 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultIOD: Rehearsal-free Multihead Incremental Object Detector
Sep 11, 2023



Class-Incremental learning (CIL) is the ability of artificial agents to accommodate new classes as they appear in a stream. It is particularly interesting in evolving environments where agents have limited access to memory and computational resources. The main challenge of class-incremental learning is catastrophic forgetting, the inability of neural networks to retain past knowledge when learning a new one. Unfortunately, most existing class-incremental object detectors are applied to two-stage algorithms such as Faster-RCNN and rely on rehearsal memory to retain past knowledge. We believe that the current benchmarks are not realistic, and more effort should be dedicated to anchor-free and rehearsal-free object detection. In this context, we propose MultIOD, a class-incremental object detector based on CenterNet. Our main contributions are: (1) we propose a multihead feature pyramid and multihead detection architecture to efficiently separate class representations, (2) we employ transfer learning between classes learned initially and those learned incrementally to tackle catastrophic forgetting, and (3) we use a class-wise non-max-suppression as a post-processing technique to remove redundant boxes. Without bells and whistles, our method outperforms a range of state-of-the-art methods on two Pascal VOC datasets.
PlaStIL: Plastic and Stable Memory-Free Class-Incremental Learning
Sep 14, 2022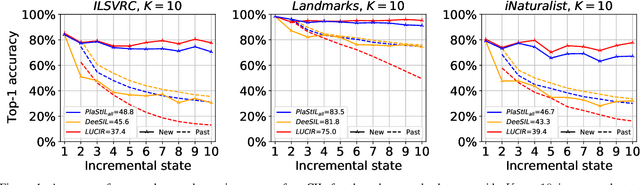
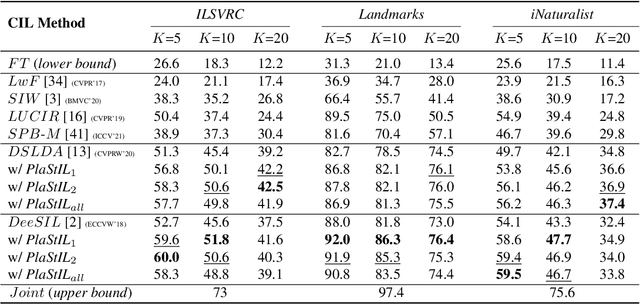
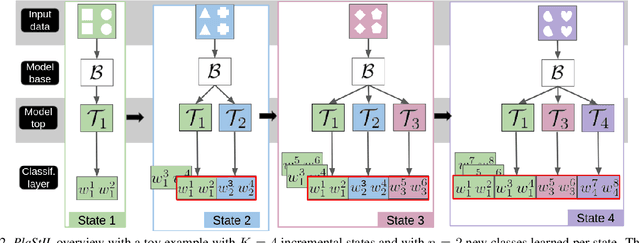
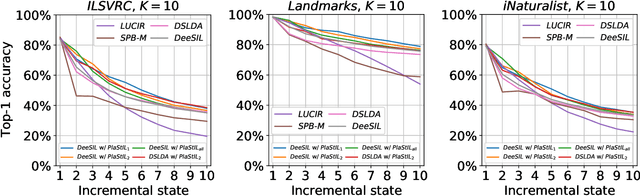
Plasticity and stability are needed in class-incremental learning in order to learn from new data while preserving past knowledge. Due to catastrophic forgetting, finding a compromise between these two properties is particularly challenging when no memory buffer is available. Mainstream methods need to store two deep models since they integrate new classes using fine tuning with knowledge distillation from the previous incremental state. We propose a method which has similar number of parameters but distributes them differently in order to find a better balance between plasticity and stability. Following an approach already deployed by transfer-based incremental methods, we freeze the feature extractor after the initial state. Classes in the oldest incremental states are trained with this frozen extractor to ensure stability. Recent classes are predicted using partially fine-tuned models in order to introduce plasticity. Our proposed plasticity layer can be incorporated to any transfer-based method designed for memory-free incremental learning, and we apply it to two such methods. Evaluation is done with three large-scale datasets. Results show that performance gains are obtained in all tested configurations compared to existing methods.
A Comparative Study of Calibration Methods for Imbalanced Class Incremental Learning
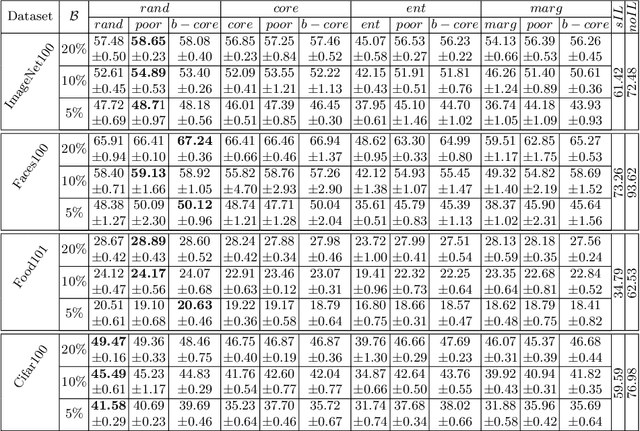
Feb 01, 2022Deep learning approaches are successful in a wide range of AI problems and in particular for visual recognition tasks. However, there are still open problems among which is the capacity to handle streams of visual information and the management of class imbalance in datasets. Existing research approaches these two problems separately while they co-occur in real world applications. Here, we study the problem of learning incrementally from imbalanced datasets. We focus on algorithms which have a constant deep model complexity and use a bounded memory to store exemplars of old classes across incremental states. Since memory is bounded, old classes are learned with fewer images than new classes and an imbalance due to incremental learning is added to the initial dataset imbalance. A score prediction bias in favor of new classes appears and we evaluate a comprehensive set of score calibration methods to reduce it. Evaluation is carried with three datasets, using two dataset imbalance configurations and three bounded memory sizes. Results show that most calibration methods have beneficial effect and that they are most useful for lower bounded memory sizes, which are most interesting in practice. As a secondary contribution, we remove the usual distillation component from the loss function of incremental learning algorithms. We show that simpler vanilla fine tuning is a stronger backbone for imbalanced incremental learning algorithms.
Dataset Knowledge Transfer for Class-Incremental Learning without Memory
Oct 16, 2021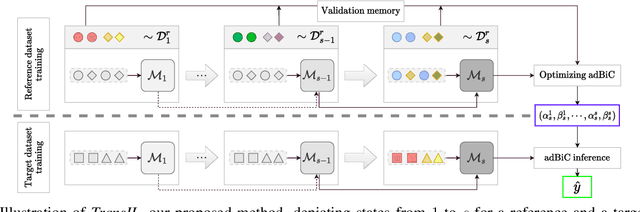
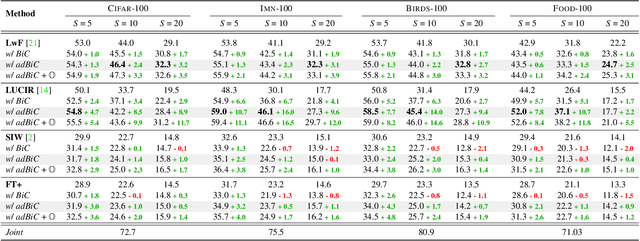
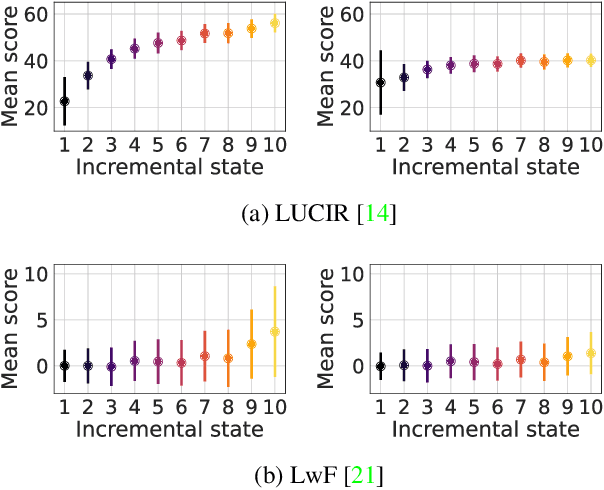
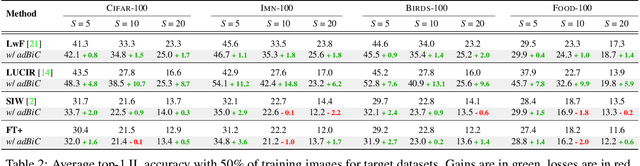
Incremental learning enables artificial agents to learn from sequential data. While important progress was made by exploiting deep neural networks, incremental learning remains very challenging. This is particularly the case when no memory of past data is allowed and catastrophic forgetting has a strong negative effect. We tackle class-incremental learning without memory by adapting prediction bias correction, a method which makes predictions of past and new classes more comparable. It was proposed when a memory is allowed and cannot be directly used without memory, since samples of past classes are required. We introduce a two-step learning process which allows the transfer of bias correction parameters between reference and target datasets. Bias correction is first optimized offline on reference datasets which have an associated validation memory. The obtained correction parameters are then transferred to target datasets, for which no memory is available. The second contribution is to introduce a finer modeling of bias correction by learning its parameters per incremental state instead of the usual past vs. new class modeling. The proposed dataset knowledge transfer is applicable to any incremental method which works without memory. We test its effectiveness by applying it to four existing methods. Evaluation with four target datasets and different configurations shows consistent improvement, with practically no computational and memory overhead.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021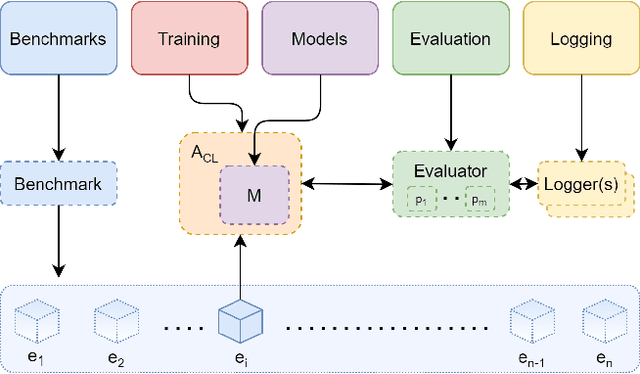


Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
A Comprehensive Study of Class Incremental Learning Algorithms for Visual Tasks
Nov 03, 2020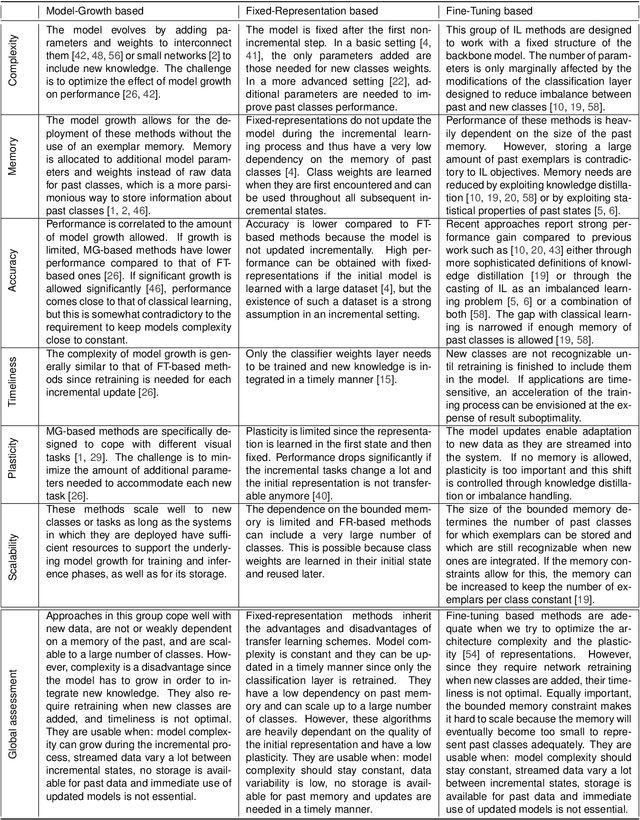

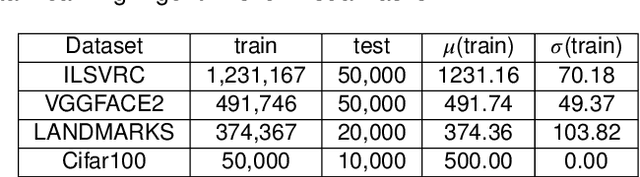
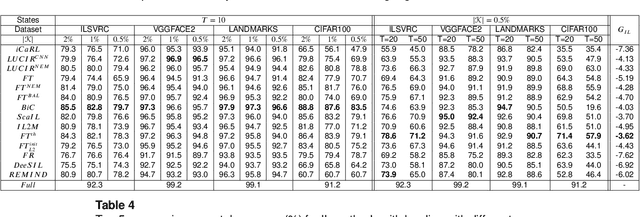
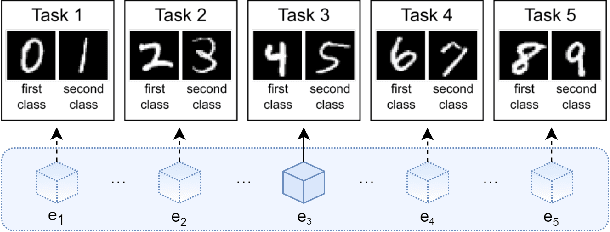
The ability of artificial agents to increment their capabilities when confronted with new data is an open challenge in artificial intelligence. The main challenge faced in such cases is catastrophic forgetting, i.e., the tendency of neural networks to underfit past data when new ones are ingested. A first group of approaches tackles catastrophic forgetting by increasing deep model capacity to accommodate new knowledge. A second type of approaches fix the deep model size and introduce a mechanism whose objective is to ensure a good compromise between stability and plasticity of the model. While the first type of algorithms were compared thoroughly, this is not the case for methods which exploit a fixed size model. Here, we focus on the latter, place them in a common conceptual and experimental framework and propose the following contributions: (1) define six desirable properties of incremental learning algorithms and analyze them according to these properties, (2) introduce a unified formalization of the class-incremental learning problem, (3) propose a common evaluation framework which is more thorough than existing ones in terms of number of datasets, size of datasets, size of bounded memory and number of incremental states, (4) investigate the usefulness of herding for past exemplars selection, (5) provide experimental evidence that it is possible to obtain competitive performance without the use of knowledge distillation to tackle catastrophic forgetting, and (6) facilitate reproducibility by integrating all tested methods in a common open-source repository. The main experimental finding is that none of the existing algorithms achieves the best results in all evaluated settings. Important differences arise notably if a bounded memory of past classes is allowed or not.
Initial Classifier Weights Replay for Memoryless Class Incremental Learning
Aug 31, 2020
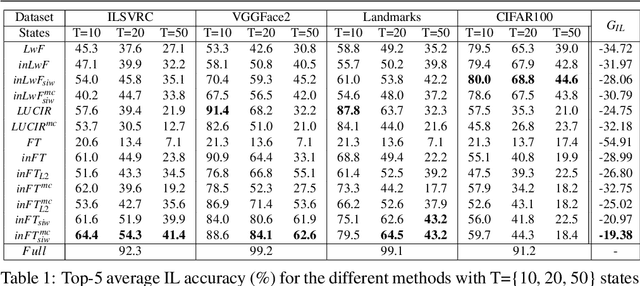
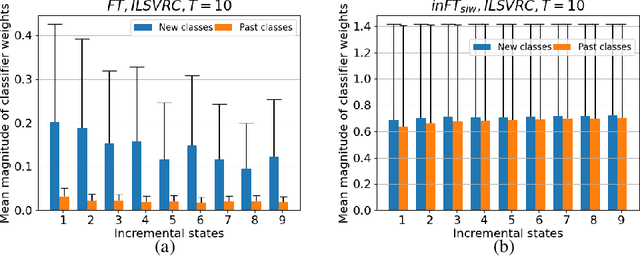
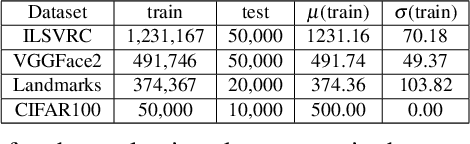
Incremental Learning (IL) is useful when artificial systems need to deal with streams of data and do not have access to all data at all times. The most challenging setting requires a constant complexity of the deep model and an incremental model update without access to a bounded memory of past data. Then, the representations of past classes are strongly affected by catastrophic forgetting. To mitigate its negative effect, an adapted fine tuning which includes knowledge distillation is usually deployed. We propose a different approach based on a vanilla fine tuning backbone. It leverages initial classifier weights which provide a strong representation of past classes because they are trained with all class data. However, the magnitude of classifiers learned in different states varies and normalization is needed for a fair handling of all classes. Normalization is performed by standardizing the initial classifier weights, which are assumed to be normally distributed. In addition, a calibration of prediction scores is done by using state level statistics to further improve classification fairness. We conduct a thorough evaluation with four public datasets in a memoryless incremental learning setting. Results show that our method outperforms existing techniques by a large margin for large-scale datasets.
Active Class Incremental Learning for Imbalanced Datasets
Aug 25, 2020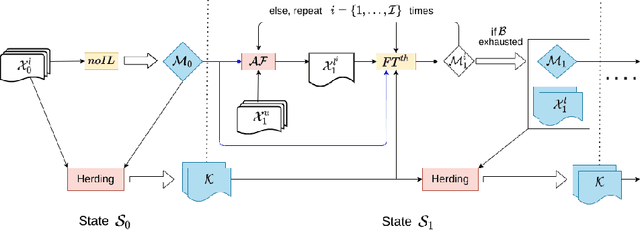
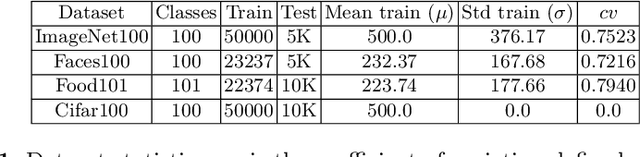
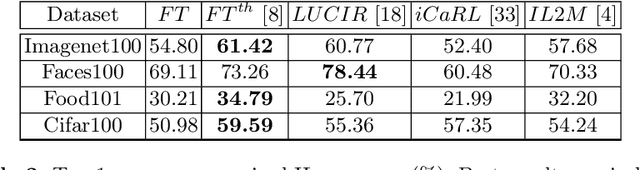
Incremental Learning (IL) allows AI systems to adapt to streamed data. Most existing algorithms make two strong hypotheses which reduce the realism of the incremental scenario: (1) new data are assumed to be readily annotated when streamed and (2) tests are run with balanced datasets while most real-life datasets are actually imbalanced. These hypotheses are discarded and the resulting challenges are tackled with a combination of active and imbalanced learning. We introduce sample acquisition functions which tackle imbalance and are compatible with IL constraints. We also consider IL as an imbalanced learning problem instead of the established usage of knowledge distillation against catastrophic forgetting. Here, imbalance effects are reduced during inference through class prediction scaling. Evaluation is done with four visual datasets and compares existing and proposed sample acquisition functions. Results indicate that the proposed contributions have a positive effect and reduce the gap between active and standard IL performance.
ScaIL: Classifier Weights Scaling for Class Incremental Learning
Jan 16, 2020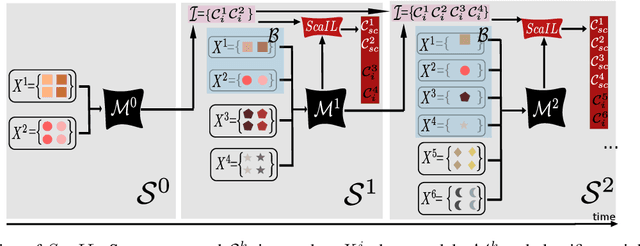
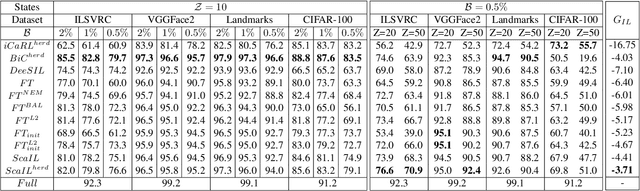
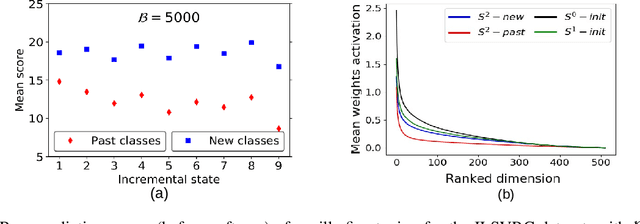
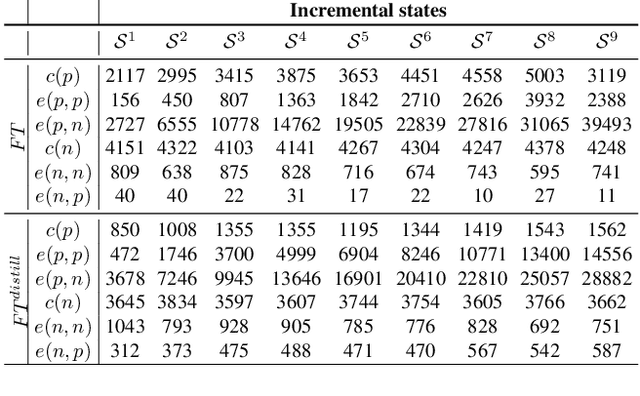
Incremental learning is useful if an AI agent needs to integrate data from a stream. The problem is non trivial if the agent runs on a limited computational budget and has a bounded memory of past data. In a deep learning approach, the constant computational budget requires the use of a fixed architecture for all incremental states. The bounded memory generates data imbalance in favor of new classes and a prediction bias toward them appears. This bias is commonly countered by introducing a data balancing step in addition to the basic network training. We depart from this approach and propose simple but efficient scaling of past class classifier weights to make them more comparable to those of new classes. Scaling exploits incremental state level statistics and is applied to the classifiers learned in the initial state of classes in order to profit from all their available data. We also question the utility of the widely used distillation loss component of incremental learning algorithms by comparing it to vanilla fine tuning in presence of a bounded memory. Evaluation is done against competitive baselines using four public datasets. Results show that the classifier weights scaling and the removal of the distillation are both beneficial.
DeeSIL: Deep-Shallow Incremental Learning
Aug 20, 2018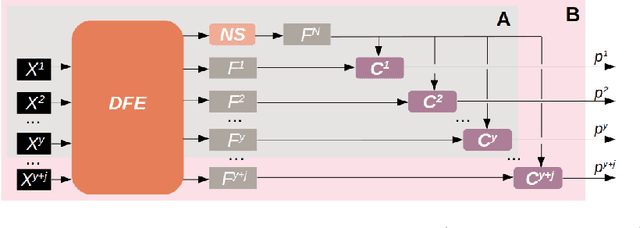
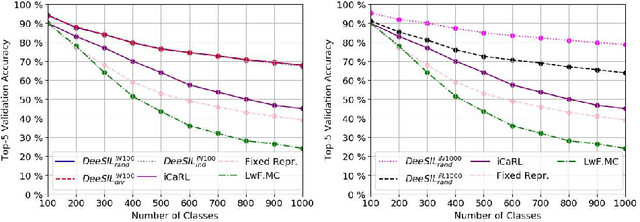
Incremental Learning (IL) is an interesting AI problem when the algorithm is assumed to work on a budget. This is especially true when IL is modeled using a deep learning approach, where two com- plex challenges arise due to limited memory, which induces catastrophic forgetting and delays related to the retraining needed in order to incorpo- rate new classes. Here we introduce DeeSIL, an adaptation of a known transfer learning scheme that combines a fixed deep representation used as feature extractor and learning independent shallow classifiers to in- crease recognition capacity. This scheme tackles the two aforementioned challenges since it works well with a limited memory budget and each new concept can be added within a minute. Moreover, since no deep re- training is needed when the model is incremented, DeeSIL can integrate larger amounts of initial data that provide more transferable features. Performance is evaluated on ImageNet LSVRC 2012 against three state of the art algorithms. Results show that, at scale, DeeSIL performance is 23 and 33 points higher than the best baseline when using the same and more initial data respectively.