 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxVidLLM: A Multimodal LLM-based Framework for Toxicity Detection in Code-Mixed Videos
May 31, 2024In an era of rapidly evolving internet technology, the surge in multimodal content, including videos, has expanded the horizons of online communication. However, the detection of toxic content in this diverse landscape, particularly in low-resource code-mixed languages, remains a critical challenge. While substantial research has addressed toxic content detection in textual data, the realm of video content, especially in non-English languages, has been relatively underexplored. This paper addresses this research gap by introducing a benchmark dataset, the first of its kind, consisting of 931 videos with 4021 code-mixed Hindi-English utterances collected from YouTube. Each utterance within this dataset has been meticulously annotated for toxicity, severity, and sentiment labels. We have developed an advanced Multimodal Multitask framework built for Toxicity detection in Video Content by leveraging Large Language Models (LLMs), crafted for the primary objective along with the additional tasks of conducting sentiment and severity analysis. ToxVidLLM incorporates three key modules the Encoder module, Cross-Modal Synchronization module, and Multitask module crafting a generic multimodal LLM customized for intricate video classification tasks. Our experiments reveal that incorporating multiple modalities from the videos substantially enhances the performance of toxic content detection by achieving an Accuracy and Weighted F1 score of 94.29% and 94.35%, respectively.
Meme-ingful Analysis: Enhanced Understanding of Cyberbullying in Memes Through Multimodal Explanations
Jan 18, 2024
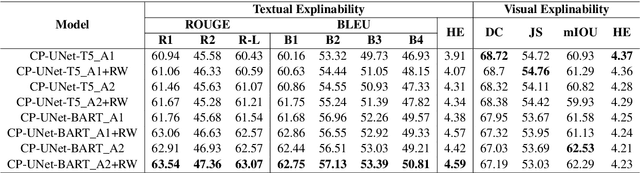
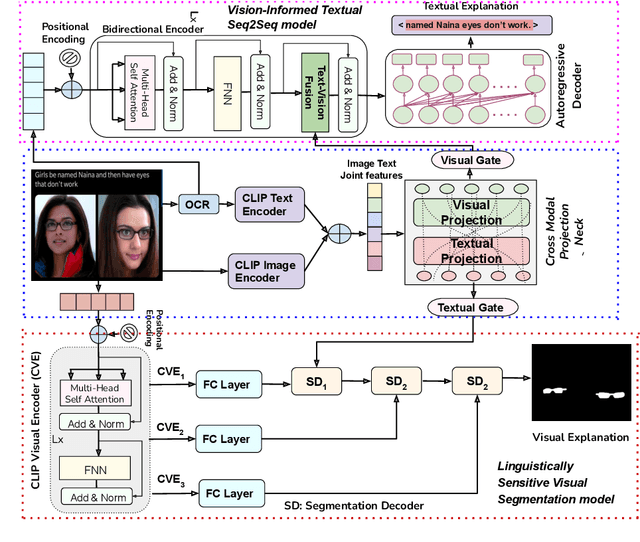
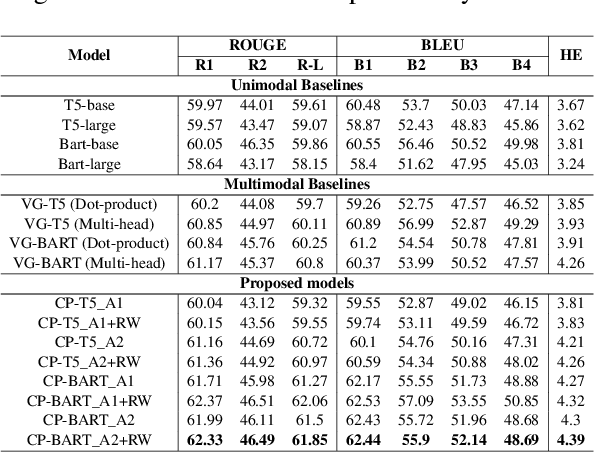
Internet memes have gained significant influence in communicating political, psychological, and sociocultural ideas. While memes are often humorous, there has been a rise in the use of memes for trolling and cyberbullying. Although a wide variety of effective deep learning-based models have been developed for detecting offensive multimodal memes, only a few works have been done on explainability aspect. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than only focusing on performance. Motivated by this, we introduce {\em MultiBully-Ex}, the first benchmark dataset for multimodal explanation from code-mixed cyberbullying memes. Here, both visual and textual modalities are highlighted to explain why a given meme is cyberbullying. A Contrastive Language-Image Pretraining (CLIP) projection-based multimodal shared-private multitask approach has been proposed for visual and textual explanation of a meme. Experimental results demonstrate that training with multimodal explanations improves performance in generating textual justifications and more accurately identifying the visual evidence supporting a decision with reliable performance improvements.
Explain Thyself Bully: Sentiment Aided Cyberbullying Detection with Explanation
Jan 17, 2024Cyberbullying has become a big issue with the popularity of different social media networks and online communication apps. While plenty of research is going on to develop better models for cyberbullying detection in monolingual language, there is very little research on the code-mixed languages and explainability aspect of cyberbullying. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than focusing on performance. Motivated by this we develop the first interpretable multi-task model called {\em mExCB} for automatic cyberbullying detection from code-mixed languages which can simultaneously solve several tasks, cyberbullying detection, explanation/rationale identification, target group detection and sentiment analysis. We have introduced {\em BullyExplain}, the first benchmark dataset for explainable cyberbullying detection in code-mixed language. Each post in {\em BullyExplain} dataset is annotated with four labels, i.e., {\em bully label, sentiment label, target and rationales (explainability)}, i.e., which phrases are being responsible for annotating the post as a bully. The proposed multitask framework (mExCB) based on CNN and GRU with word and sub-sentence (SS) level attention is able to outperform several baselines and state of the art models when applied on {\em BullyExplain} dataset.
Fault Matters: Sensor Data Fusion for Detection of Faults using Dempster-Shafer Theory of Evidence in IoT-Based Applications
Jun 24, 2019
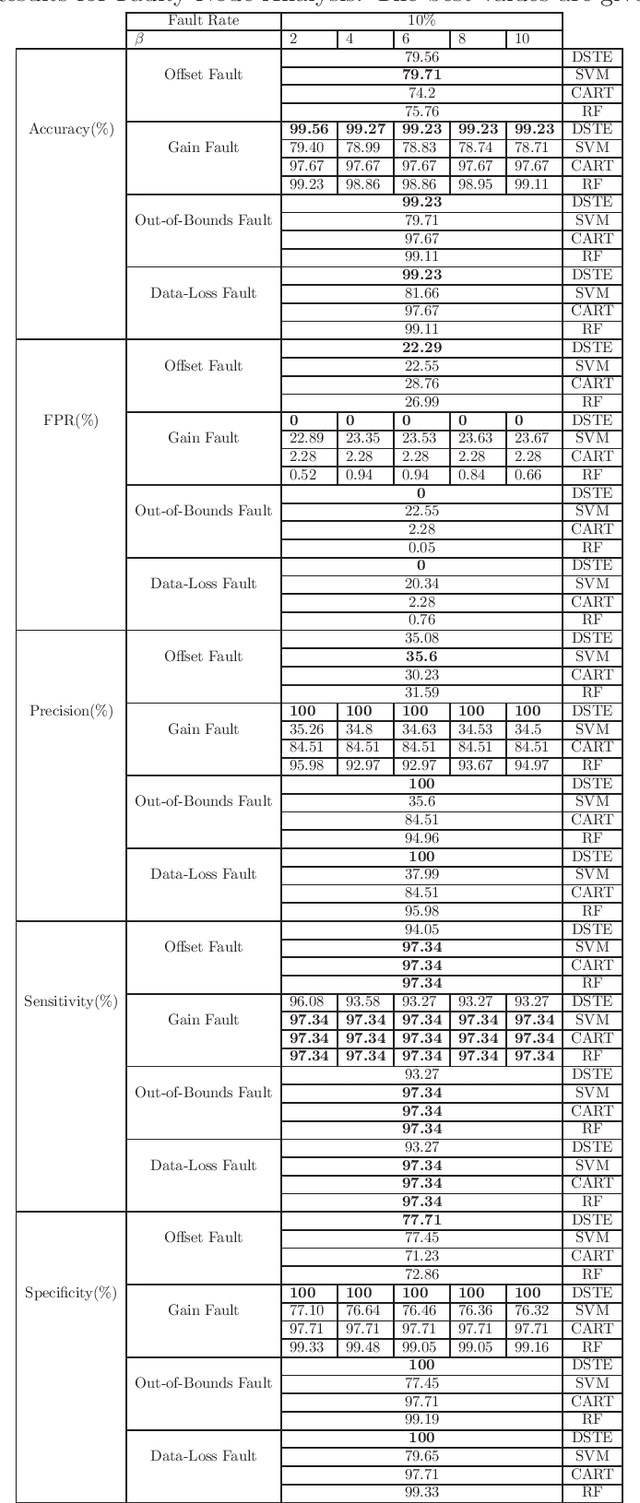
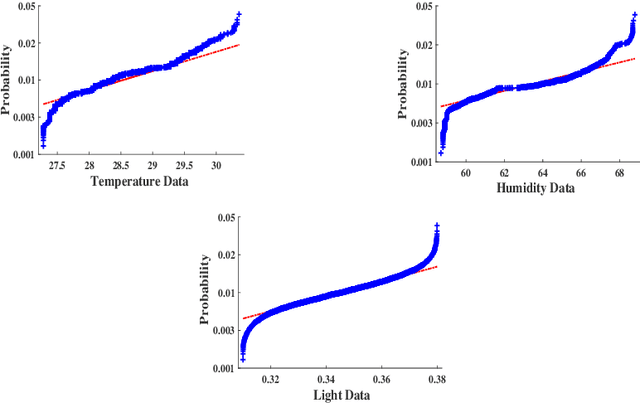

Fault detection in sensor nodes is a pertinent issue that has been an important area of research for a very long time. But it is not explored much as yet in the context of Internet of Things. Internet of Things work with a massive amount of data so the responsibility for guaranteeing the accuracy of the data also lies with it. Moreover, a lot of important and critical decisions are made based on these data, so ensuring its correctness and accuracy is also very important. Also, the detection needs to be as precise as possible to avoid negative alerts. For this purpose, this work has adopted Dempster-Shafer Theory of Evidence which is a popular learning method to collate the information from sensors to come up with a decision regarding the faulty status of a sensor node. To verify the validity of the proposed method, simulations have been performed on a benchmark data set and data collected through a test bed in a laboratory set-up. For the different types of faults, the proposed method shows very competent accuracy for both the benchmark (99.8%) and laboratory data sets (99.9%) when compared to the other state-of-the-art machine learning techniques.