 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Attack-Experts with Class Regularization for Unified Physical-Digital Face Attack Detection
Apr 01, 2025Facial recognition systems in real-world scenarios are susceptible to both digital and physical attacks. Previous methods have attempted to achieve classification by learning a comprehensive feature space. However, these methods have not adequately accounted for the inherent characteristics of physical and digital attack data, particularly the large intra class variation in attacks and the small inter-class variation between live and fake faces. To address these limitations, we propose the Fine-Grained MoE with Class-Aware Regularization CLIP framework (FG-MoE-CLIP-CAR), incorporating key improvements at both the feature and loss levels. At the feature level, we employ a Soft Mixture of Experts (Soft MoE) architecture to leverage different experts for specialized feature processing. Additionally, we refine the Soft MoE to capture more subtle differences among various types of fake faces. At the loss level, we introduce two constraint modules: the Disentanglement Module (DM) and the Cluster Distillation Module (CDM). The DM enhances class separability by increasing the distance between the centers of live and fake face classes. However, center-to-center constraints alone are insufficient to ensure distinctive representations for individual features. Thus, we propose the CDM to further cluster features around their respective class centers while maintaining separation from other classes. Moreover, specific attacks that significantly deviate from common attack patterns are often overlooked. To address this issue, our distance calculation prioritizes more distant features. Experimental results on two unified physical-digital attack datasets demonstrate that the proposed method achieves state-of-the-art (SOTA) performance.
Unified Physical-Digital Attack Detection Challenge
Apr 09, 2024Face Anti-Spoofing (FAS) is crucial to safeguard Face Recognition (FR) Systems. In real-world scenarios, FRs are confronted with both physical and digital attacks. However, existing algorithms often address only one type of attack at a time, which poses significant limitations in real-world scenarios where FR systems face hybrid physical-digital threats. To facilitate the research of Unified Attack Detection (UAD) algorithms, a large-scale UniAttackData dataset has been collected. UniAttackData is the largest public dataset for Unified Attack Detection, with a total of 28,706 videos, where each unique identity encompasses all advanced attack types. Based on this dataset, we organized a Unified Physical-Digital Face Attack Detection Challenge to boost the research in Unified Attack Detections. It attracted 136 teams for the development phase, with 13 qualifying for the final round. The results re-verified by the organizing team were used for the final ranking. This paper comprehensively reviews the challenge, detailing the dataset introduction, protocol definition, evaluation criteria, and a summary of published results. Finally, we focus on the detailed analysis of the highest-performing algorithms and offer potential directions for unified physical-digital attack detection inspired by this competition. Challenge Website: https://sites.google.com/view/face-anti-spoofing-challenge/welcome/challengecvpr2024.
Unified Physical-Digital Face Attack Detection
Jan 31, 2024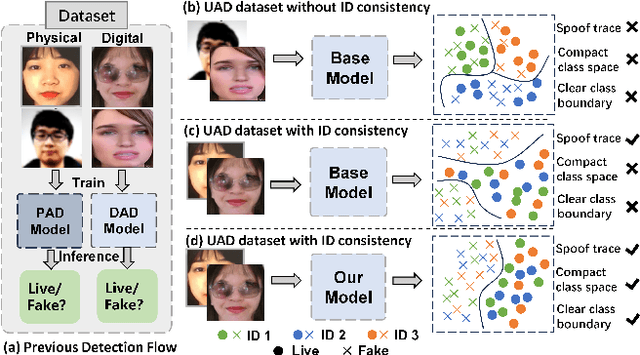
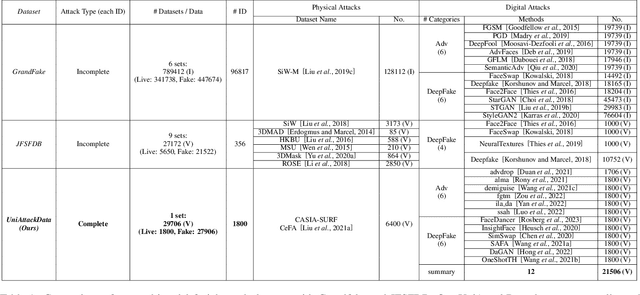
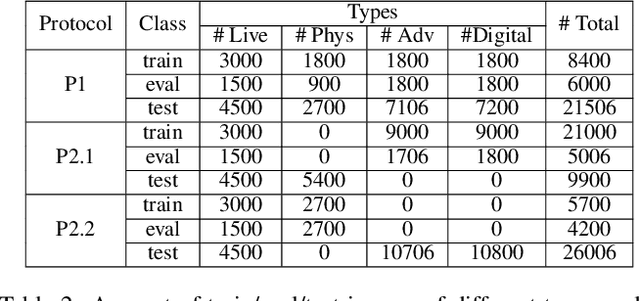

Face Recognition (FR) systems can suffer from physical (i.e., print photo) and digital (i.e., DeepFake) attacks. However, previous related work rarely considers both situations at the same time. This implies the deployment of multiple models and thus more computational burden. The main reasons for this lack of an integrated model are caused by two factors: (1) The lack of a dataset including both physical and digital attacks with ID consistency which means the same ID covers the real face and all attack types; (2) Given the large intra-class variance between these two attacks, it is difficult to learn a compact feature space to detect both attacks simultaneously. To address these issues, we collect a Unified physical-digital Attack dataset, called UniAttackData. The dataset consists of $1,800$ participations of 2 and 12 physical and digital attacks, respectively, resulting in a total of 29,706 videos. Then, we propose a Unified Attack Detection framework based on Vision-Language Models (VLMs), namely UniAttackDetection, which includes three main modules: the Teacher-Student Prompts (TSP) module, focused on acquiring unified and specific knowledge respectively; the Unified Knowledge Mining (UKM) module, designed to capture a comprehensive feature space; and the Sample-Level Prompt Interaction (SLPI) module, aimed at grasping sample-level semantics. These three modules seamlessly form a robust unified attack detection framework. Extensive experiments on UniAttackData and three other datasets demonstrate the superiority of our approach for unified face attack detection.