 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphazzle: Jigsaw Puzzle Solver with Deep Monte-Carlo Tree Search
Feb 01, 2023



Solving jigsaw puzzles requires to grasp the visual features of a sequence of patches and to explore efficiently a solution space that grows exponentially with the sequence length. Therefore, visual deep reinforcement learning (DRL) should answer this problem more efficiently than optimization solvers coupled with neural networks. Based on this assumption, we introduce Alphazzle, a reassembly algorithm based on single-player Monte Carlo Tree Search (MCTS). A major difference with DRL algorithms lies in the unavailability of game reward for MCTS, and we show how to estimate it from the visual input with neural networks. This constraint is induced by the puzzle-solving task and dramatically adds to the task complexity (and interest!). We perform an in-deep ablation study that shows the importance of MCTS and the neural networks working together. We achieve excellent results and get exciting insights into the combination of DRL and visual feature learning.
Deepzzle: Solving Visual Jigsaw Puzzles with Deep Learning andShortest Path Optimization
May 26, 2020
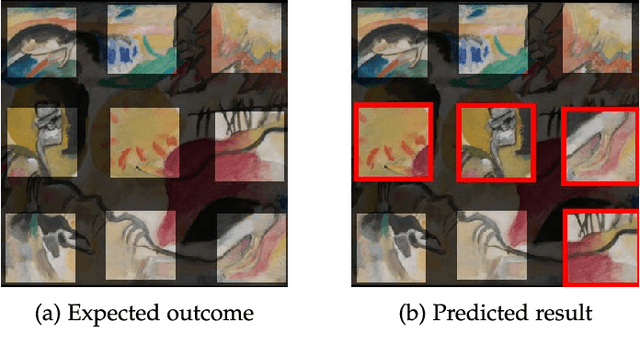


We tackle the image reassembly problem with wide space between the fragments, in such a way that the patterns and colors continuity is mostly unusable. The spacing emulates the erosion of which the archaeological fragments suffer. We crop-square the fragments borders to compel our algorithm to learn from the content of the fragments. We also complicate the image reassembly by removing fragments and adding pieces from other sources. We use a two-step method to obtain the reassemblies: 1) a neural network predicts the positions of the fragments despite the gaps between them; 2) a graph that leads to the best reassemblies is made from these predictions. In this paper, we notably investigate the effect of branch-cut in the graph of reassemblies. We also provide a comparison with the literature, solve complex images reassemblies, explore at length the dataset, and propose a new metric that suits its specificities. Keywords: image reassembly, jigsaw puzzle, deep learning, graph, branch-cut, cultural heritage
Jigsaw Puzzle Solving Using Local Feature Co-Occurrences in Deep Neural Networks
Jul 05, 2018
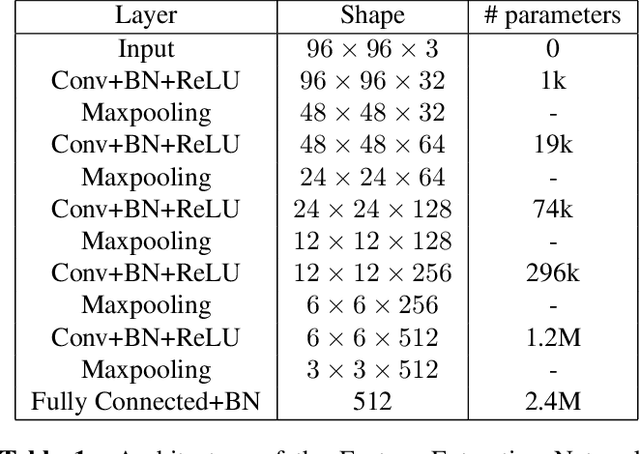

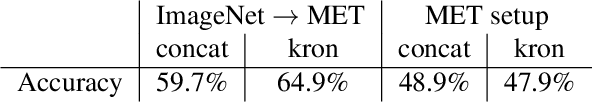
Archaeologists are in dire need of automated object reconstruction methods. Fragments reassembly is close to puzzle problems, which may be solved by computer vision algorithms. As they are often beaten on most image related tasks by deep learning algorithms, we study a classification method that can solve jigsaw puzzles. In this paper, we focus on classifying the relative position: given a couple of fragments, we compute their local relation (e.g. on top). We propose several enhancements over the state of the art in this domain, which is outperformed by our method by 25\%. We propose an original dataset composed of pictures from the Metropolitan Museum of Art. We propose a greedy reconstruction method based on the predicted relative positions.