 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoDFKD: Data-Free Knowledge Distillation for Cardiac Ultrasound Segmentation using Synthetic Data
Sep 11, 2024The application of machine learning to medical ultrasound videos of the heart, i.e., echocardiography, has recently gained traction with the availability of large public datasets. Traditional supervised tasks, such as ejection fraction regression, are now making way for approaches focusing more on the latent structure of data distributions, as well as generative methods. We propose a model trained exclusively by knowledge distillation, either on real or synthetical data, involving retrieving masks suggested by a teacher model. We achieve state-of-the-art (SOTA) values on the task of identifying end-diastolic and end-systolic frames. By training the model only on synthetic data, it reaches segmentation capabilities close to the performance when trained on real data with a significantly reduced number of weights. A comparison with the 5 main existing methods shows that our method outperforms the others in most cases. We also present a new evaluation method that does not require human annotation and instead relies on a large auxiliary model. We show that this method produces scores consistent with those obtained from human annotations. Relying on the integrated knowledge from a vast amount of records, this method overcomes certain inherent limitations of human annotator labeling. Code: https://github.com/GregoirePetit/EchoDFKD
FeTrIL++: Feature Translation for Exemplar-Free Class-Incremental Learning with Hill-Climbing
Mar 12, 2024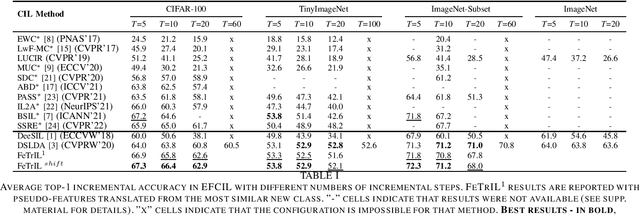
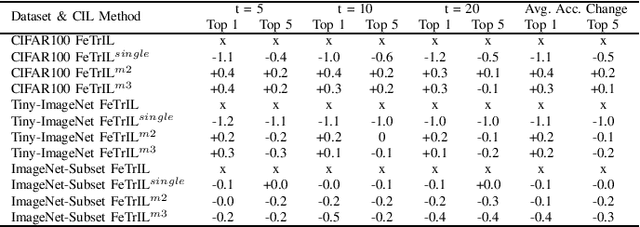
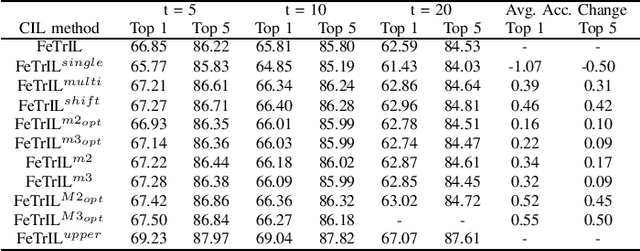
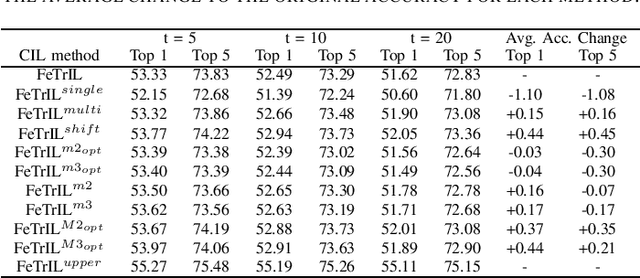
Exemplar-free class-incremental learning (EFCIL) poses significant challenges, primarily due to catastrophic forgetting, necessitating a delicate balance between stability and plasticity to accurately recognize both new and previous classes. Traditional EFCIL approaches typically skew towards either model plasticity through successive fine-tuning or stability by employing a fixed feature extractor beyond the initial incremental state. Building upon the foundational FeTrIL framework, our research extends into novel experimental domains to examine the efficacy of various oversampling techniques and dynamic optimization strategies across multiple challenging datasets and incremental settings. We specifically explore how oversampling impacts accuracy relative to feature availability and how different optimization methodologies, including dynamic recalibration and feature pool diversification, influence incremental learning outcomes. The results from these comprehensive experiments, conducted on CIFAR100, Tiny-ImageNet, and an ImageNet-Subset, under-score the superior performance of FeTrIL in balancing accuracy for both new and past classes against ten contemporary methods. Notably, our extensions reveal the nuanced impacts of oversampling and optimization on EFCIL, contributing to a more refined understanding of feature-space manipulation for class incremental learning. FeTrIL and its extended analysis in this paper FeTrIL++ pave the way for more adaptable and efficient EFCIL methodologies, promising significant improvements in handling catastrophic forgetting without the need for exemplars.
An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental Learning
Aug 22, 2023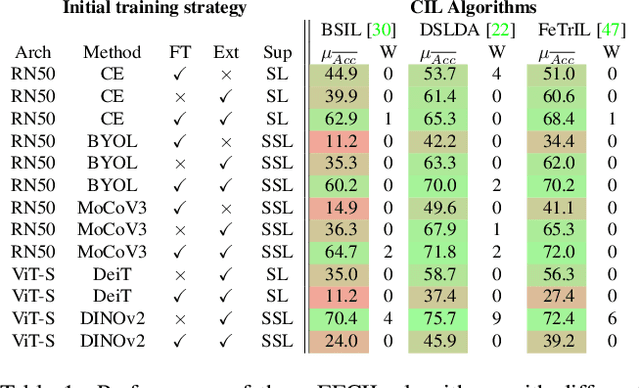
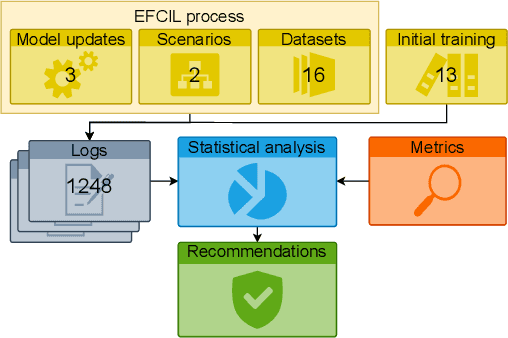

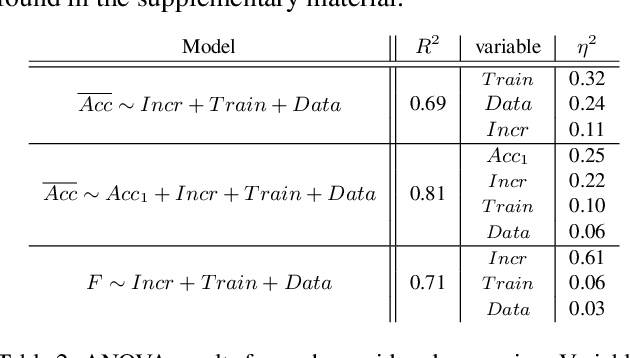
Class-Incremental Learning (CIL) aims to build classification models from data streams. At each step of the CIL process, new classes must be integrated into the model. Due to catastrophic forgetting, CIL is particularly challenging when examples from past classes cannot be stored, the case on which we focus here. To date, most approaches are based exclusively on the target dataset of the CIL process. However, the use of models pre-trained in a self-supervised way on large amounts of data has recently gained momentum. The initial model of the CIL process may only use the first batch of the target dataset, or also use pre-trained weights obtained on an auxiliary dataset. The choice between these two initial learning strategies can significantly influence the performance of the incremental learning model, but has not yet been studied in depth. Performance is also influenced by the choice of the CIL algorithm, the neural architecture, the nature of the target task, the distribution of classes in the stream and the number of examples available for learning. We conduct a comprehensive experimental study to assess the roles of these factors. We present a statistical analysis framework that quantifies the relative contribution of each factor to incremental performance. Our main finding is that the initial training strategy is the dominant factor influencing the average incremental accuracy, but that the choice of CIL algorithm is more important in preventing forgetting. Based on this analysis, we propose practical recommendations for choosing the right initial training strategy for a given incremental learning use case. These recommendations are intended to facilitate the practical deployment of incremental learning.
FeTrIL: Feature Translation for Exemplar-Free Class-Incremental Learning
Nov 23, 2022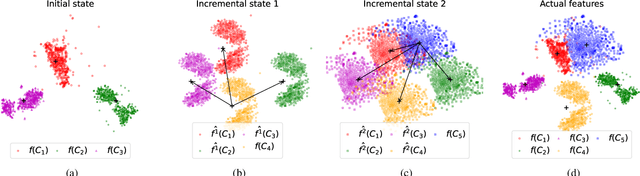



Exemplar-free class-incremental learning is very challenging due to the negative effect of catastrophic forgetting. A balance between stability and plasticity of the incremental process is needed in order to obtain good accuracy for past as well as new classes. Existing exemplar-free class-incremental methods focus either on successive fine tuning of the model, thus favoring plasticity, or on using a feature extractor fixed after the initial incremental state, thus favoring stability. We introduce a method which combines a fixed feature extractor and a pseudo-features generator to improve the stability-plasticity balance. The generator uses a simple yet effective geometric translation of new class features to create representations of past classes, made of pseudo-features. The translation of features only requires the storage of the centroid representations of past classes to produce their pseudo-features. Actual features of new classes and pseudo-features of past classes are fed into a linear classifier which is trained incrementally to discriminate between all classes. The incremental process is much faster with the proposed method compared to mainstream ones which update the entire deep model. Experiments are performed with three challenging datasets, and different incremental settings. A comparison with ten existing methods shows that our method outperforms the others in most cases.
PlaStIL: Plastic and Stable Memory-Free Class-Incremental Learning
Sep 14, 2022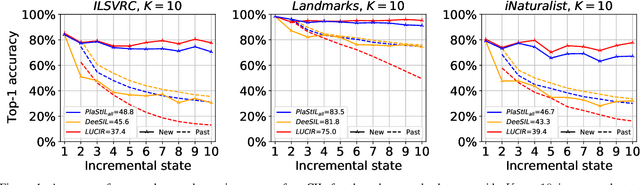
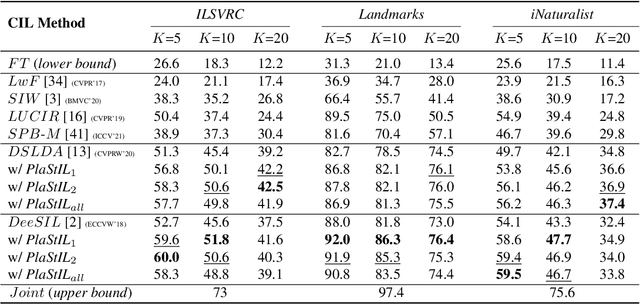
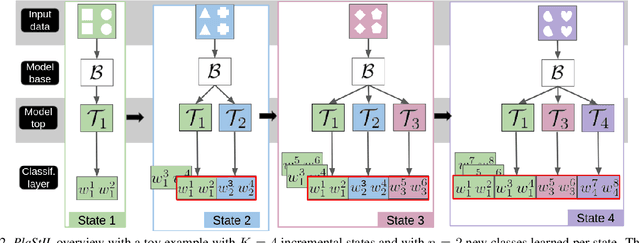
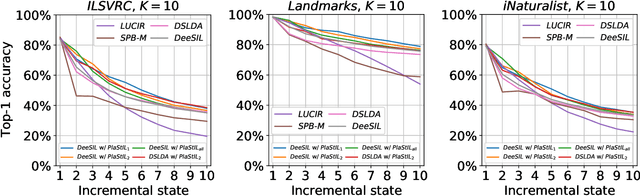
Plasticity and stability are needed in class-incremental learning in order to learn from new data while preserving past knowledge. Due to catastrophic forgetting, finding a compromise between these two properties is particularly challenging when no memory buffer is available. Mainstream methods need to store two deep models since they integrate new classes using fine tuning with knowledge distillation from the previous incremental state. We propose a method which has similar number of parameters but distributes them differently in order to find a better balance between plasticity and stability. Following an approach already deployed by transfer-based incremental methods, we freeze the feature extractor after the initial state. Classes in the oldest incremental states are trained with this frozen extractor to ensure stability. Recent classes are predicted using partially fine-tuned models in order to introduce plasticity. Our proposed plasticity layer can be incorporated to any transfer-based method designed for memory-free incremental learning, and we apply it to two such methods. Evaluation is done with three large-scale datasets. Results show that performance gains are obtained in all tested configurations compared to existing methods.