataset consists of $1,800$ participations of 2 and 12 physical and digital attacks, respectively, resulting in a total of 29,706 videos. Then, we propose a Unified Attack Detection framework based on Vision-Language Models (VLMs), namely UniAttackDetection, which includes three main modules: the Teacher-Student Prompts (TSP) module, focused on acquiring unified and specific knowledge respectively; the Unified Knowledge Mining (UKM) module, designed to capture a comprehensive feature space; and the Sample-Level Prompt Interaction (SLPI) module, aimed at grasping sample-level semantics. These three modules seamlessly form a robust unified attack detection framework. Extensive experiments on UniAttackData and three other datasets demonstrate the superiority of our approach for unified face attack detection.