 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Physical-Digital Face Attack Detection
Paper and Code
Jan 31, 2024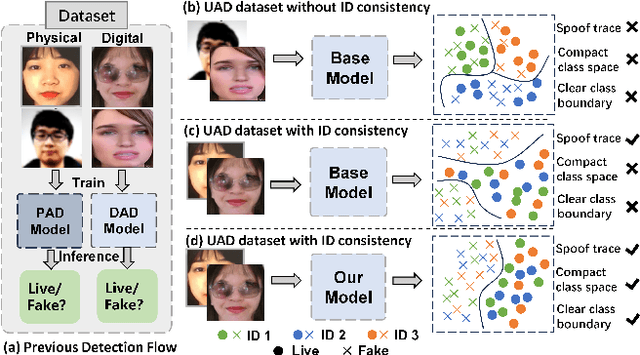
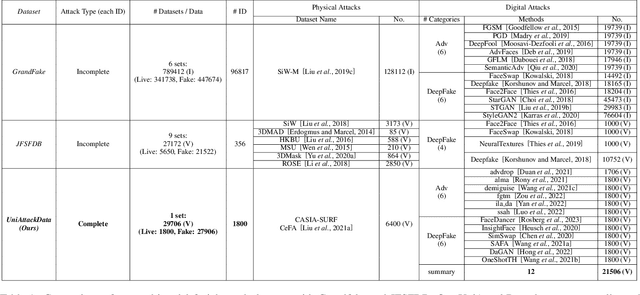
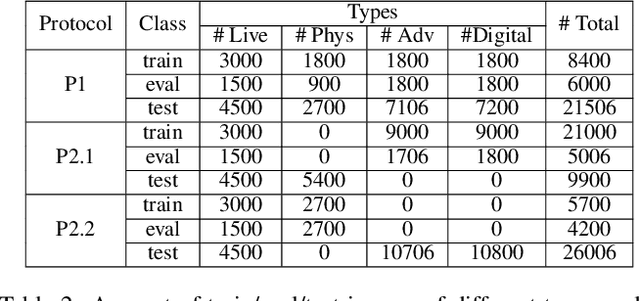

Face Recognition (FR) systems can suffer from physical (i.e., print photo) and digital (i.e., DeepFake) attacks. However, previous related work rarely considers both situations at the same time. This implies the deployment of multiple models and thus more computational burden. The main reasons for this lack of an integrated model are caused by two factors: (1) The lack of a dataset including both physical and digital attacks with ID consistency which means the same ID covers the real face and all attack types; (2) Given the large intra-class variance between these two attacks, it is difficult to learn a compact feature space to detect both attacks simultaneously. To address these issues, we collect a Unified physical-digital Attack dataset, called UniAttackData. The dataset consists of $1,800$ participations of 2 and 12 physical and digital attacks, respectively, resulting in a total of 29,706 videos. Then, we propose a Unified Attack Detection framework based on Vision-Language Models (VLMs), namely UniAttackDetection, which includes three main modules: the Teacher-Student Prompts (TSP) module, focused on acquiring unified and specific knowledge respectively; the Unified Knowledge Mining (UKM) module, designed to capture a comprehensive feature space; and the Sample-Level Prompt Interaction (SLPI) module, aimed at grasping sample-level semantics. These three modules seamlessly form a robust unified attack detection framework. Extensive experiments on UniAttackData and three other datasets demonstrate the superiority of our approach for unified face attack detection.