 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDUAL: A Dual-Strategy with Adaptive Loss and Dynamic Aggregation for Mitigating Data Heterogeneity in Federated Learning
Dec 05, 2024



Federated Learning (FL) marks a transformative approach to distributed model training by combining locally optimized models from various clients into a unified global model. While FL preserves data privacy by eliminating centralized storage, it encounters significant challenges such as performance degradation, slower convergence, and reduced robustness of the global model due to the heterogeneity in client data distributions. Among the various forms of data heterogeneity, label skew emerges as a particularly formidable and prevalent issue, especially in domains such as image classification. To address these challenges, we begin with comprehensive experiments to pinpoint the underlying issues in the FL training process. Based on our findings, we then introduce an innovative dual-strategy approach designed to effectively resolve these issues. First, we introduce an adaptive loss function for client-side training, meticulously crafted to preserve previously acquired knowledge while maintaining an optimal equilibrium between local optimization and global model coherence. Secondly, we develop a dynamic aggregation strategy for aggregating client models at the server. This approach adapts to each client's unique learning patterns, effectively addressing the challenges of diverse data across the network. Our comprehensive evaluation, conducted across three diverse real-world datasets, coupled with theoretical convergence guarantees, demonstrates the superior efficacy of our method compared to several established state-of-the-art approaches.
FedMRL: Data Heterogeneity Aware Federated Multi-agent Deep Reinforcement Learning for Medical Imaging
Jul 08, 2024Despite recent advancements in federated learning (FL) for medical image diagnosis, addressing data heterogeneity among clients remains a significant challenge for practical implementation. A primary hurdle in FL arises from the non-IID nature of data samples across clients, which typically results in a decline in the performance of the aggregated global model. In this study, we introduce FedMRL, a novel federated multi-agent deep reinforcement learning framework designed to address data heterogeneity. FedMRL incorporates a novel loss function to facilitate fairness among clients, preventing bias in the final global model. Additionally, it employs a multi-agent reinforcement learning (MARL) approach to calculate the proximal term $(\mu)$ for the personalized local objective function, ensuring convergence to the global optimum. Furthermore, FedMRL integrates an adaptive weight adjustment method using a Self-organizing map (SOM) on the server side to counteract distribution shifts among clients' local data distributions. We assess our approach using two publicly available real-world medical datasets, and the results demonstrate that FedMRL significantly outperforms state-of-the-art techniques, showing its efficacy in addressing data heterogeneity in federated learning. The code can be found here~{\url{https://github.com/Pranabiitp/FedMRL}}.
Enhancing Adverse Drug Event Detection with Multimodal Dataset: Corpus Creation and Model Development
May 27, 2024



The mining of adverse drug events (ADEs) is pivotal in pharmacovigilance, enhancing patient safety by identifying potential risks associated with medications, facilitating early detection of adverse events, and guiding regulatory decision-making. Traditional ADE detection methods are reliable but slow, not easily adaptable to large-scale operations, and offer limited information. With the exponential increase in data sources like social media content, biomedical literature, and Electronic Medical Records (EMR), extracting relevant ADE-related information from these unstructured texts is imperative. Previous ADE mining studies have focused on text-based methodologies, overlooking visual cues, limiting contextual comprehension, and hindering accurate interpretation. To address this gap, we present a MultiModal Adverse Drug Event (MMADE) detection dataset, merging ADE-related textual information with visual aids. Additionally, we introduce a framework that leverages the capabilities of LLMs and VLMs for ADE detection by generating detailed descriptions of medical images depicting ADEs, aiding healthcare professionals in visually identifying adverse events. Using our MMADE dataset, we showcase the significance of integrating visual cues from images to enhance overall performance. This approach holds promise for patient safety, ADE awareness, and healthcare accessibility, paving the way for further exploration in personalized healthcare.
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Feb 05, 2024


Prompt engineering has emerged as an indispensable technique for extending the capabilities of large language models (LLMs) and vision-language models (VLMs). This approach leverages task-specific instructions, known as prompts, to enhance model efficacy without modifying the core model parameters. Rather than updating the model parameters, prompts allow seamless integration of pre-trained models into downstream tasks by eliciting desired model behaviors solely based on the given prompt. Prompts can be natural language instructions that provide context to guide the model or learned vector representations that activate relevant knowledge. This burgeoning field has enabled success across various applications, from question-answering to commonsense reasoning. However, there remains a lack of systematic organization and understanding of the diverse prompt engineering methods and techniques. This survey paper addresses the gap by providing a structured overview of recent advancements in prompt engineering, categorized by application area. For each prompting approach, we provide a summary detailing the prompting methodology, its applications, the models involved, and the datasets utilized. We also delve into the strengths and limitations of each approach and include a taxonomy diagram and table summarizing datasets, models, and critical points of each prompting technique. This systematic analysis enables a better understanding of this rapidly developing field and facilitates future research by illuminating open challenges and opportunities for prompt engineering.
CRDT: Correlation Ratio Based Decision Tree Model for Healthcare Data Mining
Sep 24, 2015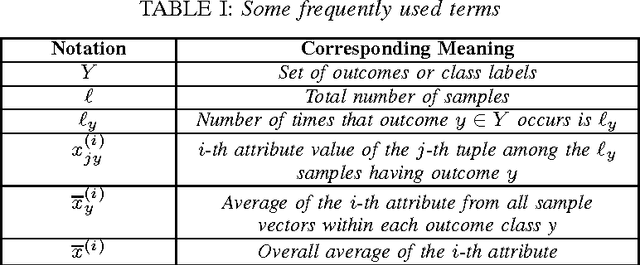


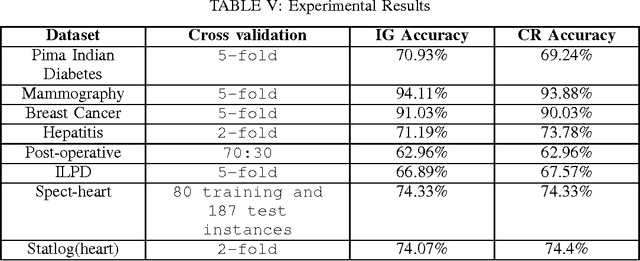
The phenomenal growth in the healthcare data has inspired us in investigating robust and scalable models for data mining. For classification problems Information Gain(IG) based Decision Tree is one of the popular choices. However, depending upon the nature of the dataset, IG based Decision Tree may not always perform well as it prefers the attribute with more number of distinct values as the splitting attribute. Healthcare datasets generally have many attributes and each attribute generally has many distinct values. In this paper, we have tried to focus on this characteristics of the datasets while analysing the performance of our proposed approach which is a variant of Decision Tree model and uses the concept of Correlation Ratio(CR). Unlike IG based approach, this CR based approach has no biasness towards the attribute with more number of distinct values. We have applied our model on some benchmark healthcare datasets to show the effectiveness of the proposed technique.