 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Adversarial Robustness and Adversarial Training Strategies for Object Detection
Feb 18, 2026Object detection models are critical components of automated systems, such as autonomous vehicles and perception-based robots, but their sensitivity to adversarial attacks poses a serious security risk. Progress in defending these models lags behind classification, hindered by a lack of standardized evaluation. It is nearly impossible to thoroughly compare attack or defense methods, as existing work uses different datasets, inconsistent efficiency metrics, and varied measures of perturbation cost. This paper addresses this gap by investigating three key questions: (1) How can we create a fair benchmark to impartially compare attacks? (2) How well do modern attacks transfer across different architectures, especially from Convolutional Neural Networks to Vision Transformers? (3) What is the most effective adversarial training strategy for robust defense? To answer these, we first propose a unified benchmark framework focused on digital, non-patch-based attacks. This framework introduces specific metrics to disentangle localization and classification errors and evaluates attack cost using multiple perceptual metrics. Using this benchmark, we conduct extensive experiments on state-of-the-art attacks and a wide range of detectors. Our findings reveal two major conclusions: first, modern adversarial attacks against object detection models show a significant lack of transferability to transformer-based architectures. Second, we demonstrate that the most robust adversarial training strategy leverages a dataset composed of a mix of high-perturbation attacks with different objectives (e.g., spatial and semantic), which outperforms training on any single attack.
Reliable and Reproducible Demographic Inference for Fairness in Face Analysis
Oct 23, 2025Fairness evaluation in face analysis systems (FAS) typically depends on automatic demographic attribute inference (DAI), which itself relies on predefined demographic segmentation. However, the validity of fairness auditing hinges on the reliability of the DAI process. We begin by providing a theoretical motivation for this dependency, showing that improved DAI reliability leads to less biased and lower-variance estimates of FAS fairness. To address this, we propose a fully reproducible DAI pipeline that replaces conventional end-to-end training with a modular transfer learning approach. Our design integrates pretrained face recognition encoders with non-linear classification heads. We audit this pipeline across three dimensions: accuracy, fairness, and a newly introduced notion of robustness, defined via intra-identity consistency. The proposed robustness metric is applicable to any demographic segmentation scheme. We benchmark the pipeline on gender and ethnicity inference across multiple datasets and training setups. Our results show that the proposed method outperforms strong baselines, particularly on ethnicity, which is the more challenging attribute. To promote transparency and reproducibility, we will publicly release the training dataset metadata, full codebase, pretrained models, and evaluation toolkit. This work contributes a reliable foundation for demographic inference in fairness auditing.
Fairer Analysis and Demographically Balanced Face Generation for Fairer Face Verification
Dec 04, 2024Face recognition and verification are two computer vision tasks whose performances have advanced with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive nature of face data and biases in real-world training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems remain. Using the existing DCFace SOTA framework, we introduce a new controlled generation pipeline that improves fairness. Through classical fairness metrics and a proposed in-depth statistical analysis based on logit models and ANOVA, we show that our generation pipeline improves fairness more than other bias mitigation approaches while slightly improving raw performance.
Toward Fairer Face Recognition Datasets
Jun 24, 2024



Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
3D-COCO: extension of MS-COCO dataset for image detection and 3D reconstruction modules
Apr 08, 2024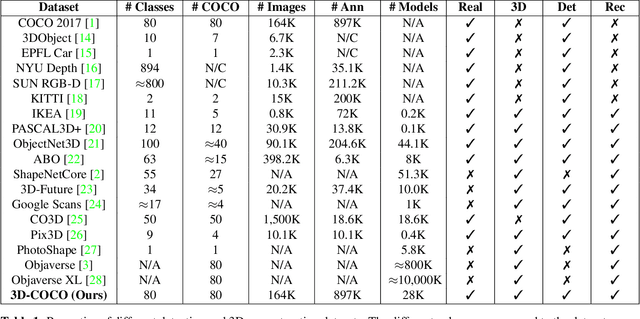

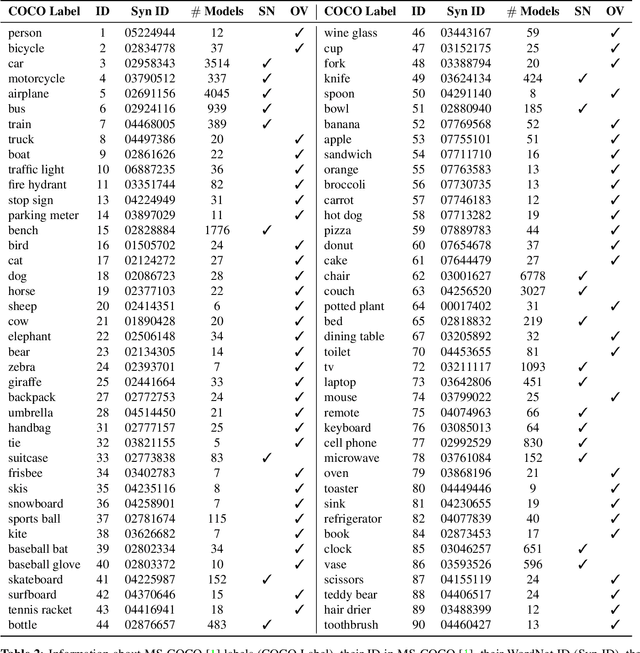
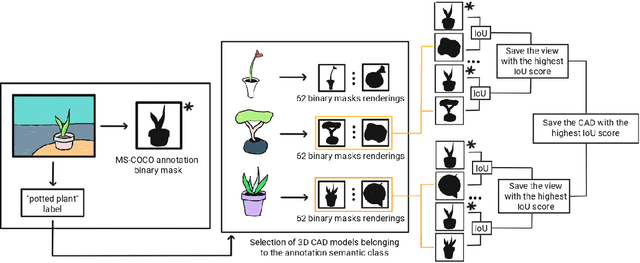
We introduce 3D-COCO, an extension of the original MS-COCO dataset providing 3D models and 2D-3D alignment annotations. 3D-COCO was designed to achieve computer vision tasks such as 3D reconstruction or image detection configurable with textual, 2D image, and 3D CAD model queries. We complete the existing MS-COCO dataset with 28K 3D models collected on ShapeNet and Objaverse. By using an IoU-based method, we match each MS-COCO annotation with the best 3D models to provide a 2D-3D alignment. The open-source nature of 3D-COCO is a premiere that should pave the way for new research on 3D-related topics. The dataset and its source codes is available at https://kalisteo.cea.fr/index.php/coco3d-object-detection-and-reconstruction/
Detecting Human-to-Human-or-Object (H2O) Interactions with DIABOLO
Jan 07, 2022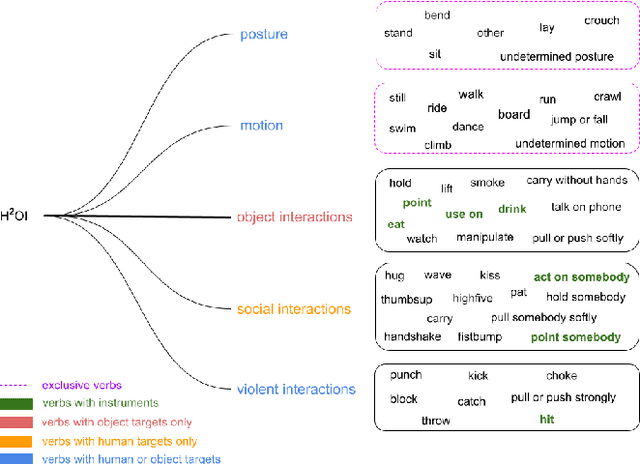

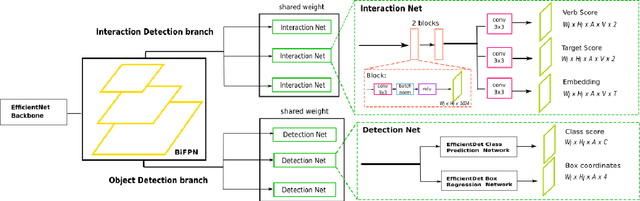
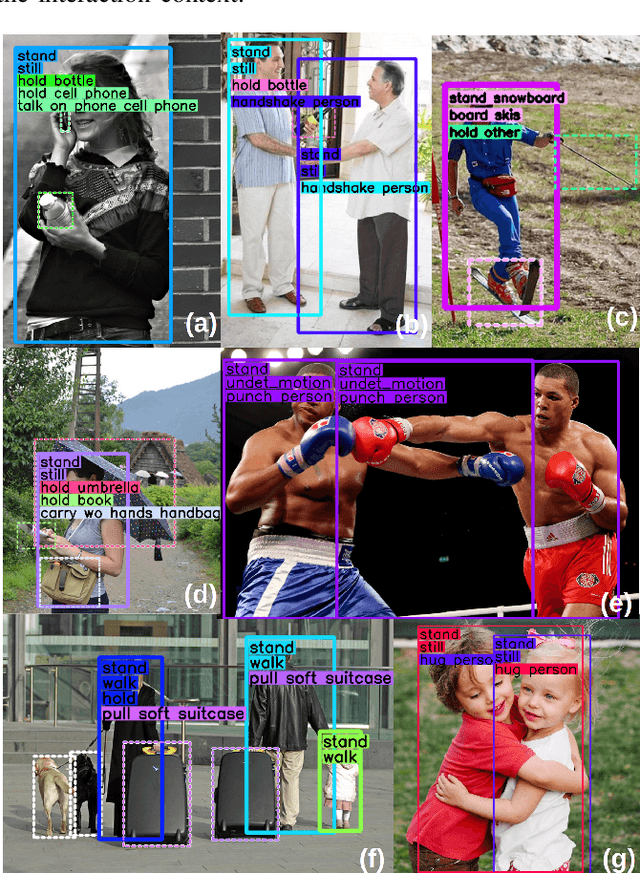
Detecting human interactions is crucial for human behavior analysis. Many methods have been proposed to deal with Human-to-Object Interaction (HOI) detection, i.e., detecting in an image which person and object interact together and classifying the type of interaction. However, Human-to-Human Interactions, such as social and violent interactions, are generally not considered in available HOI training datasets. As we think these types of interactions cannot be ignored and decorrelated from HOI when analyzing human behavior, we propose a new interaction dataset to deal with both types of human interactions: Human-to-Human-or-Object (H2O). In addition, we introduce a novel taxonomy of verbs, intended to be closer to a description of human body attitude in relation to the surrounding targets of interaction, and more independent of the environment. Unlike some existing datasets, we strive to avoid defining synonymous verbs when their use highly depends on the target type or requires a high level of semantic interpretation. As H2O dataset includes V-COCO images annotated with this new taxonomy, images obviously contain more interactions. This can be an issue for HOI detection methods whose complexity depends on the number of people, targets or interactions. Thus, we propose DIABOLO (Detecting InterActions By Only Looking Once), an efficient subject-centric single-shot method to detect all interactions in one forward pass, with constant inference time independent of image content. In addition, this multi-task network simultaneously detects all people and objects. We show how sharing a network for these tasks does not only save computation resource but also improves performance collaboratively. Finally, DIABOLO is a strong baseline for the new proposed challenge of H2O Interaction detection, as it outperforms all state-of-the-art methods when trained and evaluated on HOI dataset V-COCO.
PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
Jan 07, 2021



Recently, several deep learning models have been proposed for 3D human pose estimation. Nevertheless, most of these approaches only focus on the single-person case or estimate 3D pose of a few people at high resolution. Furthermore, many applications such as autonomous driving or crowd analysis require pose estimation of a large number of people possibly at low-resolution. In this work, we present PandaNet (Pose estimAtioN and Dectection Anchor-based Network), a new single-shot, anchor-based and multi-person 3D pose estimation approach. The proposed model performs bounding box detection and, for each detected person, 2D and 3D pose regression into a single forward pass. It does not need any post-processing to regroup joints since the network predicts a full 3D pose for each bounding box and allows the pose estimation of a possibly large number of people at low resolution. To manage people overlapping, we introduce a Pose-Aware Anchor Selection strategy. Moreover, as imbalance exists between different people sizes in the image, and joints coordinates have different uncertainties depending on these sizes, we propose a method to automatically optimize weights associated to different people scales and joints for efficient training. PandaNet surpasses previous single-shot methods on several challenging datasets: a multi-person urban virtual but very realistic dataset (JTA Dataset), and two real world 3D multi-person datasets (CMU Panoptic and MuPoTS-3D).
Classifying All Interacting Pairs in a Single Shot
Jan 13, 2020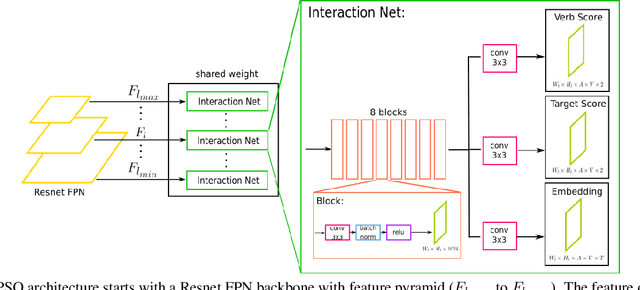


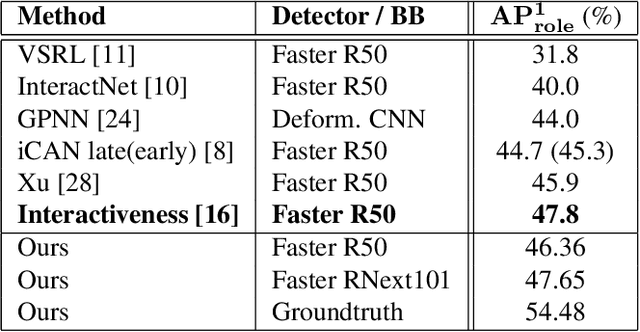
In this paper, we introduce a novel human interaction detection approach, based on CALIPSO (Classifying ALl Interacting Pairs in a Single shOt), a classifier of human-object interactions. This new single-shot interaction classifier estimates interactions simultaneously for all human-object pairs, regardless of their number and class. State-of-the-art approaches adopt a multi-shot strategy based on a pairwise estimate of interactions for a set of human-object candidate pairs, which leads to a complexity depending, at least, on the number of interactions or, at most, on the number of candidate pairs. In contrast, the proposed method estimates the interactions on the whole image. Indeed, it simultaneously estimates all interactions between all human subjects and object targets by performing a single forward pass throughout the image. Consequently, it leads to a constant complexity and computation time independent of the number of subjects, objects or interactions in the image. In detail, interaction classification is achieved on a dense grid of anchors thanks to a joint multi-task network that learns three complementary tasks simultaneously: (i) prediction of the types of interaction, (ii) estimation of the presence of a target and (iii) learning of an embedding which maps interacting subject and target to a same representation, by using a metric learning strategy. In addition, we introduce an object-centric passive-voice verb estimation which significantly improves results. Evaluations on the two well-known Human-Object Interaction image datasets, V-COCO and HICO-DET, demonstrate the competitiveness of the proposed method (2nd place) compared to the state-of-the-art while having constant computation time regardless of the number of objects and interactions in the image.
Deep, robust and single shot 3D multi-person human pose estimation in complex images
Nov 08, 2019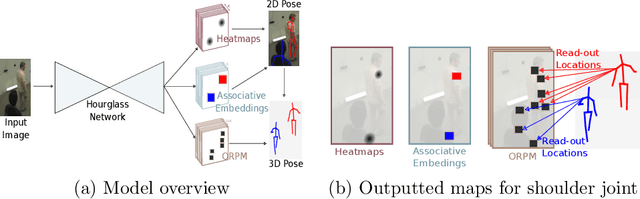
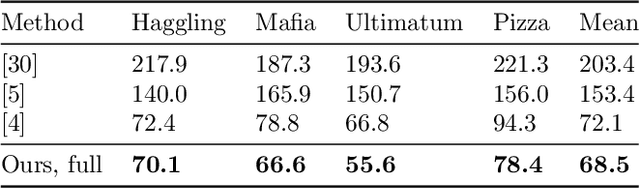

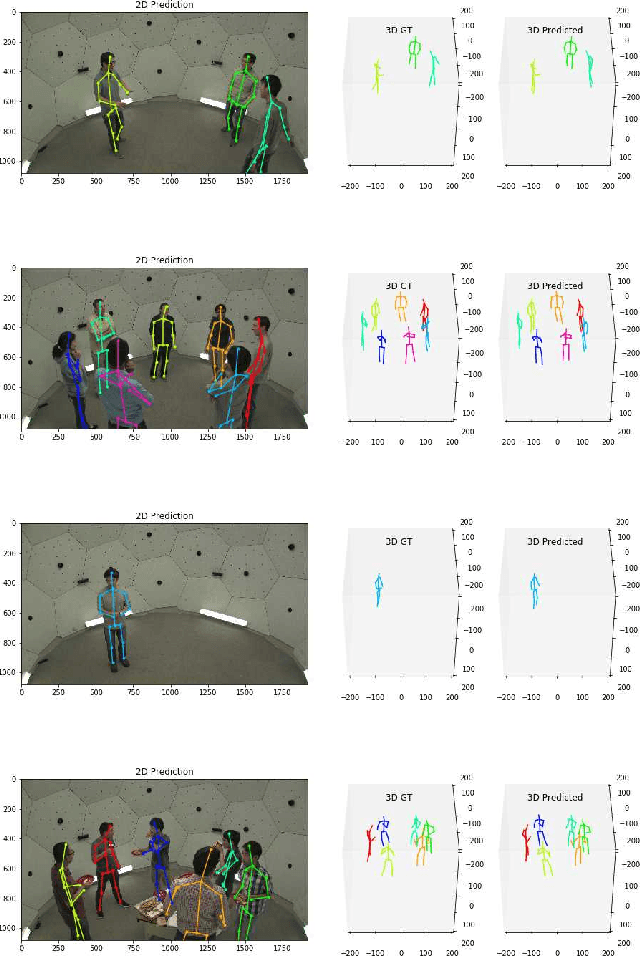
In this paper, we propose a new single shot method for multi-person 3D human pose estimation in complex images. The model jointly learns to locate the human joints in the image, to estimate their 3D coordinates and to group these predictions into full human skeletons. The proposed method deals with a variable number of people and does not need bounding boxes to estimate the 3D poses. It leverages and extends the Stacked Hourglass Network and its multi-scale feature learning to manage multi-person situations. Thus, we exploit a robust 3D human pose formulation to fully describe several 3D human poses even in case of strong occlusions or crops. Then, joint grouping and human pose estimation for an arbitrary number of people are performed using the associative embedding method. Our approach significantly outperforms the state of the art on the challenging CMU Panoptic. Furthermore, it leads to good results on the complex and synthetic images from the newly proposed JTA Dataset.