 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Meta-Album: Group-bias injection with style transfer to study robustness against distribution shifts
Dec 10, 2025We introduce Stylized Meta-Album (SMA), a new image classification meta-dataset comprising 24 datasets (12 content datasets, and 12 stylized datasets), designed to advance studies on out-of-distribution (OOD) generalization and related topics. Created using style transfer techniques from 12 subject classification datasets, SMA provides a diverse and extensive set of 4800 groups, combining various subjects (objects, plants, animals, human actions, textures) with multiple styles. SMA enables flexible control over groups and classes, allowing us to configure datasets to reflect diverse benchmark scenarios. While ideally, data collection would capture extensive group diversity, practical constraints often make this infeasible. SMA addresses this by enabling large and configurable group structures through flexible control over styles, subject classes, and domains-allowing datasets to reflect a wide range of real-world benchmark scenarios. This design not only expands group and class diversity, but also opens new methodological directions for evaluating model performance across diverse group and domain configurations-including scenarios with many minority groups, varying group imbalance, and complex domain shifts-and for studying fairness, robustness, and adaptation under a broader range of realistic conditions. To demonstrate SMA's effectiveness, we implemented two benchmarks: (1) a novel OOD generalization and group fairness benchmark leveraging SMA's domain, class, and group diversity to evaluate existing benchmarks. Our findings reveal that while simple balancing and algorithms utilizing group information remain competitive as claimed in previous benchmarks, increasing group diversity significantly impacts fairness, altering the superiority and relative rankings of algorithms. We also propose to use \textit{Top-M worst group accuracy} as a new hyperparameter tuning metric, demonstrating broader fairness during optimization and delivering better final worst-group accuracy for larger group diversity. (2) An unsupervised domain adaptation (UDA) benchmark utilizing SMA's group diversity to evaluate UDA algorithms across more scenarios, offering a more comprehensive benchmark with lower error bars (reduced by 73\% and 28\% in closed-set setting and UniDA setting, respectively) compared to existing efforts. These use cases highlight SMA's potential to significantly impact the outcomes of conventional benchmarks.
EEG Foundation Challenge: From Cross-Task to Cross-Subject EEG Decoding
Jun 23, 2025Current electroencephalogram (EEG) decoding models are typically trained on small numbers of subjects performing a single task. Here, we introduce a large-scale, code-submission-based competition comprising two challenges. First, the Transfer Challenge asks participants to build and test a model that can zero-shot decode new tasks and new subjects from their EEG data. Second, the Psychopathology factor prediction Challenge asks participants to infer subject measures of mental health from EEG data. For this, we use an unprecedented, multi-terabyte dataset of high-density EEG signals (128 channels) recorded from over 3,000 child to young adult subjects engaged in multiple active and passive tasks. We provide several tunable neural network baselines for each of these two challenges, including a simple network and demographic-based regression models. Developing models that generalise across tasks and individuals will pave the way for ML network architectures capable of adapting to EEG data collected from diverse tasks and individuals. Similarly, predicting mental health-relevant personality trait values from EEG might identify objective biomarkers useful for clinical diagnosis and design of personalised treatment for psychological conditions. Ultimately, the advances spurred by this challenge could contribute to the development of computational psychiatry and useful neurotechnology, and contribute to breakthroughs in both fundamental neuroscience and applied clinical research.
* Approved at Neurips Competition track. webpage: https://eeg2025.github.io/
Usefulness of LLMs as an Author Checklist Assistant for Scientific Papers: NeurIPS'24 Experiment
Nov 05, 2024
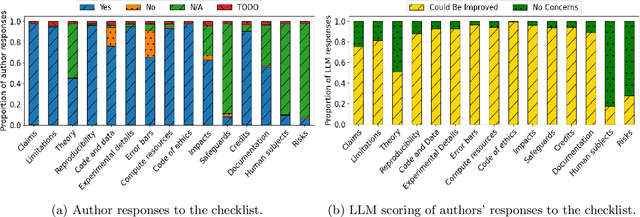
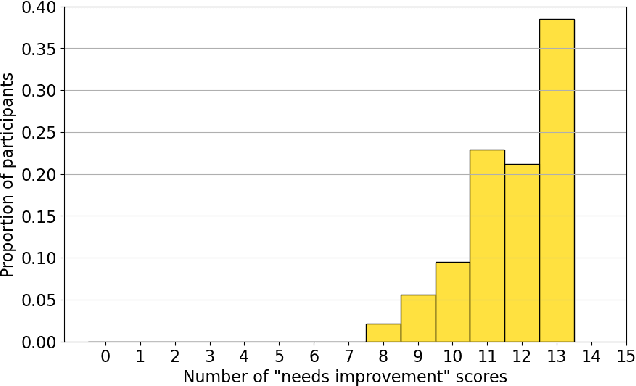

Large language models (LLMs) represent a promising, but controversial, tool in aiding scientific peer review. This study evaluates the usefulness of LLMs in a conference setting as a tool for vetting paper submissions against submission standards. We conduct an experiment at the 2024 Neural Information Processing Systems (NeurIPS) conference, where 234 papers were voluntarily submitted to an "LLM-based Checklist Assistant." This assistant validates whether papers adhere to the author checklist used by NeurIPS, which includes questions to ensure compliance with research and manuscript preparation standards. Evaluation of the assistant by NeurIPS paper authors suggests that the LLM-based assistant was generally helpful in verifying checklist completion. In post-usage surveys, over 70% of authors found the assistant useful, and 70% indicate that they would revise their papers or checklist responses based on its feedback. While causal attribution to the assistant is not definitive, qualitative evidence suggests that the LLM contributed to improving some submissions. Survey responses and analysis of re-submissions indicate that authors made substantive revisions to their submissions in response to specific feedback from the LLM. The experiment also highlights common issues with LLMs: inaccuracy (20/52) and excessive strictness (14/52) were the most frequent issues flagged by authors. We also conduct experiments to understand potential gaming of the system, which reveal that the assistant could be manipulated to enhance scores through fabricated justifications, highlighting potential vulnerabilities of automated review tools.
Meta-Learning from Learning Curves for Budget-Limited Algorithm Selection
Oct 10, 2024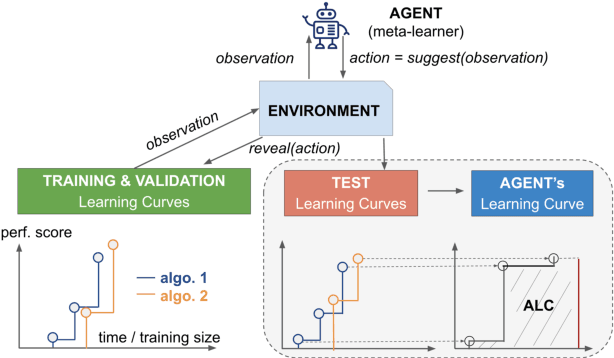
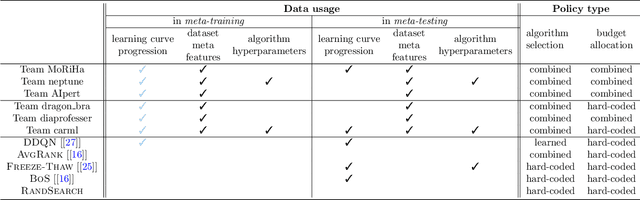
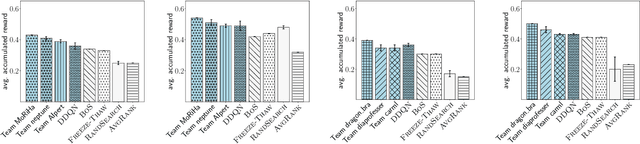
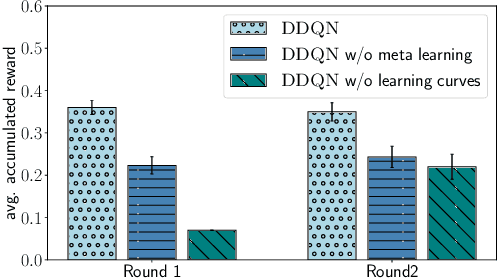
Training a large set of machine learning algorithms to convergence in order to select the best-performing algorithm for a dataset is computationally wasteful. Moreover, in a budget-limited scenario, it is crucial to carefully select an algorithm candidate and allocate a budget for training it, ensuring that the limited budget is optimally distributed to favor the most promising candidates. Casting this problem as a Markov Decision Process, we propose a novel framework in which an agent must select in the process of learning the most promising algorithm without waiting until it is fully trained. At each time step, given an observation of partial learning curves of algorithms, the agent must decide whether to allocate resources to further train the most promising algorithm (exploitation), to wake up another algorithm previously put to sleep, or to start training a new algorithm (exploration). In addition, our framework allows the agent to meta-learn from learning curves on past datasets along with dataset meta-features and algorithm hyperparameters. By incorporating meta-learning, we aim to avoid myopic decisions based solely on premature learning curves on the dataset at hand. We introduce two benchmarks of learning curves that served in international competitions at WCCI'22 and AutoML-conf'22, of which we analyze the results. Our findings show that both meta-learning and the progression of learning curves enhance the algorithm selection process, as evidenced by methods of winning teams and our DDQN baseline, compared to heuristic baselines or a random search. Interestingly, our cost-effective baseline, which selects the best-performing algorithm w.r.t. a small budget, can perform decently when learning curves do not intersect frequently.
FAIR Universe HiggsML Uncertainty Challenge Competition
Oct 03, 2024
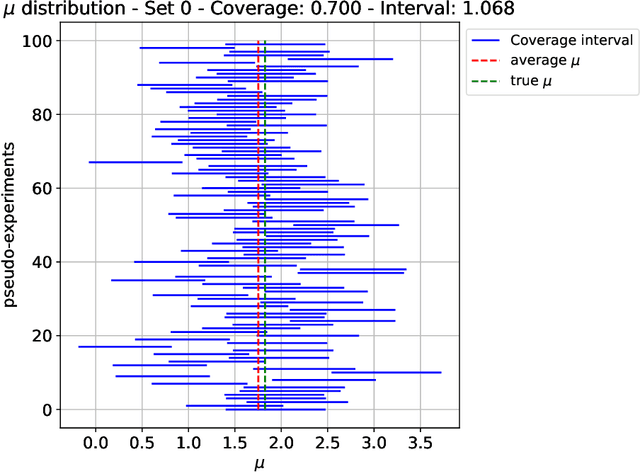
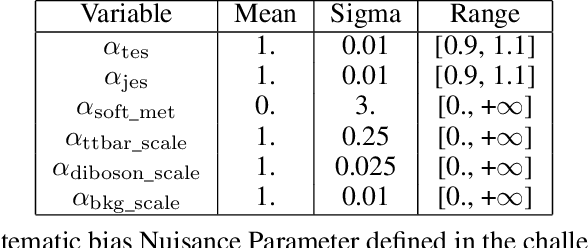
The FAIR Universe -- HiggsML Uncertainty Challenge focuses on measuring the physics properties of elementary particles with imperfect simulators due to differences in modelling systematic errors. Additionally, the challenge is leveraging a large-compute-scale AI platform for sharing datasets, training models, and hosting machine learning competitions. Our challenge brings together the physics and machine learning communities to advance our understanding and methodologies in handling systematic (epistemic) uncertainties within AI techniques.
Are we making progress in unlearning? Findings from the first NeurIPS unlearning competition
Jun 13, 2024



We present the findings of the first NeurIPS competition on unlearning, which sought to stimulate the development of novel algorithms and initiate discussions on formal and robust evaluation methodologies. The competition was highly successful: nearly 1,200 teams from across the world participated, and a wealth of novel, imaginative solutions with different characteristics were contributed. In this paper, we analyze top solutions and delve into discussions on benchmarking unlearning, which itself is a research problem. The evaluation methodology we developed for the competition measures forgetting quality according to a formal notion of unlearning, while incorporating model utility for a holistic evaluation. We analyze the effectiveness of different instantiations of this evaluation framework vis-a-vis the associated compute cost, and discuss implications for standardizing evaluation. We find that the ranking of leading methods remains stable under several variations of this framework, pointing to avenues for reducing the cost of evaluation. Overall, our findings indicate progress in unlearning, with top-performing competition entries surpassing existing algorithms under our evaluation framework. We analyze trade-offs made by different algorithms and strengths or weaknesses in terms of generalizability to new datasets, paving the way for advancing both benchmarking and algorithm development in this important area.
AI Competitions and Benchmarks: Dataset Development
Apr 15, 2024



Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Unified Physical-Digital Attack Detection Challenge
Apr 09, 2024Face Anti-Spoofing (FAS) is crucial to safeguard Face Recognition (FR) Systems. In real-world scenarios, FRs are confronted with both physical and digital attacks. However, existing algorithms often address only one type of attack at a time, which poses significant limitations in real-world scenarios where FR systems face hybrid physical-digital threats. To facilitate the research of Unified Attack Detection (UAD) algorithms, a large-scale UniAttackData dataset has been collected. UniAttackData is the largest public dataset for Unified Attack Detection, with a total of 28,706 videos, where each unique identity encompasses all advanced attack types. Based on this dataset, we organized a Unified Physical-Digital Face Attack Detection Challenge to boost the research in Unified Attack Detections. It attracted 136 teams for the development phase, with 13 qualifying for the final round. The results re-verified by the organizing team were used for the final ranking. This paper comprehensively reviews the challenge, detailing the dataset introduction, protocol definition, evaluation criteria, and a summary of published results. Finally, we focus on the detailed analysis of the highest-performing algorithms and offer potential directions for unified physical-digital attack detection inspired by this competition. Challenge Website: https://sites.google.com/view/face-anti-spoofing-challenge/welcome/challengecvpr2024.
Challenge design roadmap
Jan 15, 2024Challenges can be seen as a type of game that motivates participants to solve serious tasks. As a result, competition organizers must develop effective game rules. However, these rules have multiple objectives beyond making the game enjoyable for participants. These objectives may include solving real-world problems, advancing scientific or technical areas, making scientific discoveries, and educating the public. In many ways, creating a challenge is similar to launching a product. It requires the same level of excitement and rigorous testing, and the goal is to attract ''customers'' in the form of participants. The process begins with a solid plan, such as a competition proposal that will eventually be submitted to an international conference and subjected to peer review. Although peer review does not guarantee quality, it does force organizers to consider the impact of their challenge, identify potential oversights, and generally improve its quality. This chapter provides guidelines for creating a strong plan for a challenge. The material draws on the preparation guidelines from organizations such as Kaggle 1 , ChaLearn 2 and Tailor 3 , as well as the NeurIPS proposal template, which some of the authors contributed to.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.