 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReToP: Learning to Rewrite Electronic Health Records for Clinical Prediction
Jan 27, 2026Electronic Health Records (EHRs) provide crucial information for clinical decision-making. However, their high-dimensionality, heterogeneity, and sparsity make clinical prediction challenging. Large Language Models (LLMs) allowed progress towards addressing this challenge by leveraging parametric medical knowledge to enhance EHR data for clinical prediction tasks. Despite the significant achievements made so far, most of the existing approaches are fundamentally task-agnostic in the sense that they deploy LLMs as EHR encoders or EHR completion modules without fully integrating signals from the prediction tasks. This naturally hinders task performance accuracy. In this work, we propose Rewrite-To-Predict (ReToP), an LLM-based framework that addresses this limitation through an end-to-end training of an EHR rewriter and a clinical predictor. To cope with the lack of EHR rewrite training data, we generate synthetic pseudo-labels using clinical-driven feature selection strategies to create diverse patient rewrites for fine-tuning the EHR rewriter. ReToP aligns the rewriter with prediction objectives using a novel Classifier Supervised Contribution (CSC) score that enables the EHR rewriter to generate clinically relevant rewrites that directly enhance prediction. Our ReToP framework surpasses strong baseline models across three clinical tasks on MIMIC-IV. Moreover, the analysis of ReToP shows its generalizability to unseen datasets and tasks with minimal fine-tuning while preserving faithful rewrites and emphasizing task-relevant predictive features.
* Accepted by WSDM 2026
Jointly Generating and Attributing Answers using Logits of Document-Identifier Tokens
Aug 12, 2025Despite their impressive performances, Large Language Models (LLMs) remain prone to hallucination, which critically undermines their trustworthiness. While most of the previous work focused on tackling answer and attribution correctness, a recent line of work investigated faithfulness, with a focus on leveraging internal model signals to reflect a model's actual decision-making process while generating the answer. Nevertheless, these methods induce additional latency and have shown limitations in directly aligning token generation with attribution generation. In this paper, we introduce LoDIT, a method that jointly generates and faithfully attributes answers in RAG by leveraging specific token logits during generation. It consists of two steps: (1) marking the documents with specific token identifiers and then leveraging the logits of these tokens to estimate the contribution of each document to the answer during generation, and (2) aggregating these contributions into document attributions. Experiments on a trustworthiness-focused attributed text-generation benchmark, Trust-Align, show that LoDIT significantly outperforms state-of-the-art models on several metrics. Finally, an in-depth analysis of LoDIT shows both its efficiency in terms of latency and its robustness in different settings.
Revisiting the MIMIC-IV Benchmark: Experiments Using Language Models for Electronic Health Records
Apr 29, 2025The lack of standardized evaluation benchmarks in the medical domain for text inputs can be a barrier to widely adopting and leveraging the potential of natural language models for health-related downstream tasks. This paper revisited an openly available MIMIC-IV benchmark for electronic health records (EHRs) to address this issue. First, we integrate the MIMIC-IV data within the Hugging Face datasets library to allow an easy share and use of this collection. Second, we investigate the application of templates to convert EHR tabular data to text. Experiments using fine-tuned and zero-shot LLMs on the mortality of patients task show that fine-tuned text-based models are competitive against robust tabular classifiers. In contrast, zero-shot LLMs struggle to leverage EHR representations. This study underlines the potential of text-based approaches in the medical field and highlights areas for further improvement.
PatientDx: Merging Large Language Models for Protecting Data-Privacy in Healthcare
Apr 24, 2025Fine-tuning of Large Language Models (LLMs) has become the default practice for improving model performance on a given task. However, performance improvement comes at the cost of training on vast amounts of annotated data which could be sensitive leading to significant data privacy concerns. In particular, the healthcare domain is one of the most sensitive domains exposed to data privacy issues. In this paper, we present PatientDx, a framework of model merging that allows the design of effective LLMs for health-predictive tasks without requiring fine-tuning nor adaptation on patient data. Our proposal is based on recently proposed techniques known as merging of LLMs and aims to optimize a building block merging strategy. PatientDx uses a pivotal model adapted to numerical reasoning and tunes hyperparameters on examples based on a performance metric but without training of the LLM on these data. Experiments using the mortality tasks of the MIMIC-IV dataset show improvements up to 7% in terms of AUROC when compared to initial models. Additionally, we confirm that when compared to fine-tuned models, our proposal is less prone to data leak problems without hurting performance. Finally, we qualitatively show the capabilities of our proposal through a case study. Our best model is publicly available at https://huggingface.co/ Jgmorenof/mistral\_merged\_0\_4.
Evaluating LLM Abilities to Understand Tabular Electronic Health Records: A Comprehensive Study of Patient Data Extraction and Retrieval
Jan 16, 2025Electronic Health Record (EHR) tables pose unique challenges among which is the presence of hidden contextual dependencies between medical features with a high level of data dimensionality and sparsity. This study presents the first investigation into the abilities of LLMs to comprehend EHRs for patient data extraction and retrieval. We conduct extensive experiments using the MIMICSQL dataset to explore the impact of the prompt structure, instruction, context, and demonstration, of two backbone LLMs, Llama2 and Meditron, based on task performance. Through quantitative and qualitative analyses, our findings show that optimal feature selection and serialization methods can enhance task performance by up to 26.79% compared to naive approaches. Similarly, in-context learning setups with relevant example selection improve data extraction performance by 5.95%. Based on our study findings, we propose guidelines that we believe would help the design of LLM-based models to support health search.
An Evaluation Framework for Attributed Information Retrieval using Large Language Models
Sep 12, 2024With the growing success of Large Language models (LLMs) in information-seeking scenarios, search engines are now adopting generative approaches to provide answers along with in-line citations as attribution. While existing work focuses mainly on attributed question answering, in this paper, we target information-seeking scenarios which are often more challenging due to the open-ended nature of the queries and the size of the label space in terms of the diversity of candidate-attributed answers per query. We propose a reproducible framework to evaluate and benchmark attributed information seeking, using any backbone LLM, and different architectural designs: (1) Generate (2) Retrieve then Generate, and (3) Generate then Retrieve. Experiments using HAGRID, an attributed information-seeking dataset, show the impact of different scenarios on both the correctness and attributability of answers.
Probing Pretrained Language Models with Hierarchy Properties
Dec 15, 2023Since Pretrained Language Models (PLMs) are the cornerstone of the most recent Information Retrieval (IR) models, the way they encode semantic knowledge is particularly important. However, little attention has been given to studying the PLMs' capability to capture hierarchical semantic knowledge. Traditionally, evaluating such knowledge encoded in PLMs relies on their performance on a task-dependent evaluation approach based on proxy tasks, such as hypernymy detection. Unfortunately, this approach potentially ignores other implicit and complex taxonomic relations. In this work, we propose a task-agnostic evaluation method able to evaluate to what extent PLMs can capture complex taxonomy relations, such as ancestors and siblings. The evaluation is based on intrinsic properties that capture the hierarchical nature of taxonomies. Our experimental evaluation shows that the lexico-semantic knowledge implicitly encoded in PLMs does not always capture hierarchical relations. We further demonstrate that the proposed properties can be injected into PLMs to improve their understanding of hierarchy. Through evaluations on taxonomy reconstruction, hypernym discovery and reading comprehension tasks, we show that the knowledge about hierarchy is moderately but not systematically transferable across tasks.
Does Structure Matter? Leveraging Data-to-Text Generation for Answering Complex Information Needs
Dec 08, 2021

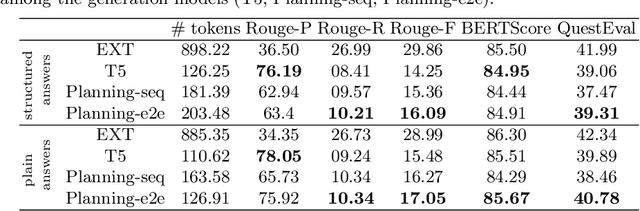

In this work, our aim is to provide a structured answer in natural language to a complex information need. Particularly, we envision using generative models from the perspective of data-to-text generation. We propose the use of a content selection and planning pipeline which aims at structuring the answer by generating intermediate plans. The experimental evaluation is performed using the TREC Complex Answer Retrieval (CAR) dataset. We evaluate both the generated answer and its corresponding structure and show the effectiveness of planning-based models in comparison to a text-to-text model.
Studying Catastrophic Forgetting in Neural Ranking Models
Jan 18, 2021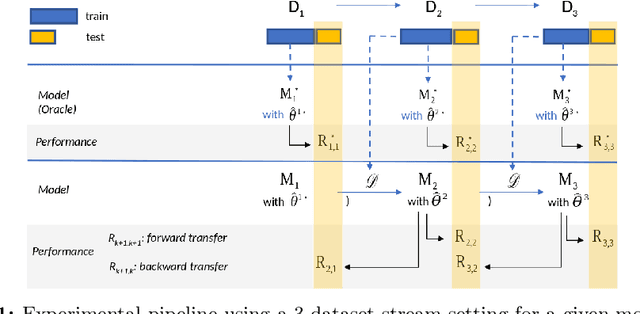


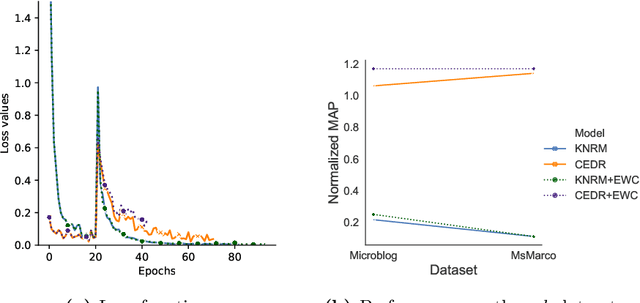
Several deep neural ranking models have been proposed in the recent IR literature. While their transferability to one target domain held by a dataset has been widely addressed using traditional domain adaptation strategies, the question of their cross-domain transferability is still under-studied. We study here in what extent neural ranking models catastrophically forget old knowledge acquired from previously observed domains after acquiring new knowledge, leading to performance decrease on those domains. Our experiments show that the effectiveness of neuralIR ranking models is achieved at the cost of catastrophic forgetting and that a lifelong learning strategy using a cross-domain regularizer success-fully mitigates the problem. Using an explanatory approach built on a regression model, we also show the effect of domain characteristics on the rise of catastrophic forgetting. We believe that the obtained results can be useful for both theoretical and practical future work in neural IR.
DSRIM: A Deep Neural Information Retrieval Model Enhanced by a Knowledge Resource Driven Representation of Documents
Jul 27, 2017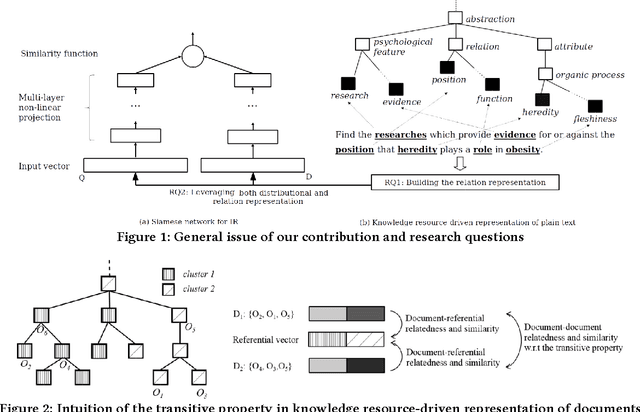

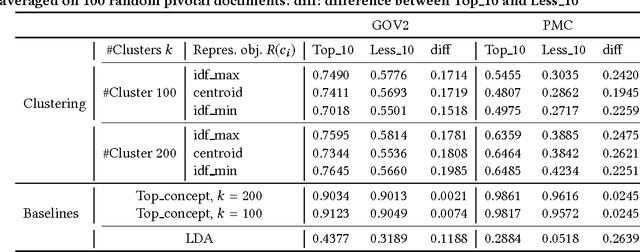
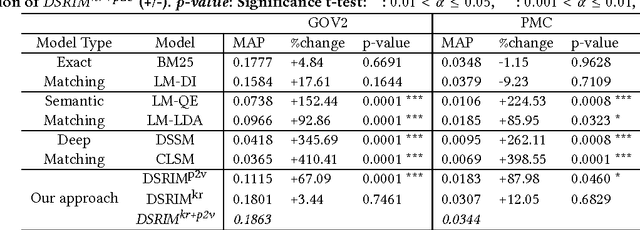
The state-of-the-art solutions to the vocabulary mismatch in information retrieval (IR) mainly aim at leveraging either the relational semantics provided by external resources or the distributional semantics, recently investigated by deep neural approaches. Guided by the intuition that the relational semantics might improve the effectiveness of deep neural approaches, we propose the Deep Semantic Resource Inference Model (DSRIM) that relies on: 1) a representation of raw-data that models the relational semantics of text by jointly considering objects and relations expressed in a knowledge resource, and 2) an end-to-end neural architecture that learns the query-document relevance by leveraging the distributional and relational semantics of documents and queries. The experimental evaluation carried out on two TREC datasets from TREC Terabyte and TREC CDS tracks relying respectively on WordNet and MeSH resources, indicates that our model outperforms state-of-the-art semantic and deep neural IR models.