 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation learning from OCT images
May 04, 2026Optical Coherence Tomography (OCT) has become one of the most used imaging modality in ophthalmology. It provides high-resolution, non-invasive visualization of retinal microarchitecture. The automated analysis of OCT images through representation learning has emerged as a central research frontier. This has mainly been driven by the clinical need to process large acquisition volumes. The objective is to reduce the reliance on expert annotation, and improve diagnostic consistency across devices and populations. This survey provides a comprehensive and structured review of representation learning methods for retinal OCT image analysis. It covers the period from early deep learning approaches to the most recent developments in foundation models and vision-language systems. We organize the literature along a principled taxonomy of learning paradigms, encompassing supervised learning with CNN-based and transformer-based architectures, self-supervised and semi-supervised methods, generative approaches, as well as 3D volumetric modeling, multimodal representation learning, and large-scale pretrained foundation models. For each paradigm, we analyze the core methodological contributions, identify persistent limitations, and trace the connections between successive approaches. We further provide a structured overview of publicly available OCT datasets, discuss evaluation protocol considerations, and present a unified problem formulation that situates each learning paradigm within a common mathematical framework. Building on this analysis, we identify and discuss the most pressing open research directions emerging in the literature. This includes volumetric foundation model pretraining, uncertainty-aware representation learning, federated and privacy-preserving training, fairness and bias mitigation, concept-based interpretability,...
Accurate online action and gesture recognition system using detectors and Deep SPD Siamese Networks
Nov 07, 2025Online continuous motion recognition is a hot topic of research since it is more practical in real life application cases. Recently, Skeleton-based approaches have become increasingly popular, demonstrating the power of using such 3D temporal data. However, most of these works have focused on segment-based recognition and are not suitable for the online scenarios. In this paper, we propose an online recognition system for skeleton sequence streaming composed from two main components: a detector and a classifier, which use a Semi-Positive Definite (SPD) matrix representation and a Siamese network. The powerful statistical representations for the skeletal data given by the SPD matrices and the learning of their semantic similarity by the Siamese network enable the detector to predict time intervals of the motions throughout an unsegmented sequence. In addition, they ensure the classifier capability to recognize the motion in each predicted interval. The proposed detector is flexible and able to identify the kinetic state continuously. We conduct extensive experiments on both hand gesture and body action recognition benchmarks to prove the accuracy of our online recognition system which in most cases outperforms state-of-the-art performances.
Text-driven Motion Generation: Overview, Challenges and Directions
May 14, 2025

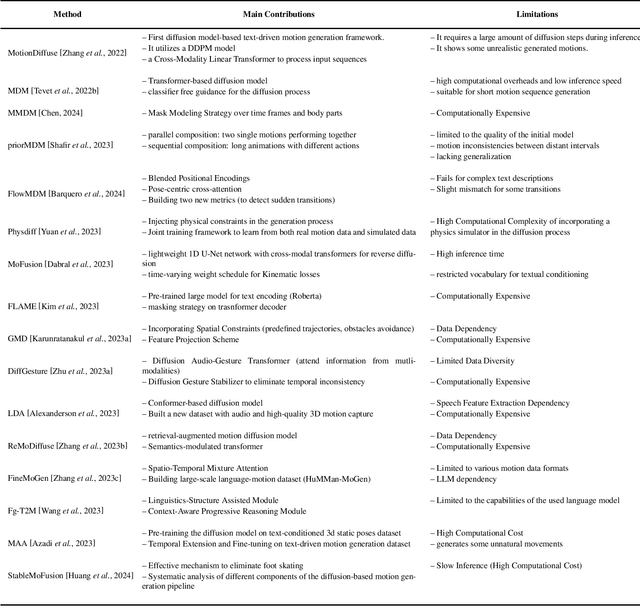

Text-driven motion generation offers a powerful and intuitive way to create human movements directly from natural language. By removing the need for predefined motion inputs, it provides a flexible and accessible approach to controlling animated characters. This makes it especially useful in areas like virtual reality, gaming, human-computer interaction, and robotics. In this review, we first revisit the traditional perspective on motion synthesis, where models focused on predicting future poses from observed initial sequences, often conditioned on action labels. We then provide a comprehensive and structured survey of modern text-to-motion generation approaches, categorizing them from two complementary perspectives: (i) architectural, dividing methods into VAE-based, diffusion-based, and hybrid models; and (ii) motion representation, distinguishing between discrete and continuous motion generation strategies. In addition, we explore the most widely used datasets, evaluation methods, and recent benchmarks that have shaped progress in this area. With this survey, we aim to capture where the field currently stands, bring attention to its key challenges and limitations, and highlight promising directions for future exploration. We hope this work offers a valuable starting point for researchers and practitioners working to push the boundaries of language-driven human motion synthesis.
Beyond Pruning Criteria: The Dominant Role of Fine-Tuning and Adaptive Ratios in Neural Network Robustness
Oct 19, 2024
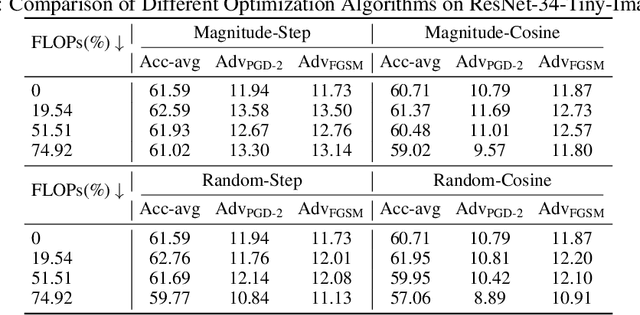

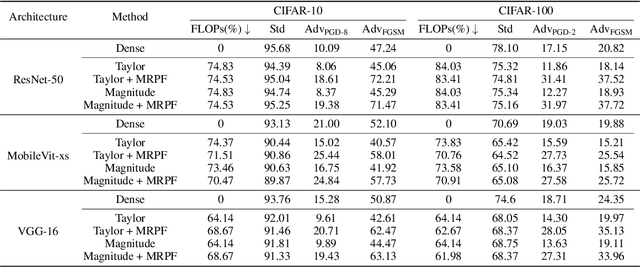
Deep neural networks (DNNs) excel in tasks like image recognition and natural language processing, but their increasing complexity complicates deployment in resource-constrained environments and increases susceptibility to adversarial attacks. While traditional pruning methods reduce model size, they often compromise the network's ability to withstand subtle perturbations. This paper challenges the conventional emphasis on weight importance scoring as the primary determinant of a pruned network's performance. Through extensive analysis, including experiments conducted on CIFAR, Tiny-ImageNet, and various network architectures, we demonstrate that effective fine-tuning plays a dominant role in enhancing both performance and adversarial robustness, often surpassing the impact of the chosen pruning criteria. To address this issue, we introduce Module Robust Sensitivity, a novel metric that adaptively adjusts the pruning ratio for each network layer based on its sensitivity to adversarial perturbations. By integrating this metric into the pruning process, we develop a stable algorithm that maintains accuracy and robustness simultaneously. Experimental results show that our approach enables the practical deployment of more robust and efficient neural networks.
RRR-Net: Reusing, Reducing, and Recycling a Deep Backbone Network
Oct 02, 2023



It has become mainstream in computer vision and other machine learning domains to reuse backbone networks pre-trained on large datasets as preprocessors. Typically, the last layer is replaced by a shallow learning machine of sorts; the newly-added classification head and (optionally) deeper layers are fine-tuned on a new task. Due to its strong performance and simplicity, a common pre-trained backbone network is ResNet152.However, ResNet152 is relatively large and induces inference latency. In many cases, a compact and efficient backbone with similar performance would be preferable over a larger, slower one. This paper investigates techniques to reuse a pre-trained backbone with the objective of creating a smaller and faster model. Starting from a large ResNet152 backbone pre-trained on ImageNet, we first reduce it from 51 blocks to 5 blocks, reducing its number of parameters and FLOPs by more than 6 times, without significant performance degradation. Then, we split the model after 3 blocks into several branches, while preserving the same number of parameters and FLOPs, to create an ensemble of sub-networks to improve performance. Our experiments on a large benchmark of $40$ image classification datasets from various domains suggest that our techniques match the performance (if not better) of ``classical backbone fine-tuning'' while achieving a smaller model size and faster inference speed.
Efficient Automation of Neural Network Design: A Survey on Differentiable Neural Architecture Search
May 01, 2023



In the past few years, Differentiable Neural Architecture Search (DNAS) rapidly imposed itself as the trending approach to automate the discovery of deep neural network architectures. This rise is mainly due to the popularity of DARTS, one of the first major DNAS methods. In contrast with previous works based on Reinforcement Learning or Evolutionary Algorithms, DNAS is faster by several orders of magnitude and uses fewer computational resources. In this comprehensive survey, we focus specifically on DNAS and review recent approaches in this field. Furthermore, we propose a novel challenge-based taxonomy to classify DNAS methods. We also discuss the contributions brought to DNAS in the past few years and its impact on the global NAS field. Finally, we conclude by giving some insights into future research directions for the DNAS field.
Kernel function impact on convolutional neural networks
Feb 20, 2023This paper investigates the usage of kernel functions at the different layers in a convolutional neural network. We carry out extensive studies of their impact on convolutional, pooling and fully-connected layers. We notice that the linear kernel may not be sufficiently effective to fit the input data distributions, whereas high order kernels prone to over-fitting. This leads to conclude that a trade-off between complexity and performance should be reached. We show how one can effectively leverage kernel functions, by introducing a more distortion aware pooling layers which reduces over-fitting while keeping track of the majority of the information fed into subsequent layers. We further propose Kernelized Dense Layers (KDL), which replace fully-connected layers, and capture higher order feature interactions. The experiments on conventional classification datasets i.e. MNIST, FASHION-MNIST and CIFAR-10, show that the proposed techniques improve the performance of the network compared to classical convolution, pooling and fully connected layers. Moreover, experiments on fine-grained classification i.e. facial expression databases, namely RAF-DB, FER2013 and ExpW demonstrate that the discriminative power of the network is boosted, since the proposed techniques improve the awareness to slight visual details and allows the network reaching state-of-the-art results.
Alphazzle: Jigsaw Puzzle Solver with Deep Monte-Carlo Tree Search
Feb 01, 2023



Solving jigsaw puzzles requires to grasp the visual features of a sequence of patches and to explore efficiently a solution space that grows exponentially with the sequence length. Therefore, visual deep reinforcement learning (DRL) should answer this problem more efficiently than optimization solvers coupled with neural networks. Based on this assumption, we introduce Alphazzle, a reassembly algorithm based on single-player Monte Carlo Tree Search (MCTS). A major difference with DRL algorithms lies in the unavailability of game reward for MCTS, and we show how to estimate it from the visual input with neural networks. This constraint is induced by the puzzle-solving task and dramatically adds to the task complexity (and interest!). We perform an in-deep ablation study that shows the importance of MCTS and the neural networks working together. We achieve excellent results and get exciting insights into the combination of DRL and visual feature learning.
NASiam: Efficient Representation Learning using Neural Architecture Search for Siamese Networks
Jan 31, 2023



Siamese networks are one of the most trending methods to achieve self-supervised visual representation learning (SSL). Since hand labeling is costly, SSL can play a crucial part by allowing deep learning to train on large unlabeled datasets. Meanwhile, Neural Architecture Search (NAS) is becoming increasingly important as a technique to discover novel deep learning architectures. However, early NAS methods based on reinforcement learning or evolutionary algorithms suffered from ludicrous computational and memory costs. In contrast, differentiable NAS, a gradient-based approach, has the advantage of being much more efficient and has thus retained most of the attention in the past few years. In this article, we present NASiam, a novel approach that uses for the first time differentiable NAS to improve the multilayer perceptron projector and predictor (encoder/predictor pair) architectures inside siamese-networks-based contrastive learning frameworks (e.g., SimCLR, SimSiam, and MoCo) while preserving the simplicity of previous baselines. We crafted a search space designed explicitly for multilayer perceptrons, inside which we explored several alternatives to the standard ReLU activation function. We show that these new architectures allow ResNet backbone convolutional models to learn strong representations efficiently. NASiam reaches competitive performance in both small-scale (i.e., CIFAR-10/CIFAR-100) and large-scale (i.e., ImageNet) image classification datasets while costing only a few GPU hours. We discuss the composition of the NAS-discovered architectures and emit hypotheses on why they manage to prevent collapsing behavior. Our code is available at https://github.com/aheuillet/NASiam.
Learnable Triangulation for Deep Learning-based 3D Reconstruction of Objects of Arbitrary Topology from Single RGB Images
Sep 24, 2021
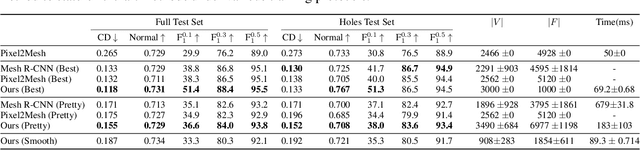
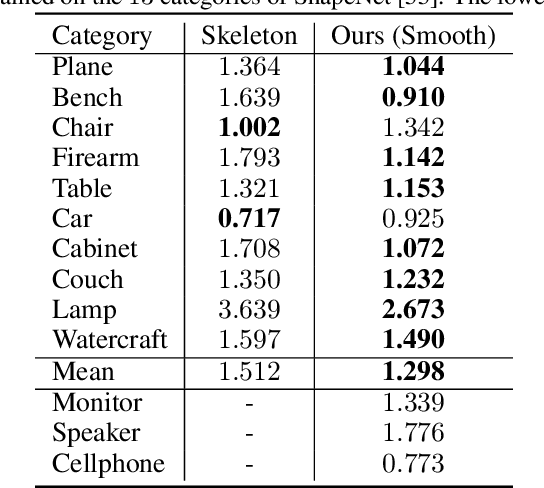

We propose a novel deep reinforcement learning-based approach for 3D object reconstruction from monocular images. Prior works that use mesh representations are template based. Thus, they are limited to the reconstruction of objects that have the same topology as the template. Methods that use volumetric grids as intermediate representations are computationally expensive, which limits their application in real-time scenarios. In this paper, we propose a novel end-to-end method that reconstructs 3D objects of arbitrary topology from a monocular image. It is composed of of (1) a Vertex Generation Network (VGN), which predicts the initial 3D locations of the object's vertices from an input RGB image, (2) a differentiable triangulation layer, which learns in a non-supervised manner, using a novel reinforcement learning algorithm, the best triangulation of the object's vertices, and finally, (3) a hierarchical mesh refinement network that uses graph convolutions to refine the initial mesh. Our key contribution is the learnable triangulation process, which recovers in an unsupervised manner the topology of the input shape. Our experiments on ShapeNet and Pix3D benchmarks show that the proposed method outperforms the state-of-the-art in terms of visual quality, reconstruction accuracy, and computational time.