 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIND: Toward Multimodal Financial Reasoning and Question Answering for Indic Languages
May 13, 2026Financial decision-making in multilingual settings demands accurate numerical reasoning grounded in diverse modalities, yet existing benchmarks largely overlook this high-stakes, real-world challenge, especially for Indic languages. We introduce FinVQA, a benchmark for evaluating financial numerical and multimodal reasoning in multilingual Indic contexts. FinVQA spans English, Hindi, Bengali, Marathi, Gujarati, and Tamil, and comprises 18,900 samples across 14 financial domains. The dataset captures diverse reasoning paradigms under realistic constraints, and is structured across three difficulty levels (easy, moderate, hard) and four question formats: multiple choice, fill-in-the-blank, table matching, and true/false. To address these challenges, we propose FIND, a framework that combines supervised fine-tuning with constraint-aware decoding to promote faithful numerical reasoning, robust multimodal grounding, and structured decision-making. Together, FinVQA and FIND establish a rigorous evaluation and modeling paradigm for high-stakes multilingual multimodal financial reasoning.
BhashaSutra: A Task-Centric Unified Survey of Indian NLP Datasets, Corpora, and Resources
Apr 20, 2026India's linguistic landscape, spanning 22 scheduled languages and hundreds of marginalized dialects, has driven rapid growth in NLP datasets, benchmarks, and pretrained models. However, no dedicated survey consolidates resources developed specifically for Indian languages. Existing reviews either focus on a few high-resource languages or subsume Indian languages within broader multilingual settings, limiting coverage of low-resource and culturally diverse varieties. To address this gap, we present the first unified survey of Indian NLP resources, covering 200+ datasets, 50+ benchmarks, and 100+ models, tools, and systems across text, speech, multimodal, and culturally grounded tasks. We organize resources by linguistic phenomena, domains, and modalities; analyze trends in annotation, evaluation, and model design; and identify persistent challenges such as data sparsity, uneven language coverage, script diversity, and limited cultural and domain generalization. This survey offers a consolidated foundation for equitable, culturally grounded, and scalable NLP research in the Indian linguistic ecosystem.
When Meaning Isn't Literal: Exploring Idiomatic Meaning Across Languages and Modalities
Apr 12, 2026Idiomatic reasoning, deeply intertwined with metaphor and culture, remains a blind spot for contemporary language models, whose progress skews toward surface-level lexical and semantic cues. For instance, the Bengali idiom \textit{\foreignlanguage{bengali}{\char"0986\char"0999\char"09CD\char"0997\char"09C1 \char"09B0 \char"09AB\char"09B2 \char"099F\char"0995}} (angur fol tok, ``grapes are sour''): it encodes denial-driven rationalization, yet naive models latch onto the literal fox-and-grape imagery. Addressing this oversight, we present ``Mediom,'' a multilingual, multimodal idiom corpus of 3,533 Hindi, Bengali, and Thai idioms, each paired with gold-standard explanations, cross-lingual translations, and carefully aligned text--image representations. We benchmark both large language models (textual reasoning) and vision-language models (figurative disambiguation) on Mediom, exposing systematic failures in metaphor comprehension. To mitigate these gaps, we propose ``HIDE,'' a Hinting-based Idiom Explanation framework that leverages error-feedback retrieval and targeted diagnostic cues for iterative reasoning refinement. Collectively, Mediom and HIDE establish a rigorous test bed and methodology for culturally grounded, multimodal idiom understanding embedded with reasoning hints in next-generation AI systems.
HARPO: Hierarchical Agentic Reasoning for User-Aligned Conversational Recommendation
Apr 11, 2026Conversational recommender systems (CRSs) operate under incremental preference revelation, requiring systems to make recommendation decisions under uncertainty. While recent approaches particularly those built on large language models achieve strong performance on standard proxy metrics such as Recall@K and BLEU, they often fail to deliver high-quality, user-aligned recommendations in practice. This gap arises because existing methods primarily optimize for intermediate objectives like retrieval accuracy, fluent generation, or tool invocation, rather than recommendation quality itself. We propose HARPO (Hierarchical Agentic Reasoning with Preference Optimization), an agentic framework that reframes conversational recommendation as a structured decision-making process explicitly optimized for multi-dimensional recommendation quality. HARPO integrates hierarchical preference learning that decomposes recommendation quality into interpretable dimensions (relevance, diversity, predicted user satisfaction, and engagement) and learns context-dependent weights over these dimensions; (ii) deliberative tree-search reasoning guided by a learned value network that evaluates candidate reasoning paths based on predicted recommendation quality rather than task completion; and (iii) domain-agnostic reasoning abstractions through Virtual Tool Operations and multi-agent refinement, enabling transferable recommendation reasoning across domains. We evaluate HARPO on ReDial, INSPIRED, and MUSE, demonstrating consistent improvements over strong baselines on recommendation-centric metrics while maintaining competitive response quality. These results highlight the importance of explicit, user-aligned quality optimization for conversational recommendation.
CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
Mar 25, 2026Multimodal agentic pipelines are transforming human-computer interaction by enabling efficient and accessible automation of complex, real-world tasks. However, recent efforts have focused on short-horizon or general-purpose applications (e.g., mobile or desktop interfaces), leaving long-horizon automation for domain-specific systems, particularly in healthcare, largely unexplored. To address this, we introduce CareFlow, a high-quality human-annotated benchmark comprising complex, long-horizon software workflows across medical annotation tools, DICOM viewers, EHR systems, and laboratory information systems. On this benchmark, existing vision-language models (VLMs) perform poorly, struggling with long-horizon reasoning and multi-step interactions in medical contexts. To overcome this, we propose CarePilot, a multi-agent framework based on the actor-critic paradigm. The Actor integrates tool grounding with dual-memory mechanisms (long-term and short-term experience) to predict the next semantic action from the visual interface and system state. The Critic evaluates each action, updates memory based on observed effects, and either executes or provides corrective feedback to refine the workflow. Through iterative agentic simulation, the Actor learns to perform more robust and reasoning-aware predictions during inference. Our experiments show that CarePilot achieves state-of-the-art performance, outperforming strong closed-source and open-source multimodal baselines by approximately 15.26% and 3.38%, respectively, on our benchmark and out-of-distribution dataset.
CURE-Med: Curriculum-Informed Reinforcement Learning for Multilingual Medical Reasoning
Jan 19, 2026While large language models (LLMs) have shown to perform well on monolingual mathematical and commonsense reasoning, they remain unreliable for multilingual medical reasoning applications, hindering their deployment in multilingual healthcare settings. We address this by first introducing CUREMED-BENCH, a high-quality multilingual medical reasoning dataset with open-ended reasoning queries with a single verifiable answer, spanning thirteen languages, including underrepresented languages such as Amharic, Yoruba, and Swahili. Building on this dataset, we propose CURE-MED, a curriculum-informed reinforcement learning framework that integrates code-switching-aware supervised fine-tuning and Group Relative Policy Optimization to jointly improve logical correctness and language stability. Across thirteen languages, our approach consistently outperforms strong baselines and scales effectively, achieving 85.21% language consistency and 54.35% logical correctness at 7B parameters, and 94.96% language consistency and 70.04% logical correctness at 32B parameters. These results support reliable and equitable multilingual medical reasoning in LLMs. The code and dataset are available at https://cure-med.github.io/
CLINIC: Evaluating Multilingual Trustworthiness in Language Models for Healthcare
Dec 12, 2025Integrating language models (LMs) in healthcare systems holds great promise for improving medical workflows and decision-making. However, a critical barrier to their real-world adoption is the lack of reliable evaluation of their trustworthiness, especially in multilingual healthcare settings. Existing LMs are predominantly trained in high-resource languages, making them ill-equipped to handle the complexity and diversity of healthcare queries in mid- and low-resource languages, posing significant challenges for deploying them in global healthcare contexts where linguistic diversity is key. In this work, we present CLINIC, a Comprehensive Multilingual Benchmark to evaluate the trustworthiness of language models in healthcare. CLINIC systematically benchmarks LMs across five key dimensions of trustworthiness: truthfulness, fairness, safety, robustness, and privacy, operationalized through 18 diverse tasks, spanning 15 languages (covering all the major continents), and encompassing a wide array of critical healthcare topics like disease conditions, preventive actions, diagnostic tests, treatments, surgeries, and medications. Our extensive evaluation reveals that LMs struggle with factual correctness, demonstrate bias across demographic and linguistic groups, and are susceptible to privacy breaches and adversarial attacks. By highlighting these shortcomings, CLINIC lays the foundation for enhancing the global reach and safety of LMs in healthcare across diverse languages.
Crossing Borders: A Multimodal Challenge for Indian Poetry Translation and Image Generation
Nov 18, 2025Indian poetry, known for its linguistic complexity and deep cultural resonance, has a rich and varied heritage spanning thousands of years. However, its layered meanings, cultural allusions, and sophisticated grammatical constructions often pose challenges for comprehension, especially for non-native speakers or readers unfamiliar with its context and language. Despite its cultural significance, existing works on poetry have largely overlooked Indian language poems. In this paper, we propose the Translation and Image Generation (TAI) framework, leveraging Large Language Models (LLMs) and Latent Diffusion Models through appropriate prompt tuning. Our framework supports the United Nations Sustainable Development Goals of Quality Education (SDG 4) and Reduced Inequalities (SDG 10) by enhancing the accessibility of culturally rich Indian-language poetry to a global audience. It includes (1) a translation module that uses an Odds Ratio Preference Alignment Algorithm to accurately translate morphologically rich poetry into English, and (2) an image generation module that employs a semantic graph to capture tokens, dependencies, and semantic relationships between metaphors and their meanings, to create visually meaningful representations of Indian poems. Our comprehensive experimental evaluation, including both human and quantitative assessments, demonstrates the superiority of TAI Diffusion in poem image generation tasks, outperforming strong baselines. To further address the scarcity of resources for Indian-language poetry, we introduce the Morphologically Rich Indian Language Poems MorphoVerse Dataset, comprising 1,570 poems across 21 low-resource Indian languages. By addressing the gap in poetry translation and visual comprehension, this work aims to broaden accessibility and enrich the reader's experience.
Talk, Snap, Complain: Validation-Aware Multimodal Expert Framework for Fine-Grained Customer Grievances
Nov 18, 2025Existing approaches to complaint analysis largely rely on unimodal, short-form content such as tweets or product reviews. This work advances the field by leveraging multimodal, multi-turn customer support dialogues, where users often share both textual complaints and visual evidence (e.g., screenshots, product photos) to enable fine-grained classification of complaint aspects and severity. We introduce VALOR, a Validation-Aware Learner with Expert Routing, tailored for this multimodal setting. It employs a multi-expert reasoning setup using large-scale generative models with Chain-of-Thought (CoT) prompting for nuanced decision-making. To ensure coherence between modalities, a semantic alignment score is computed and integrated into the final classification through a meta-fusion strategy. In alignment with the United Nations Sustainable Development Goals (UN SDGs), the proposed framework supports SDG 9 (Industry, Innovation and Infrastructure) by advancing AI-driven tools for robust, scalable, and context-aware service infrastructure. Further, by enabling structured analysis of complaint narratives and visual context, it contributes to SDG 12 (Responsible Consumption and Production) by promoting more responsive product design and improved accountability in consumer services. We evaluate VALOR on a curated multimodal complaint dataset annotated with fine-grained aspect and severity labels, showing that it consistently outperforms baseline models, especially in complex complaint scenarios where information is distributed across text and images. This study underscores the value of multimodal interaction and expert validation in practical complaint understanding systems. Resources related to data and codes are available here: https://github.com/sarmistha-D/VALOR
M3Retrieve: Benchmarking Multimodal Retrieval for Medicine
Oct 08, 2025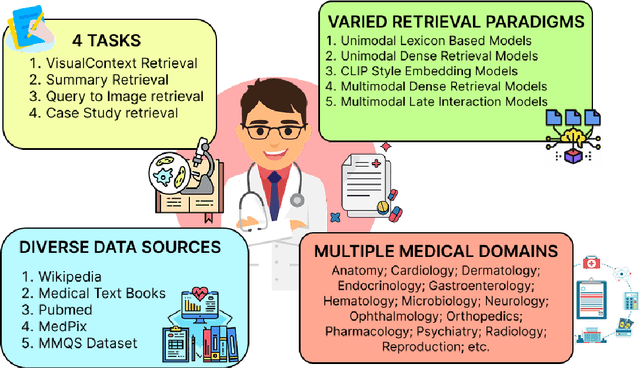
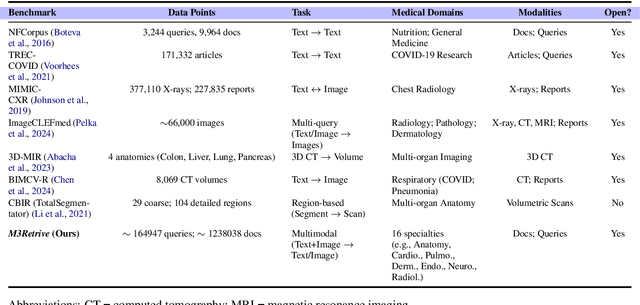

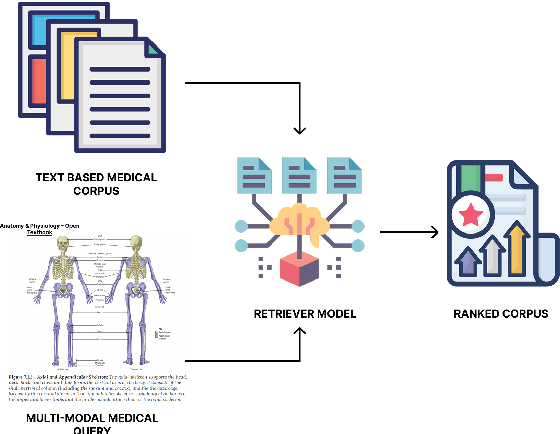
With the increasing use of RetrievalAugmented Generation (RAG), strong retrieval models have become more important than ever. In healthcare, multimodal retrieval models that combine information from both text and images offer major advantages for many downstream tasks such as question answering, cross-modal retrieval, and multimodal summarization, since medical data often includes both formats. However, there is currently no standard benchmark to evaluate how well these models perform in medical settings. To address this gap, we introduce M3Retrieve, a Multimodal Medical Retrieval Benchmark. M3Retrieve, spans 5 domains,16 medical fields, and 4 distinct tasks, with over 1.2 Million text documents and 164K multimodal queries, all collected under approved licenses. We evaluate leading multimodal retrieval models on this benchmark to explore the challenges specific to different medical specialities and to understand their impact on retrieval performance. By releasing M3Retrieve, we aim to enable systematic evaluation, foster model innovation, and accelerate research toward building more capable and reliable multimodal retrieval systems for medical applications. The dataset and the baselines code are available in this github page https://github.com/AkashGhosh/M3Retrieve.