 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairer Analysis and Demographically Balanced Face Generation for Fairer Face Verification
Dec 04, 2024Face recognition and verification are two computer vision tasks whose performances have advanced with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive nature of face data and biases in real-world training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems remain. Using the existing DCFace SOTA framework, we introduce a new controlled generation pipeline that improves fairness. Through classical fairness metrics and a proposed in-depth statistical analysis based on logit models and ANOVA, we show that our generation pipeline improves fairness more than other bias mitigation approaches while slightly improving raw performance.
Toward Fairer Face Recognition Datasets
Jun 24, 2024



Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental Learning
Aug 22, 2023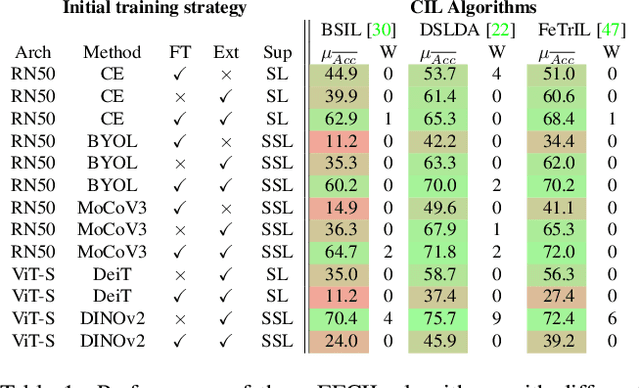
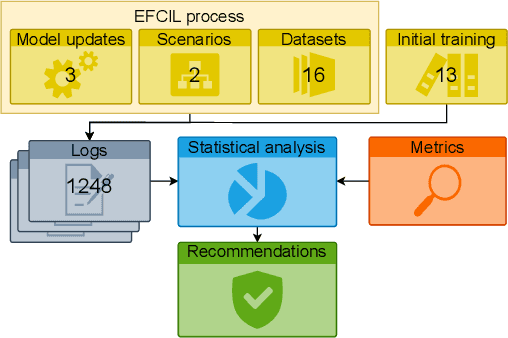

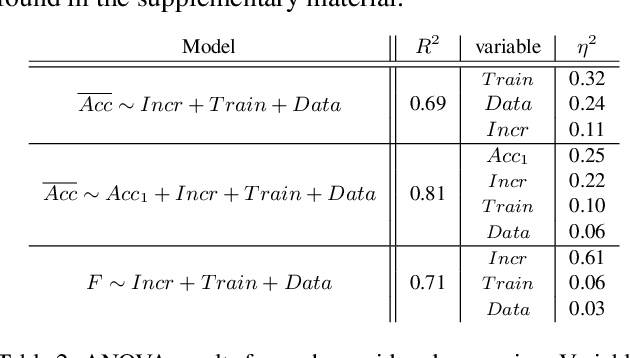
Class-Incremental Learning (CIL) aims to build classification models from data streams. At each step of the CIL process, new classes must be integrated into the model. Due to catastrophic forgetting, CIL is particularly challenging when examples from past classes cannot be stored, the case on which we focus here. To date, most approaches are based exclusively on the target dataset of the CIL process. However, the use of models pre-trained in a self-supervised way on large amounts of data has recently gained momentum. The initial model of the CIL process may only use the first batch of the target dataset, or also use pre-trained weights obtained on an auxiliary dataset. The choice between these two initial learning strategies can significantly influence the performance of the incremental learning model, but has not yet been studied in depth. Performance is also influenced by the choice of the CIL algorithm, the neural architecture, the nature of the target task, the distribution of classes in the stream and the number of examples available for learning. We conduct a comprehensive experimental study to assess the roles of these factors. We present a statistical analysis framework that quantifies the relative contribution of each factor to incremental performance. Our main finding is that the initial training strategy is the dominant factor influencing the average incremental accuracy, but that the choice of CIL algorithm is more important in preventing forgetting. Based on this analysis, we propose practical recommendations for choosing the right initial training strategy for a given incremental learning use case. These recommendations are intended to facilitate the practical deployment of incremental learning.