 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinority Class Oriented Active Learning for Imbalanced Datasets
Feb 01, 2022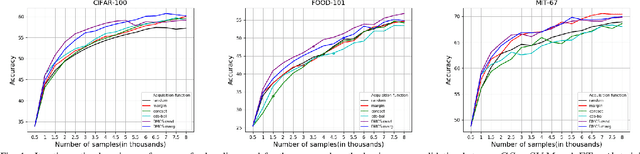

Active learning aims to optimize the dataset annotation process when resources are constrained. Most existing methods are designed for balanced datasets. Their practical applicability is limited by the fact that a majority of real-life datasets are actually imbalanced. Here, we introduce a new active learning method which is designed for imbalanced datasets. It favors samples likely to be in minority classes so as to reduce the imbalance of the labeled subset and create a better representation for these classes. We also compare two training schemes for active learning: (1) the one commonly deployed in deep active learning using model fine tuning for each iteration and (2) a scheme which is inspired by transfer learning and exploits generic pre-trained models and train shallow classifiers for each iteration. Evaluation is run with three imbalanced datasets. Results show that the proposed active learning method outperforms competitive baselines. Equally interesting, they also indicate that the transfer learning training scheme outperforms model fine tuning if features are transferable from the generic dataset to the unlabeled one. This last result is surprising and should encourage the community to explore the design of deep active learning methods.
A Comparative Study of Calibration Methods for Imbalanced Class Incremental Learning
Feb 01, 2022Deep learning approaches are successful in a wide range of AI problems and in particular for visual recognition tasks. However, there are still open problems among which is the capacity to handle streams of visual information and the management of class imbalance in datasets. Existing research approaches these two problems separately while they co-occur in real world applications. Here, we study the problem of learning incrementally from imbalanced datasets. We focus on algorithms which have a constant deep model complexity and use a bounded memory to store exemplars of old classes across incremental states. Since memory is bounded, old classes are learned with fewer images than new classes and an imbalance due to incremental learning is added to the initial dataset imbalance. A score prediction bias in favor of new classes appears and we evaluate a comprehensive set of score calibration methods to reduce it. Evaluation is carried with three datasets, using two dataset imbalance configurations and three bounded memory sizes. Results show that most calibration methods have beneficial effect and that they are most useful for lower bounded memory sizes, which are most interesting in practice. As a secondary contribution, we remove the usual distillation component from the loss function of incremental learning algorithms. We show that simpler vanilla fine tuning is a stronger backbone for imbalanced incremental learning algorithms.
Optimizing Active Learning for Low Annotation Budgets
Jan 18, 2022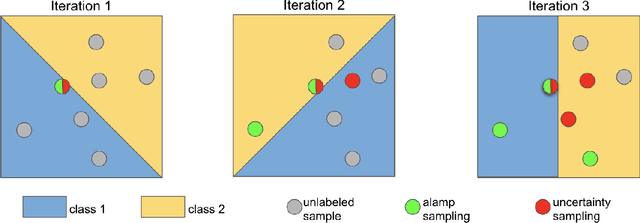
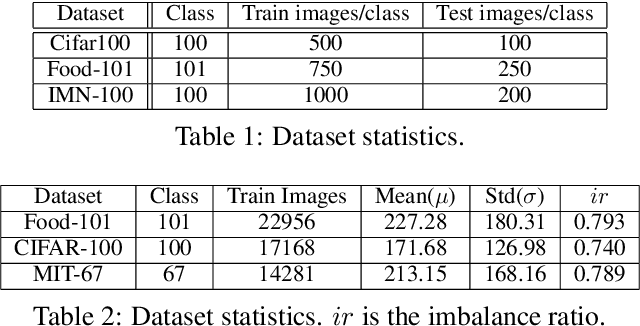
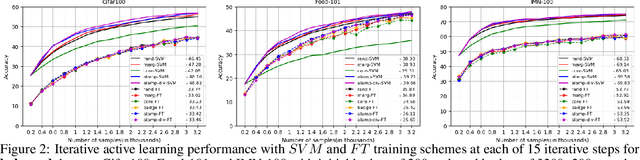
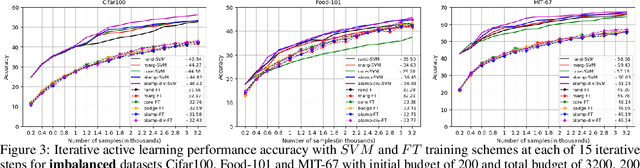
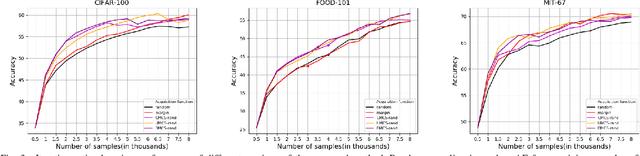
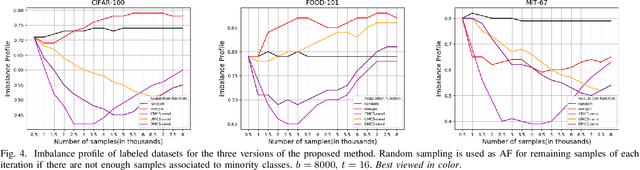
When we can not assume a large amount of annotated data , active learning is a good strategy. It consists in learning a model on a small amount of annotated data (annotation budget) and in choosing the best set of points to annotate in order to improve the previous model and gain in generalization. In deep learning, active learning is usually implemented as an iterative process in which successive deep models are updated via fine tuning, but it still poses some issues. First, the initial batch of annotated images has to be sufficiently large to train a deep model. Such an assumption is strong, especially when the total annotation budget is reduced. We tackle this issue by using an approach inspired by transfer learning. A pre-trained model is used as a feature extractor and only shallow classifiers are learned during the active iterations. The second issue is the effectiveness of probability or feature estimates of early models for AL task. Samples are generally selected for annotation using acquisition functions based only on the last learned model. We introduce a novel acquisition function which exploits the iterative nature of AL process to select samples in a more robust fashion. Samples for which there is a maximum shift towards uncertainty between the last two learned models predictions are favored. A diversification step is added to select samples from different regions of the classification space and thus introduces a representativeness component in our approach. Evaluation is done against competitive methods with three balanced and imbalanced datasets and outperforms them.
Active Class Incremental Learning for Imbalanced Datasets
Aug 25, 2020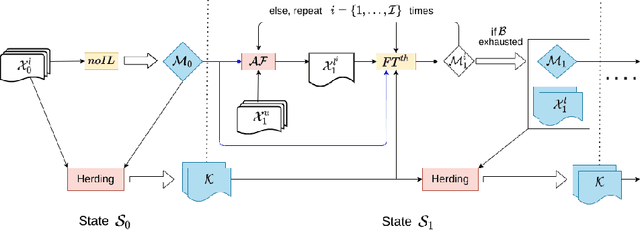
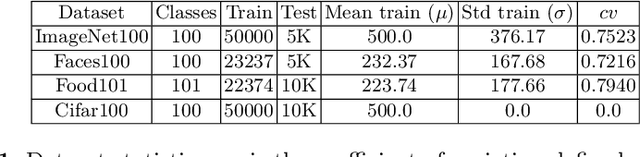
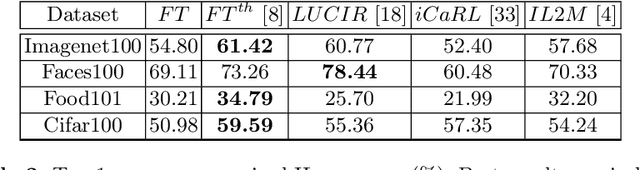
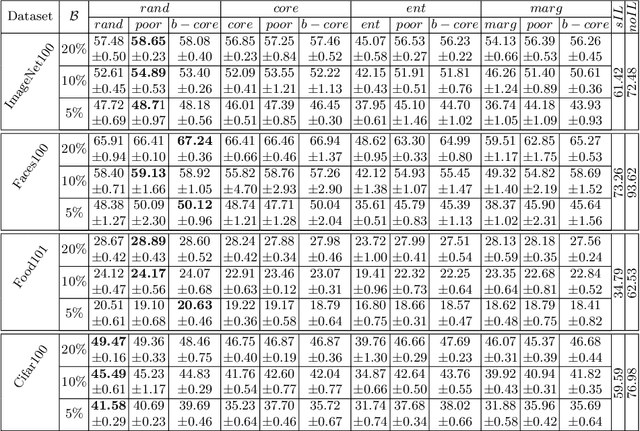
Incremental Learning (IL) allows AI systems to adapt to streamed data. Most existing algorithms make two strong hypotheses which reduce the realism of the incremental scenario: (1) new data are assumed to be readily annotated when streamed and (2) tests are run with balanced datasets while most real-life datasets are actually imbalanced. These hypotheses are discarded and the resulting challenges are tackled with a combination of active and imbalanced learning. We introduce sample acquisition functions which tackle imbalance and are compatible with IL constraints. We also consider IL as an imbalanced learning problem instead of the established usage of knowledge distillation against catastrophic forgetting. Here, imbalance effects are reduced during inference through class prediction scaling. Evaluation is done with four visual datasets and compares existing and proposed sample acquisition functions. Results indicate that the proposed contributions have a positive effect and reduce the gap between active and standard IL performance.