 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Data Scarcity in Psychological Defense Classification with Context-Aware Synthetic Augmentation
May 14, 2026Psychological defense mechanisms (PDMs) are unconscious cognitive processes that modulate how individuals perceive and respond to emotional distress. Automatically classifying PDMs from text is clinically valuable but severely hindered by data scarcity and class imbalance, challenges which generative augmentation alone cannot resolve without psychological grounding. In this work, we address these challenges in the PsyDefDetect shared task (BioNLP@ACL 2026) by proposing a context-aware synthetic augmentation framework combined with a hybrid classification model. Our hybrid model integrates contextual language representations with basic clinical features, along with 150 annotated defense items. Experiments demonstrate that definition quality in prompting directly governs generation fidelity and downstream performance. Our method surpasses DMRS Co-Pilot, reaching an accuracy of 58.26% (+40.25%) and a macro-F1 of 24.62% (+15.99%), thereby establishing a strong baseline for psychologically grounded defense mechanism classification in low-resource settings. Source code is available at: https://github.com/htdgv/CASA-PDC.
xMOD: Cross-Modal Distillation for 2D/3D Multi-Object Discovery from 2D motion
Mar 19, 2025



Object discovery, which refers to the task of localizing objects without human annotations, has gained significant attention in 2D image analysis. However, despite this growing interest, it remains under-explored in 3D data, where approaches rely exclusively on 3D motion, despite its several challenges. In this paper, we present a novel framework that leverages advances in 2D object discovery which are based on 2D motion to exploit the advantages of such motion cues being more flexible and generalizable and to bridge the gap between 2D and 3D modalities. Our primary contributions are twofold: (i) we introduce DIOD-3D, the first baseline for multi-object discovery in 3D data using 2D motion, incorporating scene completion as an auxiliary task to enable dense object localization from sparse input data; (ii) we develop xMOD, a cross-modal training framework that integrates 2D and 3D data while always using 2D motion cues. xMOD employs a teacher-student training paradigm across the two modalities to mitigate confirmation bias by leveraging the domain gap. During inference, the model supports both RGB-only and point cloud-only inputs. Additionally, we propose a late-fusion technique tailored to our pipeline that further enhances performance when both modalities are available at inference. We evaluate our approach extensively on synthetic (TRIP-PD) and challenging real-world datasets (KITTI and Waymo). Notably, our approach yields a substantial performance improvement compared with the 2D object discovery state-of-the-art on all datasets with gains ranging from +8.7 to +15.1 in F1@50 score. The code is available at https://github.com/CEA-LIST/xMOD
ALPI: Auto-Labeller with Proxy Injection for 3D Object Detection using 2D Labels Only
Jul 24, 2024



3D object detection plays a crucial role in various applications such as autonomous vehicles, robotics and augmented reality. However, training 3D detectors requires a costly precise annotation, which is a hindrance to scaling annotation to large datasets. To address this challenge, we propose a weakly supervised 3D annotator that relies solely on 2D bounding box annotations from images, along with size priors. One major problem is that supervising a 3D detection model using only 2D boxes is not reliable due to ambiguities between different 3D poses and their identical 2D projection. We introduce a simple yet effective and generic solution: we build 3D proxy objects with annotations by construction and add them to the training dataset. Our method requires only size priors to adapt to new classes. To better align 2D supervision with 3D detection, our method ensures depth invariance with a novel expression of the 2D losses. Finally, to detect more challenging instances, our annotator follows an offline pseudo-labelling scheme which gradually improves its 3D pseudo-labels. Extensive experiments on the KITTI dataset demonstrate that our method not only performs on-par or above previous works on the Car category, but also achieves performance close to fully supervised methods on more challenging classes. We further demonstrate the effectiveness and robustness of our method by being the first to experiment on the more challenging nuScenes dataset. We additionally propose a setting where weak labels are obtained from a 2D detector pre-trained on MS-COCO instead of human annotations.
3D-COCO: extension of MS-COCO dataset for image detection and 3D reconstruction modules
Apr 08, 2024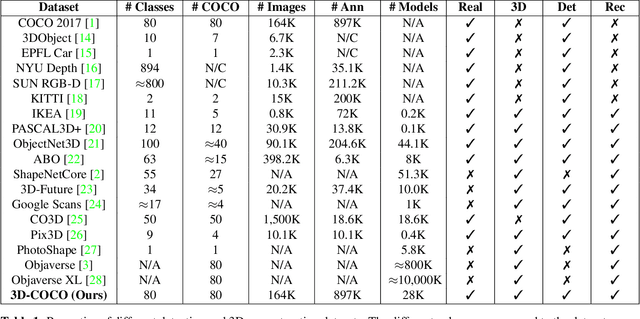

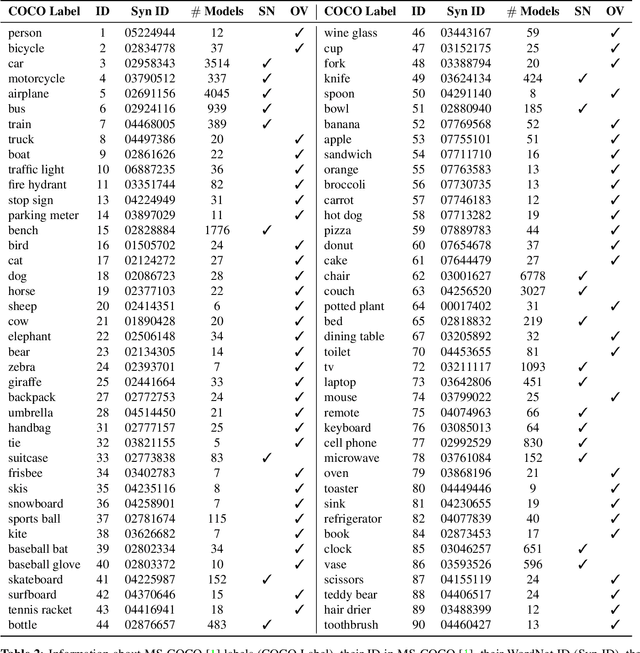
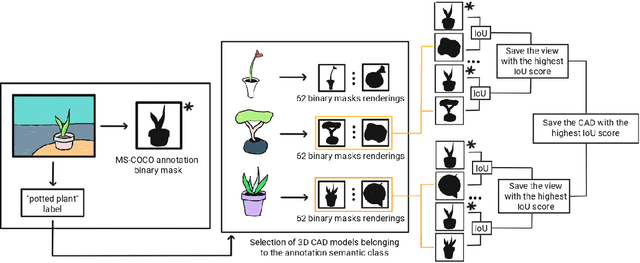
We introduce 3D-COCO, an extension of the original MS-COCO dataset providing 3D models and 2D-3D alignment annotations. 3D-COCO was designed to achieve computer vision tasks such as 3D reconstruction or image detection configurable with textual, 2D image, and 3D CAD model queries. We complete the existing MS-COCO dataset with 28K 3D models collected on ShapeNet and Objaverse. By using an IoU-based method, we match each MS-COCO annotation with the best 3D models to provide a 2D-3D alignment. The open-source nature of 3D-COCO is a premiere that should pave the way for new research on 3D-related topics. The dataset and its source codes is available at https://kalisteo.cea.fr/index.php/coco3d-object-detection-and-reconstruction/
The Background Also Matters: Background-Aware Motion-Guided Objects Discovery
Nov 05, 2023



Recent works have shown that objects discovery can largely benefit from the inherent motion information in video data. However, these methods lack a proper background processing, resulting in an over-segmentation of the non-object regions into random segments. This is a critical limitation given the unsupervised setting, where object segments and noise are not distinguishable. To address this limitation we propose BMOD, a Background-aware Motion-guided Objects Discovery method. Concretely, we leverage masks of moving objects extracted from optical flow and design a learning mechanism to extend them to the true foreground composed of both moving and static objects. The background, a complementary concept of the learned foreground class, is then isolated in the object discovery process. This enables a joint learning of the objects discovery task and the object/non-object separation. The conducted experiments on synthetic and real-world datasets show that integrating our background handling with various cutting-edge methods brings each time a considerable improvement. Specifically, we improve the objects discovery performance with a large margin, while establishing a strong baseline for object/non-object separation.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
VIBR: Learning View-Invariant Value Functions for Robust Visual Control
Jun 14, 2023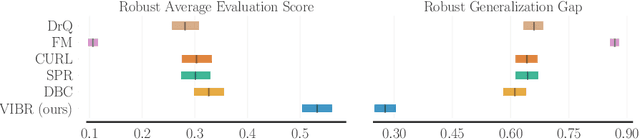
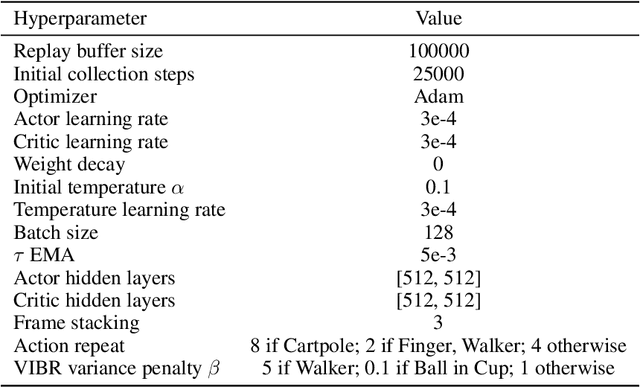
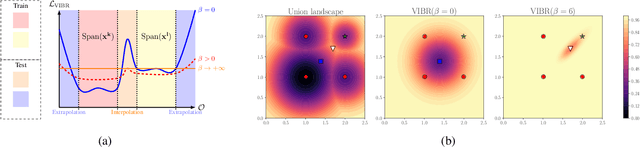
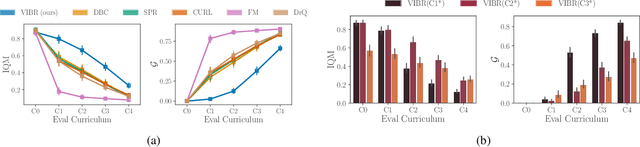
End-to-end reinforcement learning on images showed significant progress in the recent years. Data-based approach leverage data augmentation and domain randomization while representation learning methods use auxiliary losses to learn task-relevant features. Yet, reinforcement still struggles in visually diverse environments full of distractions and spurious noise. In this work, we tackle the problem of robust visual control at its core and present VIBR (View-Invariant Bellman Residuals), a method that combines multi-view training and invariant prediction to reduce out-of-distribution (OOD) generalization gap for RL based visuomotor control. Our model-free approach improve baselines performances without the need of additional representation learning objectives and with limited additional computational cost. We show that VIBR outperforms existing methods on complex visuo-motor control environment with high visual perturbation. Our approach achieves state-of the-art results on the Distracting Control Suite benchmark, a challenging benchmark still not solved by current methods, where we evaluate the robustness to a number of visual perturbators, as well as OOD generalization and extrapolation capabilities.
Image Segmentation-based Unsupervised Multiple Objects Discovery
Dec 20, 2022



Unsupervised object discovery aims to localize objects in images, while removing the dependence on annotations required by most deep learning-based methods. To address this problem, we propose a fully unsupervised, bottom-up approach, for multiple objects discovery. The proposed approach is a two-stage framework. First, instances of object parts are segmented by using the intra-image similarity between self-supervised local features. The second step merges and filters the object parts to form complete object instances. The latter is performed by two CNN models that capture semantic information on objects from the entire dataset. We demonstrate that the pseudo-labels generated by our method provide a better precision-recall trade-off than existing single and multiple objects discovery methods. In particular, we provide state-of-the-art results for both unsupervised class-agnostic object detection and unsupervised image segmentation.
Self-Supervised Pre-training of Vision Transformers for Dense Prediction Tasks
Jun 07, 2022


We present a new self-supervised pre-training of Vision Transformers for dense prediction tasks. It is based on a contrastive loss across views that compares pixel-level representations to global image representations. This strategy produces better local features suitable for dense prediction tasks as opposed to contrastive pre-training based on global image representation only. Furthermore, our approach does not suffer from a reduced batch size since the number of negative examples needed in the contrastive loss is in the order of the number of local features. We demonstrate the effectiveness of our pre-training strategy on two dense prediction tasks: semantic segmentation and monocular depth estimation.
Efficient tracking of team sport players with few game-specific annotations
Apr 08, 2022
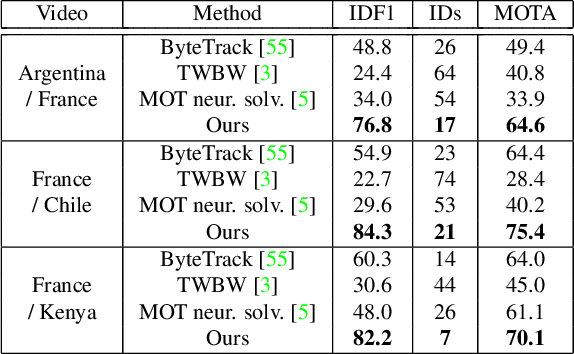
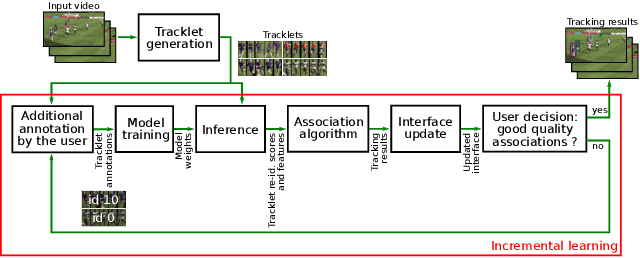
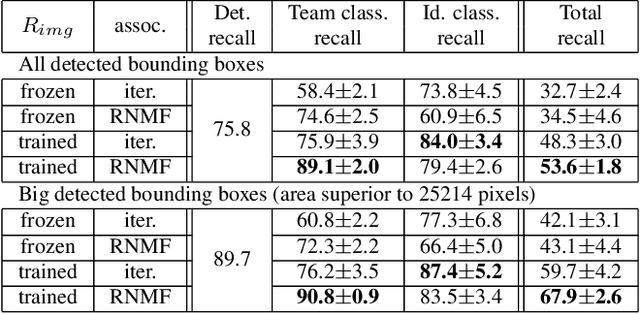
One of the requirements for team sports analysis is to track and recognize players. Many tracking and reidentification methods have been proposed in the context of video surveillance. They show very convincing results when tested on public datasets such as the MOT challenge. However, the performance of these methods are not as satisfactory when applied to player tracking. Indeed, in addition to moving very quickly and often being occluded, the players wear the same jersey, which makes the task of reidentification very complex. Some recent tracking methods have been developed more specifically for the team sport context. Due to the lack of public data, these methods use private datasets that make impossible a comparison with them. In this paper, we propose a new generic method to track team sport players during a full game thanks to few human annotations collected via a semi-interactive system. Non-ambiguous tracklets and their appearance features are automatically generated with a detection and a reidentification network both pre-trained on public datasets. Then an incremental learning mechanism trains a Transformer to classify identities using few game-specific human annotations. Finally, tracklets are linked by an association algorithm. We demonstrate the efficiency of our approach on a challenging rugby sevens dataset. To overcome the lack of public sports tracking dataset, we publicly release this dataset at https://kalisteo.cea.fr/index.php/free-resources/. We also show that our method is able to track rugby sevens players during a full match, if they are observable at a minimal resolution, with the annotation of only 6 few seconds length tracklets per player.