 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne View Is Enough! Monocular Training for In-the-Wild Novel View Generation
Mar 24, 2026Monocular novel-view synthesis has long required multi-view image pairs for supervision, limiting training data scale and diversity. We argue it is not necessary: one view is enough. We present OVIE, trained entirely on unpaired internet images. We leverage a monocular depth estimator as a geometric scaffold at training time: we lift a source image into 3D, apply a sampled camera transformation, and project to obtain a pseudo-target view. To handle disocclusions, we introduce a masked training formulation that restricts geometric, perceptual, and textural losses to valid regions, enabling training on 30 million uncurated images. At inference, OVIE is geometry-free, requiring no depth estimator or 3D representation. Trained exclusively on in-the-wild images, OVIE outperforms prior methods in a zero-shot setting, while being 600x faster than the second-best baseline. Code and models are publicly available at https://github.com/AdrienRR/ovie.
Polynomial Mixing for Efficient Self-supervised Speech Encoders
Feb 28, 2026State-of-the-art speech-to-text models typically employ Transformer-based encoders that model token dependencies via self-attention mechanisms. However, the quadratic complexity of self-attention in both memory and computation imposes significant constraints on scalability. In this work, we propose a novel token-mixing mechanism, the Polynomial Mixer (PoM), as a drop-in replacement for multi-head self-attention. PoM computes a polynomial representation of the input with linear complexity with respect to the input sequence length. We integrate PoM into a self-supervised speech representation learning framework based on BEST-RQ and evaluate its performance on downstream speech recognition tasks. Experimental results demonstrate that PoM achieves a competitive word error rate compared to full self-attention and other linear-complexity alternatives, offering an improved trade-off between performance and efficiency in time and memory.
MIRO: MultI-Reward cOnditioned pretraining improves T2I quality and efficiency
Oct 29, 2025Current text-to-image generative models are trained on large uncurated datasets to enable diverse generation capabilities. However, this does not align well with user preferences. Recently, reward models have been specifically designed to perform post-hoc selection of generated images and align them to a reward, typically user preference. This discarding of informative data together with the optimizing for a single reward tend to harm diversity, semantic fidelity and efficiency. Instead of this post-processing, we propose to condition the model on multiple reward models during training to let the model learn user preferences directly. We show that this not only dramatically improves the visual quality of the generated images but it also significantly speeds up the training. Our proposed method, called MIRO, achieves state-of-the-art performances on the GenEval compositional benchmark and user-preference scores (PickAScore, ImageReward, HPSv2).
Markov Chain Estimation with In-Context Learning
Aug 05, 2025We investigate the capacity of transformers to learn algorithms involving their context while solely being trained using next token prediction. We set up Markov chains with random transition matrices and we train transformers to predict the next token. Matrices used during training and test are different and we show that there is a threshold in transformer size and in training set size above which the model is able to learn to estimate the transition probabilities from its context instead of memorizing the training patterns. Additionally, we show that more involved encoding of the states enables more robust prediction for Markov chains with structures different than those seen during training.
Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation
Dec 09, 2024


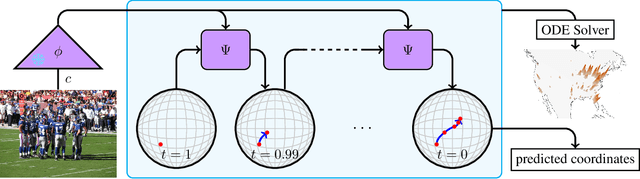
Global visual geolocation predicts where an image was captured on Earth. Since images vary in how precisely they can be localized, this task inherently involves a significant degree of ambiguity. However, existing approaches are deterministic and overlook this aspect. In this paper, we aim to close the gap between traditional geolocalization and modern generative methods. We propose the first generative geolocation approach based on diffusion and Riemannian flow matching, where the denoising process operates directly on the Earth's surface. Our model achieves state-of-the-art performance on three visual geolocation benchmarks: OpenStreetView-5M, YFCC-100M, and iNat21. In addition, we introduce the task of probabilistic visual geolocation, where the model predicts a probability distribution over all possible locations instead of a single point. We introduce new metrics and baselines for this task, demonstrating the advantages of our diffusion-based approach. Codes and models will be made available.
PoM: Efficient Image and Video Generation with the Polynomial Mixer
Nov 19, 2024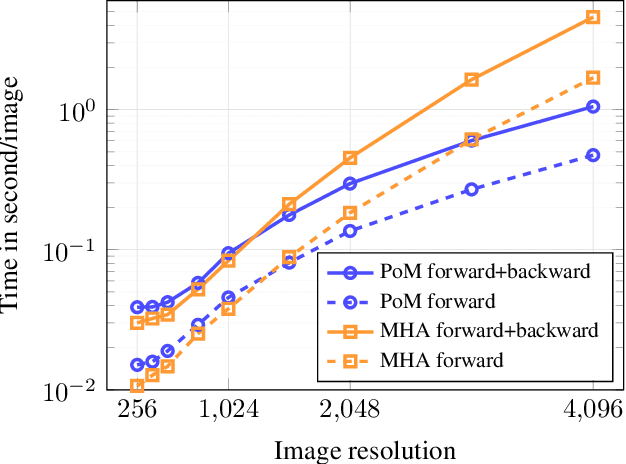
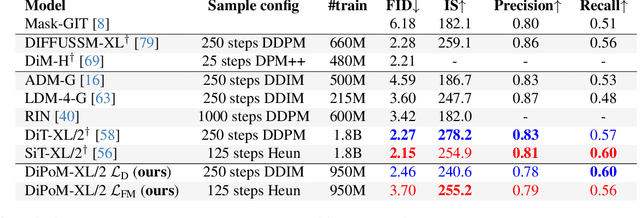
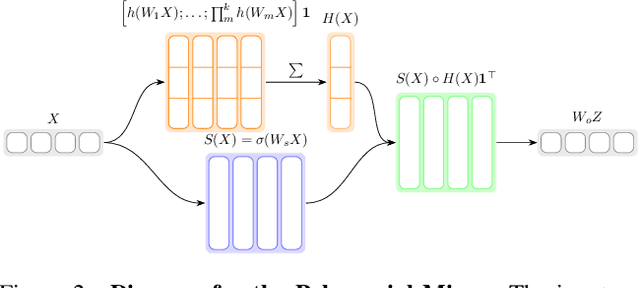

Diffusion models based on Multi-Head Attention (MHA) have become ubiquitous to generate high quality images and videos. However, encoding an image or a video as a sequence of patches results in costly attention patterns, as the requirements both in terms of memory and compute grow quadratically. To alleviate this problem, we propose a drop-in replacement for MHA called the Polynomial Mixer (PoM) that has the benefit of encoding the entire sequence into an explicit state. PoM has a linear complexity with respect to the number of tokens. This explicit state also allows us to generate frames in a sequential fashion, minimizing memory and compute requirement, while still being able to train in parallel. We show the Polynomial Mixer is a universal sequence-to-sequence approximator, just like regular MHA. We adapt several Diffusion Transformers (DiT) for generating images and videos with PoM replacing MHA, and we obtain high quality samples while using less computational resources. The code is available at https://github.com/davidpicard/HoMM.
PAFUSE: Part-based Diffusion for 3D Whole-Body Pose Estimation
Jul 14, 2024We introduce a novel approach for 3D whole-body pose estimation, addressing the challenge of scale- and deformability- variance across body parts brought by the challenge of extending the 17 major joints on the human body to fine-grained keypoints on the face and hands. In addition to addressing the challenge of exploiting motion in unevenly sampled data, we combine stable diffusion to a hierarchical part representation which predicts the relative locations of fine-grained keypoints within each part (e.g., face) with respect to the part's local reference frame. On the H3WB dataset, our method greatly outperforms the current state of the art, which fails to exploit the temporal information. We also show considerable improvements compared to other spatiotemporal 3D human-pose estimation approaches that fail to account for the body part specificities. Code is available at https://github.com/valeoai/PAFUSE.
Don't drop your samples! Coherence-aware training benefits Conditional diffusion
May 30, 2024



Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. We show that CAD is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging coherence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low coherence have been discarded.
Analysis of Classifier-Free Guidance Weight Schedulers
Apr 19, 2024Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances, requiring merely a single line of code. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks.
Multiple Locally Linear Kernel Machines
Jan 17, 2024In this paper we propose a new non-linear classifier based on a combination of locally linear classifiers. A well known optimization formulation is given as we cast the problem in a $\ell_1$ Multiple Kernel Learning (MKL) problem using many locally linear kernels. Since the number of such kernels is huge, we provide a scalable generic MKL training algorithm handling streaming kernels. With respect to the inference time, the resulting classifier fits the gap between high accuracy but slow non-linear classifiers (such as classical MKL) and fast but low accuracy linear classifiers.