 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReToP: Learning to Rewrite Electronic Health Records for Clinical Prediction
Jan 27, 2026Electronic Health Records (EHRs) provide crucial information for clinical decision-making. However, their high-dimensionality, heterogeneity, and sparsity make clinical prediction challenging. Large Language Models (LLMs) allowed progress towards addressing this challenge by leveraging parametric medical knowledge to enhance EHR data for clinical prediction tasks. Despite the significant achievements made so far, most of the existing approaches are fundamentally task-agnostic in the sense that they deploy LLMs as EHR encoders or EHR completion modules without fully integrating signals from the prediction tasks. This naturally hinders task performance accuracy. In this work, we propose Rewrite-To-Predict (ReToP), an LLM-based framework that addresses this limitation through an end-to-end training of an EHR rewriter and a clinical predictor. To cope with the lack of EHR rewrite training data, we generate synthetic pseudo-labels using clinical-driven feature selection strategies to create diverse patient rewrites for fine-tuning the EHR rewriter. ReToP aligns the rewriter with prediction objectives using a novel Classifier Supervised Contribution (CSC) score that enables the EHR rewriter to generate clinically relevant rewrites that directly enhance prediction. Our ReToP framework surpasses strong baseline models across three clinical tasks on MIMIC-IV. Moreover, the analysis of ReToP shows its generalizability to unseen datasets and tasks with minimal fine-tuning while preserving faithful rewrites and emphasizing task-relevant predictive features.
* Accepted by WSDM 2026
COSMMIC: Comment-Sensitive Multimodal Multilingual Indian Corpus for Summarization and Headline Generation
Jun 18, 2025Despite progress in comment-aware multimodal and multilingual summarization for English and Chinese, research in Indian languages remains limited. This study addresses this gap by introducing COSMMIC, a pioneering comment-sensitive multimodal, multilingual dataset featuring nine major Indian languages. COSMMIC comprises 4,959 article-image pairs and 24,484 reader comments, with ground-truth summaries available in all included languages. Our approach enhances summaries by integrating reader insights and feedback. We explore summarization and headline generation across four configurations: (1) using article text alone, (2) incorporating user comments, (3) utilizing images, and (4) combining text, comments, and images. To assess the dataset's effectiveness, we employ state-of-the-art language models such as LLama3 and GPT-4. We conduct a comprehensive study to evaluate different component combinations, including identifying supportive comments, filtering out noise using a dedicated comment classifier using IndicBERT, and extracting valuable insights from images with a multilingual CLIP-based classifier. This helps determine the most effective configurations for natural language generation (NLG) tasks. Unlike many existing datasets that are either text-only or lack user comments in multimodal settings, COSMMIC uniquely integrates text, images, and user feedback. This holistic approach bridges gaps in Indian language resources, advancing NLP research and fostering inclusivity.
Revisiting the MIMIC-IV Benchmark: Experiments Using Language Models for Electronic Health Records
Apr 29, 2025The lack of standardized evaluation benchmarks in the medical domain for text inputs can be a barrier to widely adopting and leveraging the potential of natural language models for health-related downstream tasks. This paper revisited an openly available MIMIC-IV benchmark for electronic health records (EHRs) to address this issue. First, we integrate the MIMIC-IV data within the Hugging Face datasets library to allow an easy share and use of this collection. Second, we investigate the application of templates to convert EHR tabular data to text. Experiments using fine-tuned and zero-shot LLMs on the mortality of patients task show that fine-tuned text-based models are competitive against robust tabular classifiers. In contrast, zero-shot LLMs struggle to leverage EHR representations. This study underlines the potential of text-based approaches in the medical field and highlights areas for further improvement.
PatientDx: Merging Large Language Models for Protecting Data-Privacy in Healthcare
Apr 24, 2025Fine-tuning of Large Language Models (LLMs) has become the default practice for improving model performance on a given task. However, performance improvement comes at the cost of training on vast amounts of annotated data which could be sensitive leading to significant data privacy concerns. In particular, the healthcare domain is one of the most sensitive domains exposed to data privacy issues. In this paper, we present PatientDx, a framework of model merging that allows the design of effective LLMs for health-predictive tasks without requiring fine-tuning nor adaptation on patient data. Our proposal is based on recently proposed techniques known as merging of LLMs and aims to optimize a building block merging strategy. PatientDx uses a pivotal model adapted to numerical reasoning and tunes hyperparameters on examples based on a performance metric but without training of the LLM on these data. Experiments using the mortality tasks of the MIMIC-IV dataset show improvements up to 7% in terms of AUROC when compared to initial models. Additionally, we confirm that when compared to fine-tuned models, our proposal is less prone to data leak problems without hurting performance. Finally, we qualitatively show the capabilities of our proposal through a case study. Our best model is publicly available at https://huggingface.co/ Jgmorenof/mistral\_merged\_0\_4.
Evaluating LLM Abilities to Understand Tabular Electronic Health Records: A Comprehensive Study of Patient Data Extraction and Retrieval
Jan 16, 2025Electronic Health Record (EHR) tables pose unique challenges among which is the presence of hidden contextual dependencies between medical features with a high level of data dimensionality and sparsity. This study presents the first investigation into the abilities of LLMs to comprehend EHRs for patient data extraction and retrieval. We conduct extensive experiments using the MIMICSQL dataset to explore the impact of the prompt structure, instruction, context, and demonstration, of two backbone LLMs, Llama2 and Meditron, based on task performance. Through quantitative and qualitative analyses, our findings show that optimal feature selection and serialization methods can enhance task performance by up to 26.79% compared to naive approaches. Similarly, in-context learning setups with relevant example selection improve data extraction performance by 5.95%. Based on our study findings, we propose guidelines that we believe would help the design of LLM-based models to support health search.
Probing Pretrained Language Models with Hierarchy Properties
Dec 15, 2023Since Pretrained Language Models (PLMs) are the cornerstone of the most recent Information Retrieval (IR) models, the way they encode semantic knowledge is particularly important. However, little attention has been given to studying the PLMs' capability to capture hierarchical semantic knowledge. Traditionally, evaluating such knowledge encoded in PLMs relies on their performance on a task-dependent evaluation approach based on proxy tasks, such as hypernymy detection. Unfortunately, this approach potentially ignores other implicit and complex taxonomic relations. In this work, we propose a task-agnostic evaluation method able to evaluate to what extent PLMs can capture complex taxonomy relations, such as ancestors and siblings. The evaluation is based on intrinsic properties that capture the hierarchical nature of taxonomies. Our experimental evaluation shows that the lexico-semantic knowledge implicitly encoded in PLMs does not always capture hierarchical relations. We further demonstrate that the proposed properties can be injected into PLMs to improve their understanding of hierarchy. Through evaluations on taxonomy reconstruction, hypernym discovery and reading comprehension tasks, we show that the knowledge about hierarchy is moderately but not systematically transferable across tasks.
Yes but.. Can ChatGPT Identify Entities in Historical Documents?
Mar 30, 2023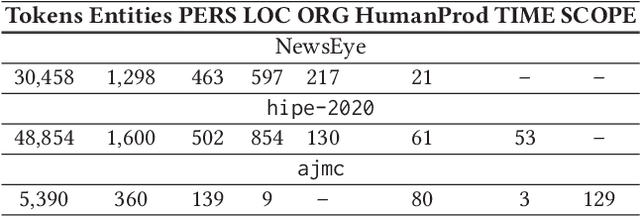


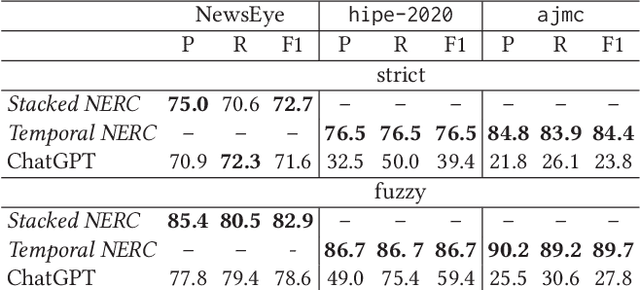
Large language models (LLMs) have been leveraged for several years now, obtaining state-of-the-art performance in recognizing entities from modern documents. For the last few months, the conversational agent ChatGPT has "prompted" a lot of interest in the scientific community and public due to its capacity of generating plausible-sounding answers. In this paper, we explore this ability by probing it in the named entity recognition and classification (NERC) task in primary sources (e.g., historical newspapers and classical commentaries) in a zero-shot manner and by comparing it with state-of-the-art LM-based systems. Our findings indicate several shortcomings in identifying entities in historical text that range from the consistency of entity annotation guidelines, entity complexity, and code-switching, to the specificity of prompting. Moreover, as expected, the inaccessibility of historical archives to the public (and thus on the Internet) also impacts its performance.
Using contextual sentence analysis models to recognize ESG concepts
Jul 04, 2022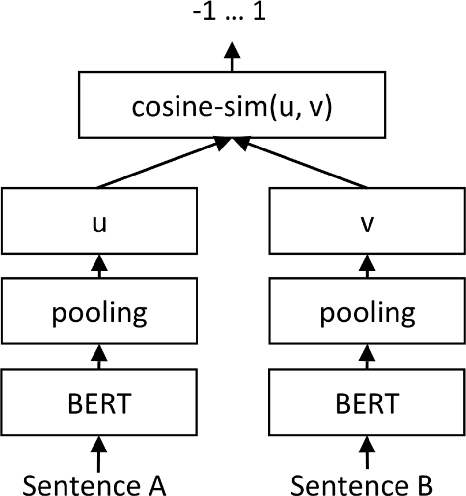


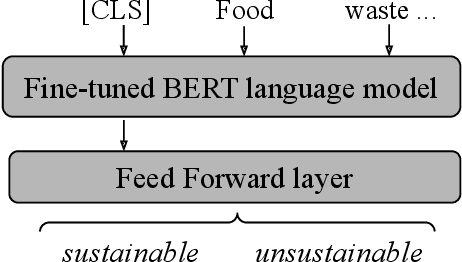
This paper summarizes the joint participation of the Trading Central Labs and the L3i laboratory of the University of La Rochelle on both sub-tasks of the Shared Task FinSim-4 evaluation campaign. The first sub-task aims to enrich the 'Fortia ESG taxonomy' with new lexicon entries while the second one aims to classify sentences to either 'sustainable' or 'unsustainable' with respect to ESG (Environment, Social and Governance) related factors. For the first sub-task, we proposed a model based on pre-trained Sentence-BERT models to project sentences and concepts in a common space in order to better represent ESG concepts. The official task results show that our system yields a significant performance improvement compared to the baseline and outperforms all other submissions on the first sub-task. For the second sub-task, we combine the RoBERTa model with a feed-forward multi-layer perceptron in order to extract the context of sentences and classify them. Our model achieved high accuracy scores (over 92%) and was ranked among the top 5 systems.
Named entity recognition architecture combining contextual and global features
Dec 15, 2021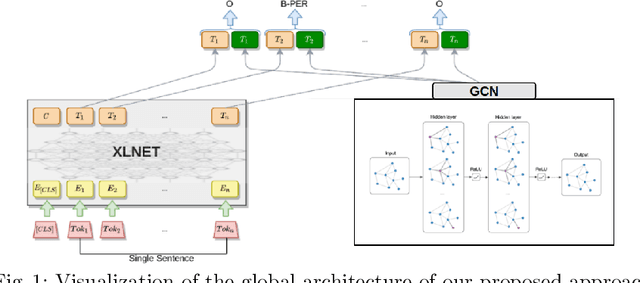
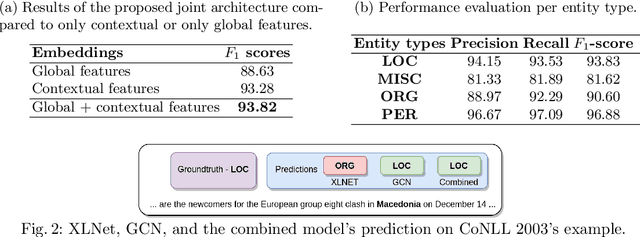
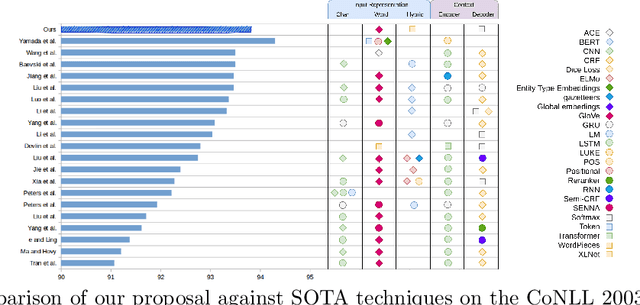
Named entity recognition (NER) is an information extraction technique that aims to locate and classify named entities (e.g., organizations, locations,...) within a document into predefined categories. Correctly identifying these phrases plays a significant role in simplifying information access. However, it remains a difficult task because named entities (NEs) have multiple forms and they are context-dependent. While the context can be represented by contextual features, global relations are often misrepresented by those models. In this paper, we propose the combination of contextual features from XLNet and global features from Graph Convolution Network (GCN) to enhance NER performance. Experiments over a widely-used dataset, CoNLL 2003, show the benefits of our strategy, with results competitive with the state of the art (SOTA).
Event Detection as Question Answering with Entity Information
Apr 14, 2021

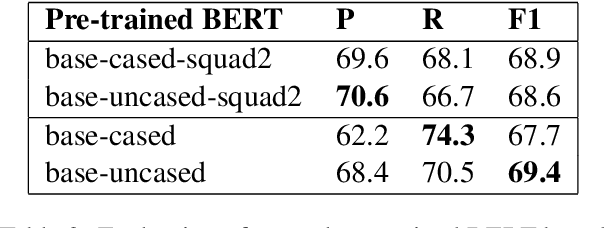

In this paper, we propose a recent and under-researched paradigm for the task of event detection (ED) by casting it as a question-answering (QA) problem with the possibility of multiple answers and the support of entities. The extraction of event triggers is, thus, transformed into the task of identifying answer spans from a context, while also focusing on the surrounding entities. The architecture is based on a pre-trained and fine-tuned language model, where the input context is augmented with entities marked at different levels, their positions, their types, and, finally, the argument roles. Experiments on the ACE~2005 corpus demonstrate that the proposed paradigm is a viable solution for the ED task and it significantly outperforms the state-of-the-art models. Moreover, we prove that our methods are also able to extract unseen event types.