 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemeGuard: An LLM and VLM-based Framework for Advancing Content Moderation via Meme Intervention
Jun 08, 2024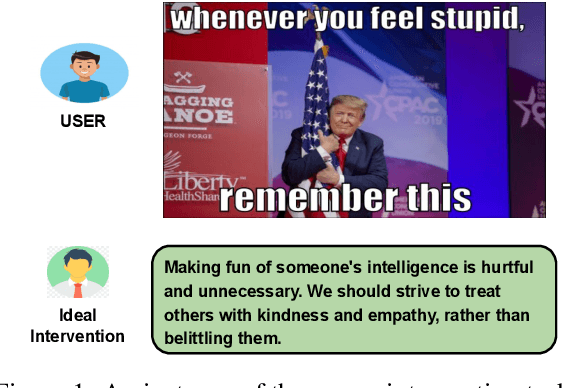
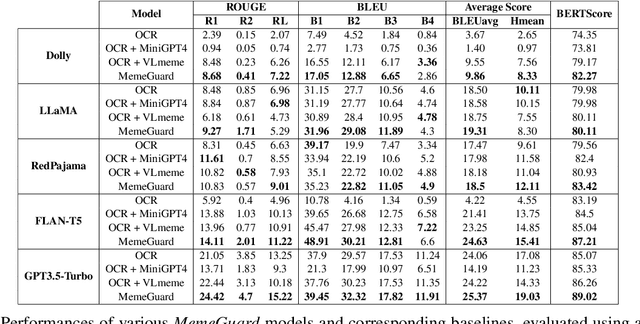
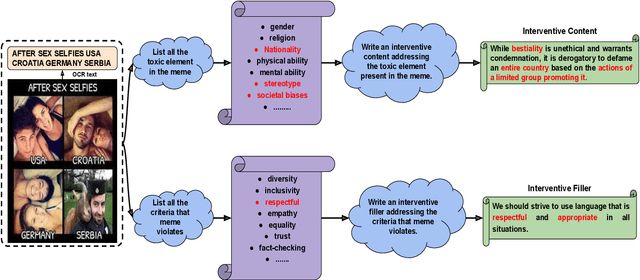

In the digital world, memes present a unique challenge for content moderation due to their potential to spread harmful content. Although detection methods have improved, proactive solutions such as intervention are still limited, with current research focusing mostly on text-based content, neglecting the widespread influence of multimodal content like memes. Addressing this gap, we present \textit{MemeGuard}, a comprehensive framework leveraging Large Language Models (LLMs) and Visual Language Models (VLMs) for meme intervention. \textit{MemeGuard} harnesses a specially fine-tuned VLM, \textit{VLMeme}, for meme interpretation, and a multimodal knowledge selection and ranking mechanism (\textit{MKS}) for distilling relevant knowledge. This knowledge is then employed by a general-purpose LLM to generate contextually appropriate interventions. Another key contribution of this work is the \textit{\textbf{I}ntervening} \textit{\textbf{C}yberbullying in \textbf{M}ultimodal \textbf{M}emes (ICMM)} dataset, a high-quality, labeled dataset featuring toxic memes and their corresponding human-annotated interventions. We leverage \textit{ICMM} to test \textit{MemeGuard}, demonstrating its proficiency in generating relevant and effective responses to toxic memes.
Meme-ingful Analysis: Enhanced Understanding of Cyberbullying in Memes Through Multimodal Explanations
Jan 18, 2024
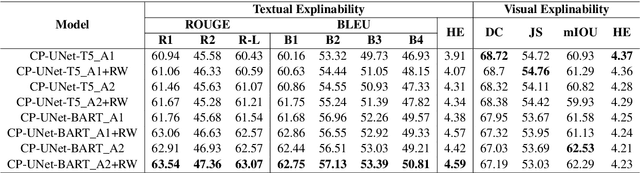
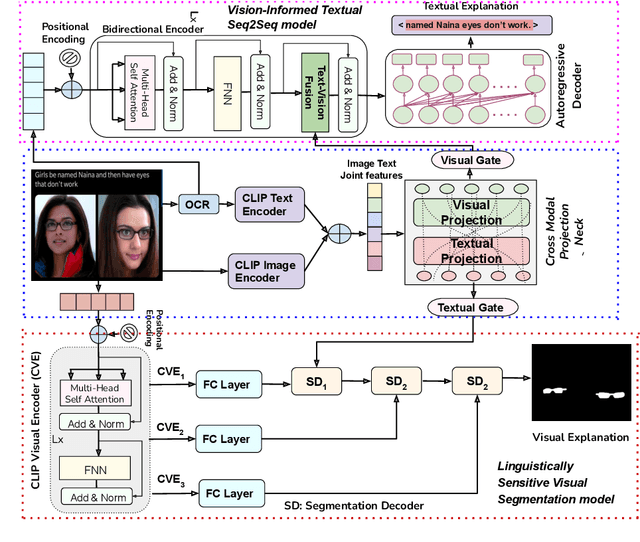
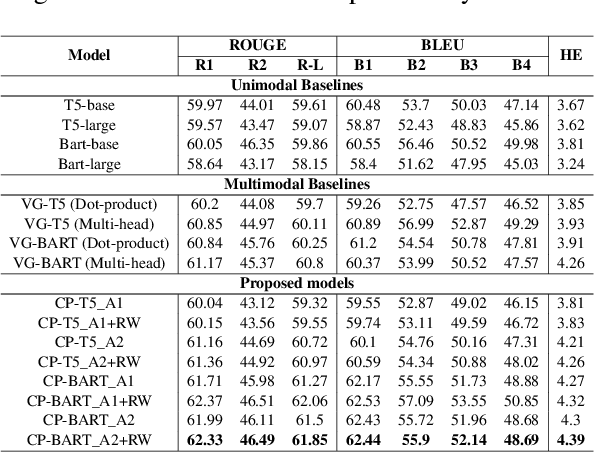
Internet memes have gained significant influence in communicating political, psychological, and sociocultural ideas. While memes are often humorous, there has been a rise in the use of memes for trolling and cyberbullying. Although a wide variety of effective deep learning-based models have been developed for detecting offensive multimodal memes, only a few works have been done on explainability aspect. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than only focusing on performance. Motivated by this, we introduce {\em MultiBully-Ex}, the first benchmark dataset for multimodal explanation from code-mixed cyberbullying memes. Here, both visual and textual modalities are highlighted to explain why a given meme is cyberbullying. A Contrastive Language-Image Pretraining (CLIP) projection-based multimodal shared-private multitask approach has been proposed for visual and textual explanation of a meme. Experimental results demonstrate that training with multimodal explanations improves performance in generating textual justifications and more accurately identifying the visual evidence supporting a decision with reliable performance improvements.
Explain Thyself Bully: Sentiment Aided Cyberbullying Detection with Explanation
Jan 17, 2024Cyberbullying has become a big issue with the popularity of different social media networks and online communication apps. While plenty of research is going on to develop better models for cyberbullying detection in monolingual language, there is very little research on the code-mixed languages and explainability aspect of cyberbullying. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than focusing on performance. Motivated by this we develop the first interpretable multi-task model called {\em mExCB} for automatic cyberbullying detection from code-mixed languages which can simultaneously solve several tasks, cyberbullying detection, explanation/rationale identification, target group detection and sentiment analysis. We have introduced {\em BullyExplain}, the first benchmark dataset for explainable cyberbullying detection in code-mixed language. Each post in {\em BullyExplain} dataset is annotated with four labels, i.e., {\em bully label, sentiment label, target and rationales (explainability)}, i.e., which phrases are being responsible for annotating the post as a bully. The proposed multitask framework (mExCB) based on CNN and GRU with word and sub-sentence (SS) level attention is able to outperform several baselines and state of the art models when applied on {\em BullyExplain} dataset.
An EcoSage Assistant: Towards Building A Multimodal Plant Care Dialogue Assistant
Jan 10, 2024In recent times, there has been an increasing awareness about imminent environmental challenges, resulting in people showing a stronger dedication to taking care of the environment and nurturing green life. The current $19.6 billion indoor gardening industry, reflective of this growing sentiment, not only signifies a monetary value but also speaks of a profound human desire to reconnect with the natural world. However, several recent surveys cast a revealing light on the fate of plants within our care, with more than half succumbing primarily due to the silent menace of improper care. Thus, the need for accessible expertise capable of assisting and guiding individuals through the intricacies of plant care has become paramount more than ever. In this work, we make the very first attempt at building a plant care assistant, which aims to assist people with plant(-ing) concerns through conversations. We propose a plant care conversational dataset named Plantational, which contains around 1K dialogues between users and plant care experts. Our end-to-end proposed approach is two-fold : (i) We first benchmark the dataset with the help of various large language models (LLMs) and visual language model (VLM) by studying the impact of instruction tuning (zero-shot and few-shot prompting) and fine-tuning techniques on this task; (ii) finally, we build EcoSage, a multi-modal plant care assisting dialogue generation framework, incorporating an adapter-based modality infusion using a gated mechanism. We performed an extensive examination (both automated and manual evaluation) of the performance exhibited by various LLMs and VLM in the generation of the domain-specific dialogue responses to underscore the respective strengths and weaknesses of these diverse models.
MedSumm: A Multimodal Approach to Summarizing Code-Mixed Hindi-English Clinical Queries
Jan 03, 2024In the healthcare domain, summarizing medical questions posed by patients is critical for improving doctor-patient interactions and medical decision-making. Although medical data has grown in complexity and quantity, the current body of research in this domain has primarily concentrated on text-based methods, overlooking the integration of visual cues. Also prior works in the area of medical question summarisation have been limited to the English language. This work introduces the task of multimodal medical question summarization for codemixed input in a low-resource setting. To address this gap, we introduce the Multimodal Medical Codemixed Question Summarization MMCQS dataset, which combines Hindi-English codemixed medical queries with visual aids. This integration enriches the representation of a patient's medical condition, providing a more comprehensive perspective. We also propose a framework named MedSumm that leverages the power of LLMs and VLMs for this task. By utilizing our MMCQS dataset, we demonstrate the value of integrating visual information from images to improve the creation of medically detailed summaries. This multimodal strategy not only improves healthcare decision-making but also promotes a deeper comprehension of patient queries, paving the way for future exploration in personalized and responsive medical care. Our dataset, code, and pre-trained models will be made publicly available.