 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarNav: An Autonomous Driving Benchmark for Segmentation of Navigable Zones in War Scenes
Nov 19, 2025We introduce WarNav, a novel real-world dataset constructed from images of the open-source DATTALION repository, specifically tailored to enable the development and benchmarking of semantic segmentation models for autonomous ground vehicle navigation in unstructured, conflict-affected environments. This dataset addresses a critical gap between conventional urban driving resources and the unique operational scenarios encountered by unmanned systems in hazardous and damaged war-zones. We detail the methodological challenges encountered, ranging from data heterogeneity to ethical considerations, providing guidance for future efforts that target extreme operational contexts. To establish performance references, we report baseline results on WarNav using several state-of-the-art semantic segmentation models trained on structured urban scenes. We further analyse the impact of training data environments and propose a first step towards effective navigability in challenging environments with the constraint of having no annotation of the targeted images. Our goal is to foster impactful research that enhances the robustness and safety of autonomous vehicles in high-risk scenarios while being frugal in annotated data.
xMOD: Cross-Modal Distillation for 2D/3D Multi-Object Discovery from 2D motion
Mar 19, 2025



Object discovery, which refers to the task of localizing objects without human annotations, has gained significant attention in 2D image analysis. However, despite this growing interest, it remains under-explored in 3D data, where approaches rely exclusively on 3D motion, despite its several challenges. In this paper, we present a novel framework that leverages advances in 2D object discovery which are based on 2D motion to exploit the advantages of such motion cues being more flexible and generalizable and to bridge the gap between 2D and 3D modalities. Our primary contributions are twofold: (i) we introduce DIOD-3D, the first baseline for multi-object discovery in 3D data using 2D motion, incorporating scene completion as an auxiliary task to enable dense object localization from sparse input data; (ii) we develop xMOD, a cross-modal training framework that integrates 2D and 3D data while always using 2D motion cues. xMOD employs a teacher-student training paradigm across the two modalities to mitigate confirmation bias by leveraging the domain gap. During inference, the model supports both RGB-only and point cloud-only inputs. Additionally, we propose a late-fusion technique tailored to our pipeline that further enhances performance when both modalities are available at inference. We evaluate our approach extensively on synthetic (TRIP-PD) and challenging real-world datasets (KITTI and Waymo). Notably, our approach yields a substantial performance improvement compared with the 2D object discovery state-of-the-art on all datasets with gains ranging from +8.7 to +15.1 in F1@50 score. The code is available at https://github.com/CEA-LIST/xMOD
Open-set object detection: towards unified problem formulation and benchmarking
Nov 08, 2024
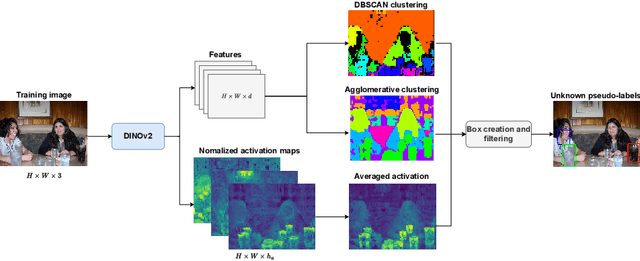


In real-world applications where confidence is key, like autonomous driving, the accurate detection and appropriate handling of classes differing from those used during training are crucial. Despite the proposal of various unknown object detection approaches, we have observed widespread inconsistencies among them regarding the datasets, metrics, and scenarios used, alongside a notable absence of a clear definition for unknown objects, which hampers meaningful evaluation. To counter these issues, we introduce two benchmarks: a unified VOC-COCO evaluation, and the new OpenImagesRoad benchmark which provides clear hierarchical object definition besides new evaluation metrics. Complementing the benchmark, we exploit recent self-supervised Vision Transformers performance, to improve pseudo-labeling-based OpenSet Object Detection (OSOD), through OW-DETR++. State-of-the-art methods are extensively evaluated on the proposed benchmarks. This study provides a clear problem definition, ensures consistent evaluations, and draws new conclusions about effectiveness of OSOD strategies.
The Background Also Matters: Background-Aware Motion-Guided Objects Discovery
Nov 05, 2023



Recent works have shown that objects discovery can largely benefit from the inherent motion information in video data. However, these methods lack a proper background processing, resulting in an over-segmentation of the non-object regions into random segments. This is a critical limitation given the unsupervised setting, where object segments and noise are not distinguishable. To address this limitation we propose BMOD, a Background-aware Motion-guided Objects Discovery method. Concretely, we leverage masks of moving objects extracted from optical flow and design a learning mechanism to extend them to the true foreground composed of both moving and static objects. The background, a complementary concept of the learned foreground class, is then isolated in the object discovery process. This enables a joint learning of the objects discovery task and the object/non-object separation. The conducted experiments on synthetic and real-world datasets show that integrating our background handling with various cutting-edge methods brings each time a considerable improvement. Specifically, we improve the objects discovery performance with a large margin, while establishing a strong baseline for object/non-object separation.
Image Segmentation-based Unsupervised Multiple Objects Discovery
Dec 20, 2022



Unsupervised object discovery aims to localize objects in images, while removing the dependence on annotations required by most deep learning-based methods. To address this problem, we propose a fully unsupervised, bottom-up approach, for multiple objects discovery. The proposed approach is a two-stage framework. First, instances of object parts are segmented by using the intra-image similarity between self-supervised local features. The second step merges and filters the object parts to form complete object instances. The latter is performed by two CNN models that capture semantic information on objects from the entire dataset. We demonstrate that the pseudo-labels generated by our method provide a better precision-recall trade-off than existing single and multiple objects discovery methods. In particular, we provide state-of-the-art results for both unsupervised class-agnostic object detection and unsupervised image segmentation.