 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deleuzian Representation Hypothesis
Dec 17, 2025We propose an alternative to sparse autoencoders (SAEs) as a simple and effective unsupervised method for extracting interpretable concepts from neural networks. The core idea is to cluster differences in activations, which we formally justify within a discriminant analysis framework. To enhance the diversity of extracted concepts, we refine the approach by weighting the clustering using the skewness of activations. The method aligns with Deleuze's modern view of concepts as differences. We evaluate the approach across five models and three modalities (vision, language, and audio), measuring concept quality, diversity, and consistency. Our results show that the proposed method achieves concept quality surpassing prior unsupervised SAE variants while approaching supervised baselines, and that the extracted concepts enable steering of a model's inner representations, demonstrating their causal influence on downstream behavior.
ManufactuBERT: Efficient Continual Pretraining for Manufacturing
Nov 07, 2025While large general-purpose Transformer-based encoders excel at general language understanding, their performance diminishes in specialized domains like manufacturing due to a lack of exposure to domain-specific terminology and semantics. In this paper, we address this gap by introducing ManufactuBERT, a RoBERTa model continually pretrained on a large-scale corpus curated for the manufacturing domain. We present a comprehensive data processing pipeline to create this corpus from web data, involving an initial domain-specific filtering step followed by a multi-stage deduplication process that removes redundancies. Our experiments show that ManufactuBERT establishes a new state-of-the-art on a range of manufacturing-related NLP tasks, outperforming strong specialized baselines. More importantly, we demonstrate that training on our carefully deduplicated corpus significantly accelerates convergence, leading to a 33\% reduction in training time and computational cost compared to training on the non-deduplicated dataset. The proposed pipeline offers a reproducible example for developing high-performing encoders in other specialized domains. We will release our model and curated corpus at https://huggingface.co/cea-list-ia.
GLiDRE: Generalist Lightweight model for Document-level Relation Extraction
Aug 01, 2025Relation Extraction (RE) is a fundamental task in Natural Language Processing, and its document-level variant poses significant challenges, due to the need to model complex interactions between entities across sentences. Current approaches, largely based on the ATLOP architecture, are commonly evaluated on benchmarks like DocRED and Re-DocRED. However, their performance in zero-shot or few-shot settings remains largely underexplored due to the task's complexity. Recently, the GLiNER model has shown that a compact NER model can outperform much larger Large Language Models. With a similar motivation, we introduce GLiDRE, a new model for document-level relation extraction that builds on the key ideas of GliNER. We benchmark GLiDRE against state-of-the-art models across various data settings on the Re-DocRED dataset. Our results demonstrate that GLiDRE achieves state-of-the-art performance in few-shot scenarios. Our code is publicly available.
From LIMA to DeepLIMA: following a new path of interoperability
Sep 10, 2024In this article, we describe the architecture of the LIMA (Libre Multilingual Analyzer) framework and its recent evolution with the addition of new text analysis modules based on deep neural networks. We extended the functionality of LIMA in terms of the number of supported languages while preserving existing configurable architecture and the availability of previously developed rule-based and statistical analysis components. Models were trained for more than 60 languages on the Universal Dependencies 2.5 corpora, WikiNer corpora, and CoNLL-03 dataset. Universal Dependencies allowed us to increase the number of supported languages and to generate models that could be integrated into other platforms. This integration of ubiquitous Deep Learning Natural Language Processing models and the use of standard annotated collections using Universal Dependencies can be viewed as a new path of interoperability, through the normalization of models and data, that are complementary to a more standard technical interoperability, implemented in LIMA through services available in Docker containers on Docker Hub.
Automatic Die Studies for Ancient Numismatics
Jul 30, 2024

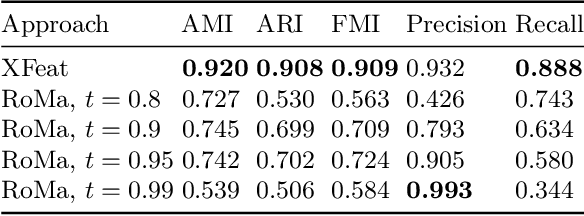
Die studies are fundamental to quantifying ancient monetary production, providing insights into the relationship between coinage, politics, and history. The process requires tedious manual work, which limits the size of the corpora that can be studied. Few works have attempted to automate this task, and none have been properly released and evaluated from a computer vision perspective. We propose a fully automatic approach that introduces several innovations compared to previous methods. We rely on fast and robust local descriptors matching that is set automatically. Second, the core of our proposal is a clustering-based approach that uses an intrinsic metric (that does not need the ground truth labels) to determine its critical hyper-parameters. We validate the approach on two corpora of Greek coins, propose an automatic implementation and evaluation of previous baselines, and show that our approach significantly outperforms them.
Probing Pretrained Language Models with Hierarchy Properties
Dec 15, 2023Since Pretrained Language Models (PLMs) are the cornerstone of the most recent Information Retrieval (IR) models, the way they encode semantic knowledge is particularly important. However, little attention has been given to studying the PLMs' capability to capture hierarchical semantic knowledge. Traditionally, evaluating such knowledge encoded in PLMs relies on their performance on a task-dependent evaluation approach based on proxy tasks, such as hypernymy detection. Unfortunately, this approach potentially ignores other implicit and complex taxonomic relations. In this work, we propose a task-agnostic evaluation method able to evaluate to what extent PLMs can capture complex taxonomy relations, such as ancestors and siblings. The evaluation is based on intrinsic properties that capture the hierarchical nature of taxonomies. Our experimental evaluation shows that the lexico-semantic knowledge implicitly encoded in PLMs does not always capture hierarchical relations. We further demonstrate that the proposed properties can be injected into PLMs to improve their understanding of hierarchy. Through evaluations on taxonomy reconstruction, hypernym discovery and reading comprehension tasks, we show that the knowledge about hierarchy is moderately but not systematically transferable across tasks.
Multimodal Entity Linking for Tweets
Apr 07, 2021

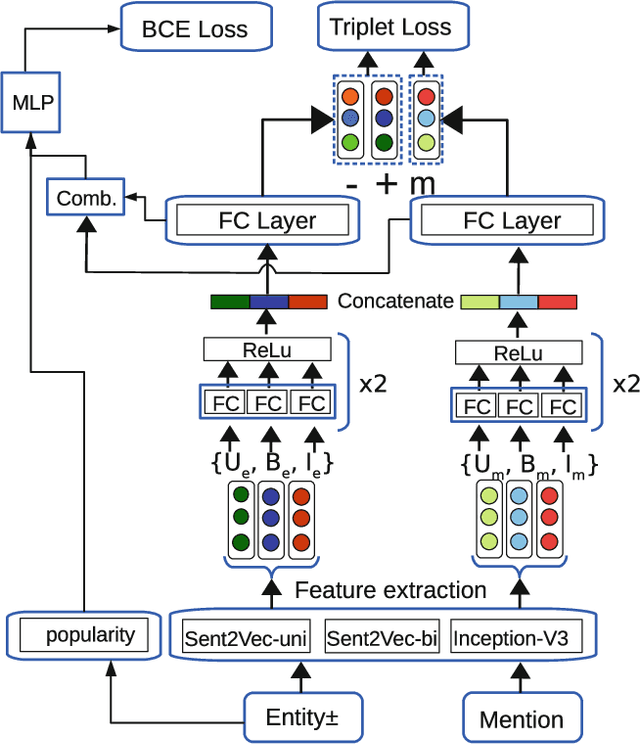

In many information extraction applications, entity linking (EL) has emerged as a crucial task that allows leveraging information about named entities from a knowledge base. In this paper, we address the task of multimodal entity linking (MEL), an emerging research field in which textual and visual information is used to map an ambiguous mention to an entity in a knowledge base (KB). First, we propose a method for building a fully annotated Twitter dataset for MEL, where entities are defined in a Twitter KB. Then, we propose a model for jointly learning a representation of both mentions and entities from their textual and visual contexts. We demonstrate the effectiveness of the proposed model by evaluating it on the proposed dataset and highlight the importance of leveraging visual information when it is available.