 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deleuzian Representation Hypothesis
Dec 17, 2025We propose an alternative to sparse autoencoders (SAEs) as a simple and effective unsupervised method for extracting interpretable concepts from neural networks. The core idea is to cluster differences in activations, which we formally justify within a discriminant analysis framework. To enhance the diversity of extracted concepts, we refine the approach by weighting the clustering using the skewness of activations. The method aligns with Deleuze's modern view of concepts as differences. We evaluate the approach across five models and three modalities (vision, language, and audio), measuring concept quality, diversity, and consistency. Our results show that the proposed method achieves concept quality surpassing prior unsupervised SAE variants while approaching supervised baselines, and that the extracted concepts enable steering of a model's inner representations, demonstrating their causal influence on downstream behavior.
Reliable and Reproducible Demographic Inference for Fairness in Face Analysis
Oct 23, 2025Fairness evaluation in face analysis systems (FAS) typically depends on automatic demographic attribute inference (DAI), which itself relies on predefined demographic segmentation. However, the validity of fairness auditing hinges on the reliability of the DAI process. We begin by providing a theoretical motivation for this dependency, showing that improved DAI reliability leads to less biased and lower-variance estimates of FAS fairness. To address this, we propose a fully reproducible DAI pipeline that replaces conventional end-to-end training with a modular transfer learning approach. Our design integrates pretrained face recognition encoders with non-linear classification heads. We audit this pipeline across three dimensions: accuracy, fairness, and a newly introduced notion of robustness, defined via intra-identity consistency. The proposed robustness metric is applicable to any demographic segmentation scheme. We benchmark the pipeline on gender and ethnicity inference across multiple datasets and training setups. Our results show that the proposed method outperforms strong baselines, particularly on ethnicity, which is the more challenging attribute. To promote transparency and reproducibility, we will publicly release the training dataset metadata, full codebase, pretrained models, and evaluation toolkit. This work contributes a reliable foundation for demographic inference in fairness auditing.
MVAT: Multi-View Aware Teacher for Weakly Supervised 3D Object Detection
Sep 09, 2025Annotating 3D data remains a costly bottleneck for 3D object detection, motivating the development of weakly supervised annotation methods that rely on more accessible 2D box annotations. However, relying solely on 2D boxes introduces projection ambiguities since a single 2D box can correspond to multiple valid 3D poses. Furthermore, partial object visibility under a single viewpoint setting makes accurate 3D box estimation difficult. We propose MVAT, a novel framework that leverages temporal multi-view present in sequential data to address these challenges. Our approach aggregates object-centric point clouds across time to build 3D object representations as dense and complete as possible. A Teacher-Student distillation paradigm is employed: The Teacher network learns from single viewpoints but targets are derived from temporally aggregated static objects. Then the Teacher generates high quality pseudo-labels that the Student learns to predict from a single viewpoint for both static and moving objects. The whole framework incorporates a multi-view 2D projection loss to enforce consistency between predicted 3D boxes and all available 2D annotations. Experiments on the nuScenes and Waymo Open datasets demonstrate that MVAT achieves state-of-the-art performance for weakly supervised 3D object detection, significantly narrowing the gap with fully supervised methods without requiring any 3D box annotations. % \footnote{Code available upon acceptance} Our code is available in our public repository (\href{https://github.com/CEA-LIST/MVAT}{code}).
Text-to-Image Alignment in Denoising-Based Models through Step Selection
Apr 24, 2025Visual generative AI models often encounter challenges related to text-image alignment and reasoning limitations. This paper presents a novel method for selectively enhancing the signal at critical denoising steps, optimizing image generation based on input semantics. Our approach addresses the shortcomings of early-stage signal modifications, demonstrating that adjustments made at later stages yield superior results. We conduct extensive experiments to validate the effectiveness of our method in producing semantically aligned images on Diffusion and Flow Matching model, achieving state-of-the-art performance. Our results highlight the importance of a judicious choice of sampling stage to improve performance and overall image alignment.
xMOD: Cross-Modal Distillation for 2D/3D Multi-Object Discovery from 2D motion
Mar 19, 2025



Object discovery, which refers to the task of localizing objects without human annotations, has gained significant attention in 2D image analysis. However, despite this growing interest, it remains under-explored in 3D data, where approaches rely exclusively on 3D motion, despite its several challenges. In this paper, we present a novel framework that leverages advances in 2D object discovery which are based on 2D motion to exploit the advantages of such motion cues being more flexible and generalizable and to bridge the gap between 2D and 3D modalities. Our primary contributions are twofold: (i) we introduce DIOD-3D, the first baseline for multi-object discovery in 3D data using 2D motion, incorporating scene completion as an auxiliary task to enable dense object localization from sparse input data; (ii) we develop xMOD, a cross-modal training framework that integrates 2D and 3D data while always using 2D motion cues. xMOD employs a teacher-student training paradigm across the two modalities to mitigate confirmation bias by leveraging the domain gap. During inference, the model supports both RGB-only and point cloud-only inputs. Additionally, we propose a late-fusion technique tailored to our pipeline that further enhances performance when both modalities are available at inference. We evaluate our approach extensively on synthetic (TRIP-PD) and challenging real-world datasets (KITTI and Waymo). Notably, our approach yields a substantial performance improvement compared with the 2D object discovery state-of-the-art on all datasets with gains ranging from +8.7 to +15.1 in F1@50 score. The code is available at https://github.com/CEA-LIST/xMOD
Fairer Analysis and Demographically Balanced Face Generation for Fairer Face Verification
Dec 04, 2024Face recognition and verification are two computer vision tasks whose performances have advanced with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive nature of face data and biases in real-world training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems remain. Using the existing DCFace SOTA framework, we introduce a new controlled generation pipeline that improves fairness. Through classical fairness metrics and a proposed in-depth statistical analysis based on logit models and ANOVA, we show that our generation pipeline improves fairness more than other bias mitigation approaches while slightly improving raw performance.
Automatic Die Studies for Ancient Numismatics
Jul 30, 2024

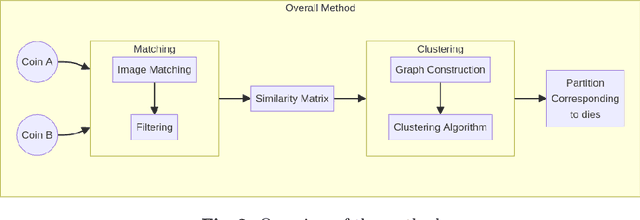
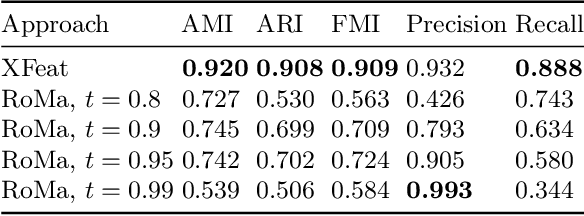
Die studies are fundamental to quantifying ancient monetary production, providing insights into the relationship between coinage, politics, and history. The process requires tedious manual work, which limits the size of the corpora that can be studied. Few works have attempted to automate this task, and none have been properly released and evaluated from a computer vision perspective. We propose a fully automatic approach that introduces several innovations compared to previous methods. We rely on fast and robust local descriptors matching that is set automatically. Second, the core of our proposal is a clustering-based approach that uses an intrinsic metric (that does not need the ground truth labels) to determine its critical hyper-parameters. We validate the approach on two corpora of Greek coins, propose an automatic implementation and evaluation of previous baselines, and show that our approach significantly outperforms them.
ALPI: Auto-Labeller with Proxy Injection for 3D Object Detection using 2D Labels Only
Jul 24, 2024



3D object detection plays a crucial role in various applications such as autonomous vehicles, robotics and augmented reality. However, training 3D detectors requires a costly precise annotation, which is a hindrance to scaling annotation to large datasets. To address this challenge, we propose a weakly supervised 3D annotator that relies solely on 2D bounding box annotations from images, along with size priors. One major problem is that supervising a 3D detection model using only 2D boxes is not reliable due to ambiguities between different 3D poses and their identical 2D projection. We introduce a simple yet effective and generic solution: we build 3D proxy objects with annotations by construction and add them to the training dataset. Our method requires only size priors to adapt to new classes. To better align 2D supervision with 3D detection, our method ensures depth invariance with a novel expression of the 2D losses. Finally, to detect more challenging instances, our annotator follows an offline pseudo-labelling scheme which gradually improves its 3D pseudo-labels. Extensive experiments on the KITTI dataset demonstrate that our method not only performs on-par or above previous works on the Car category, but also achieves performance close to fully supervised methods on more challenging classes. We further demonstrate the effectiveness and robustness of our method by being the first to experiment on the more challenging nuScenes dataset. We additionally propose a setting where weak labels are obtained from a 2D detector pre-trained on MS-COCO instead of human annotations.
Toward Fairer Face Recognition Datasets
Jun 24, 2024



Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
Smooth Pseudo-Labeling
May 23, 2024



Semi-Supervised Learning (SSL) seeks to leverage large amounts of non-annotated data along with the smallest amount possible of annotated data in order to achieve the same level of performance as if all data were annotated. A fruitful method in SSL is Pseudo-Labeling (PL), which, however, suffers from the important drawback that the associated loss function has discontinuities in its derivatives, which cause instabilities in performance when labels are very scarce. In the present work, we address this drawback with the introduction of a Smooth Pseudo-Labeling (SP L) loss function. It consists in adding a multiplicative factor in the loss function that smooths out the discontinuities in the derivative due to thresholding. In our experiments, we test our improvements on FixMatch and show that it significantly improves the performance in the regime of scarce labels, without addition of any modules, hyperparameters, or computational overhead. In the more stable regime of abundant labels, performance remains at the same level. Robustness with respect to variation of hyperparameters and training parameters is also significantly improved. Moreover, we introduce a new benchmark, where labeled images are selected randomly from the whole dataset, without imposing representation of each class proportional to its frequency in the dataset. We see that the smooth version of FixMatch does appear to perform better than the original, non-smooth implementation. However, more importantly, we notice that both implementations do not necessarily see their performance improve when labeled images are added, an important issue in the design of SSL algorithms that should be addressed so that Active Learning algorithms become more reliable and explainable.