 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Image Detectors Overrely on Global Artifacts: Evidence from Inpainting Exchange
Jan 30, 2026Modern deep learning-based inpainting enables realistic local image manipulation, raising critical challenges for reliable detection. However, we observe that current detectors primarily rely on global artifacts that appear as inpainting side effects, rather than on locally synthesized content. We show that this behavior occurs because VAE-based reconstruction induces a subtle but pervasive spectral shift across the entire image, including unedited regions. To isolate this effect, we introduce Inpainting Exchange (INP-X), an operation that restores original pixels outside the edited region while preserving all synthesized content. We create a 90K test dataset including real, inpainted, and exchanged images to evaluate this phenomenon. Under this intervention, pretrained state-of-the-art detectors, including commercial ones, exhibit a dramatic drop in accuracy (e.g., from 91\% to 55\%), frequently approaching chance level. We provide a theoretical analysis linking this behavior to high-frequency attenuation caused by VAE information bottlenecks. Our findings highlight the need for content-aware detection. Indeed, training on our dataset yields better generalization and localization than standard inpainting. Our dataset and code are publicly available at https://github.com/emirhanbilgic/INP-X.
A Scalable Entity-Based Framework for Auditing Bias in LLMs
Jan 18, 2026Existing approaches to bias evaluation in large language models (LLMs) trade ecological validity for statistical control, relying on artificial prompts that poorly reflect real-world use, or on naturalistic tasks that lack scale and rigor. We introduce a scalable bias-auditing framework using named entities as probes to measure structural disparities in model behavior. We show that synthetic data reliably reproduces bias patterns observed in natural text, enabling large-scale analysis. Using this approach, we conduct the largest bias audit to date, comprising 1.9 billion data points across multiple entity types, tasks, languages, models, and prompting strategies. Our results reveal systematic biases: models penalize right-wing politicians, favor left-wing politicians, prefer Western and wealthy nations over the Global South, favor Western companies, and penalize firms in the defense and pharmaceutical sectors. While instruction tuning reduces bias, increasing model scale amplifies it, and prompting in Chinese or Russian does not attenuate Western-aligned preferences. These results indicate that LLMs should undergo rigorous auditing before deployment in high-stakes applications.
Reliable and Reproducible Demographic Inference for Fairness in Face Analysis
Oct 23, 2025Fairness evaluation in face analysis systems (FAS) typically depends on automatic demographic attribute inference (DAI), which itself relies on predefined demographic segmentation. However, the validity of fairness auditing hinges on the reliability of the DAI process. We begin by providing a theoretical motivation for this dependency, showing that improved DAI reliability leads to less biased and lower-variance estimates of FAS fairness. To address this, we propose a fully reproducible DAI pipeline that replaces conventional end-to-end training with a modular transfer learning approach. Our design integrates pretrained face recognition encoders with non-linear classification heads. We audit this pipeline across three dimensions: accuracy, fairness, and a newly introduced notion of robustness, defined via intra-identity consistency. The proposed robustness metric is applicable to any demographic segmentation scheme. We benchmark the pipeline on gender and ethnicity inference across multiple datasets and training setups. Our results show that the proposed method outperforms strong baselines, particularly on ethnicity, which is the more challenging attribute. To promote transparency and reproducibility, we will publicly release the training dataset metadata, full codebase, pretrained models, and evaluation toolkit. This work contributes a reliable foundation for demographic inference in fairness auditing.
CEA-LIST at CheckThat! 2025: Evaluating LLMs as Detectors of Bias and Opinion in Text
Jul 10, 2025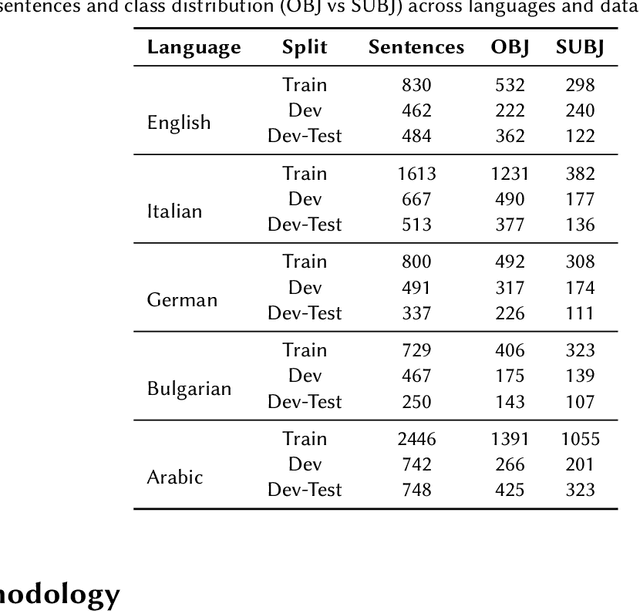



This paper presents a competitive approach to multilingual subjectivity detection using large language models (LLMs) with few-shot prompting. We participated in Task 1: Subjectivity of the CheckThat! 2025 evaluation campaign. We show that LLMs, when paired with carefully designed prompts, can match or outperform fine-tuned smaller language models (SLMs), particularly in noisy or low-quality data settings. Despite experimenting with advanced prompt engineering techniques, such as debating LLMs and various example selection strategies, we found limited benefit beyond well-crafted standard few-shot prompts. Our system achieved top rankings across multiple languages in the CheckThat! 2025 subjectivity detection task, including first place in Arabic and Polish, and top-four finishes in Italian, English, German, and multilingual tracks. Notably, our method proved especially robust on the Arabic dataset, likely due to its resilience to annotation inconsistencies. These findings highlight the effectiveness and adaptability of LLM-based few-shot learning for multilingual sentiment tasks, offering a strong alternative to traditional fine-tuning, particularly when labeled data is scarce or inconsistent.
Analyzing Political Bias in LLMs via Target-Oriented Sentiment Classification
May 26, 2025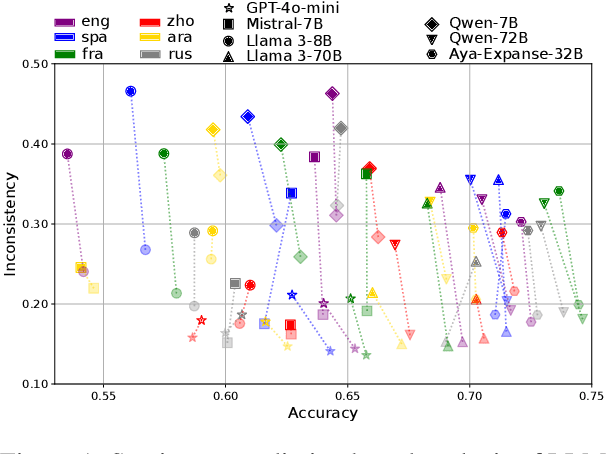
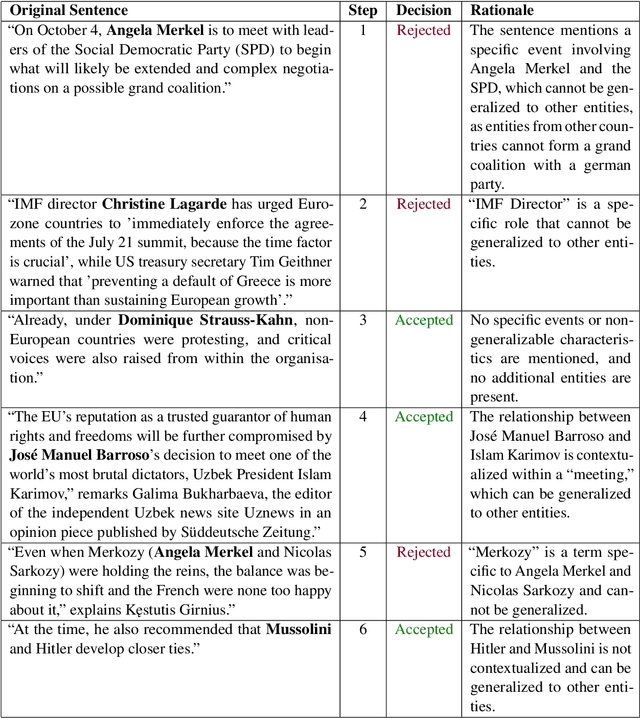
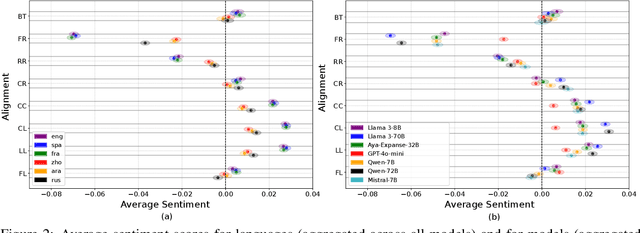
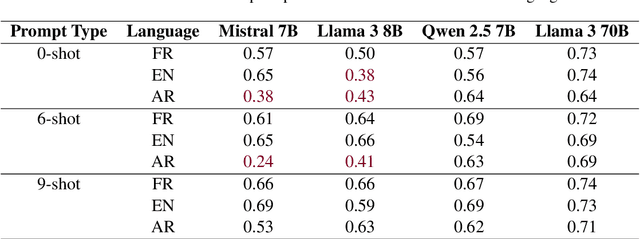
Political biases encoded by LLMs might have detrimental effects on downstream applications. Existing bias analysis methods rely on small-size intermediate tasks (questionnaire answering or political content generation) and rely on the LLMs themselves for analysis, thus propagating bias. We propose a new approach leveraging the observation that LLM sentiment predictions vary with the target entity in the same sentence. We define an entropy-based inconsistency metric to encode this prediction variability. We insert 1319 demographically and politically diverse politician names in 450 political sentences and predict target-oriented sentiment using seven models in six widely spoken languages. We observe inconsistencies in all tested combinations and aggregate them in a statistically robust analysis at different granularity levels. We observe positive and negative bias toward left and far-right politicians and positive correlations between politicians with similar alignment. Bias intensity is higher for Western languages than for others. Larger models exhibit stronger and more consistent biases and reduce discrepancies between similar languages. We partially mitigate LLM unreliability in target-oriented sentiment classification (TSC) by replacing politician names with fictional but plausible counterparts.
Fairer Analysis and Demographically Balanced Face Generation for Fairer Face Verification
Dec 04, 2024Face recognition and verification are two computer vision tasks whose performances have advanced with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive nature of face data and biases in real-world training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems remain. Using the existing DCFace SOTA framework, we introduce a new controlled generation pipeline that improves fairness. Through classical fairness metrics and a proposed in-depth statistical analysis based on logit models and ANOVA, we show that our generation pipeline improves fairness more than other bias mitigation approaches while slightly improving raw performance.
Quantifying User Coherence: A Unified Framework for Cross-Domain Recommendation Analysis
Oct 03, 2024



The effectiveness of Recommender Systems (RS) is closely tied to the quality and distinctiveness of user profiles, yet despite many advancements in raw performance, the sensitivity of RS to user profile quality remains under-researched. This paper introduces novel information-theoretic measures for understanding recommender systems: a "surprise" measure quantifying users' deviations from popular choices, and a "conditional surprise" measure capturing user interaction coherence. We evaluate 7 recommendation algorithms across 9 datasets, revealing the relationships between our measures and standard performance metrics. Using a rigorous statistical framework, our analysis quantifies how much user profile density and information measures impact algorithm performance across domains. By segmenting users based on these measures, we achieve improved performance with reduced data and show that simpler algorithms can match complex ones for low-coherence users. Additionally, we employ our measures to analyze how well different recommendation algorithms maintain the coherence and diversity of user preferences in their predictions, providing insights into algorithm behavior. This work advances the theoretical understanding of user behavior and practical heuristics for personalized recommendation systems, promoting more efficient and adaptive architectures.
Combining Objective and Subjective Perspectives for Political News Understanding
Aug 20, 2024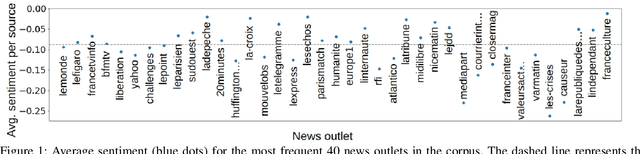
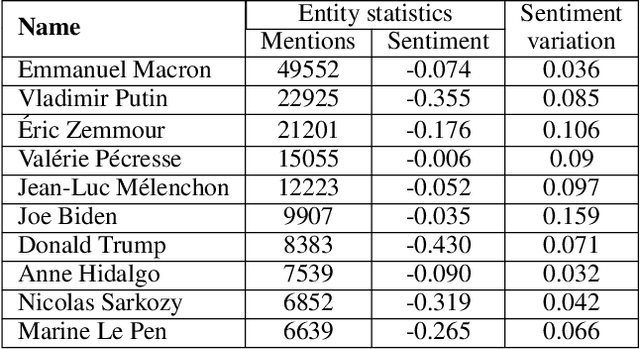
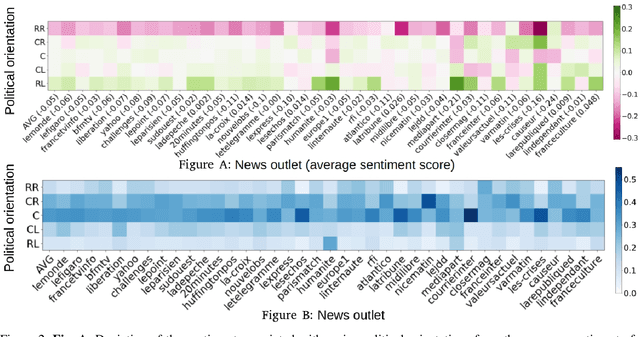

Researchers and practitioners interested in computational politics rely on automatic content analysis tools to make sense of the large amount of political texts available on the Web. Such tools should provide objective and subjective aspects at different granularity levels to make the analyses useful in practice. Existing methods produce interesting insights for objective aspects, but are limited for subjective ones, are often limited to national contexts, and have limited explainability. We introduce a text analysis framework which integrates both perspectives and provides a fine-grained processing of subjective aspects. Information retrieval techniques and knowledge bases complement powerful natural language processing components to allow a flexible aggregation of results at different granularity levels. Importantly, the proposed bottom-up approach facilitates the explainability of the obtained results. We illustrate its functioning with insights on news outlets, political orientations, topics, individual entities, and demographic segments. The approach is instantiated on a large corpus of French news, but is designed to work seamlessly for other languages and countries.
Toward Fairer Face Recognition Datasets
Jun 24, 2024



Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
Recommendation of data-free class-incremental learning algorithms by simulating future data
Mar 26, 2024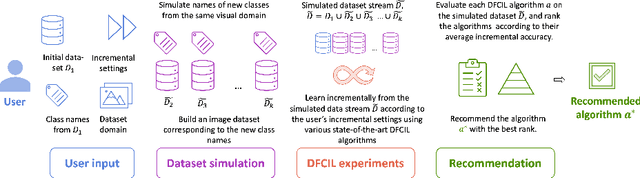
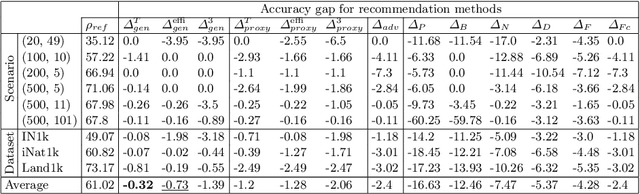


Class-incremental learning deals with sequential data streams composed of batches of classes. Various algorithms have been proposed to address the challenging case where samples from past classes cannot be stored. However, selecting an appropriate algorithm for a user-defined setting is an open problem, as the relative performance of these algorithms depends on the incremental settings. To solve this problem, we introduce an algorithm recommendation method that simulates the future data stream. Given an initial set of classes, it leverages generative models to simulate future classes from the same visual domain. We evaluate recent algorithms on the simulated stream and recommend the one which performs best in the user-defined incremental setting. We illustrate the effectiveness of our method on three large datasets using six algorithms and six incremental settings. Our method outperforms competitive baselines, and performance is close to that of an oracle choosing the best algorithm in each setting. This work contributes to facilitate the practical deployment of incremental learning.