 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Magnetic Materials Discovery -- A structure-based machine learning approach for magnetic ordering and magnetic moment prediction
Jul 02, 2025Accurately predicting magnetic behavior across diverse materials systems remains a longstanding challenge due to the complex interplay of structural and electronic factors and is pivotal for the accelerated discovery and design of next-generation magnetic materials. In this work, a refined descriptor is proposed that significantly improves the prediction of two critical magnetic properties -- magnetic ordering (Ferromagnetic vs. Ferrimagnetic) and magnetic moment per atom -- using only the structural information of materials. Unlike previous models limited to Mn-based or lanthanide-transition metal compounds, the present approach generalizes across a diverse dataset of 5741 stable, binary and ternary, ferromagnetic and ferrimagnetic compounds sourced from the Materials Project. Leveraging an enriched elemental vector representation and advanced feature engineering, including nonlinear terms and reduced matrix sparsity, the LightGBM-based model achieves an accuracy of 82.4% for magnetic ordering classification and balanced recall across FM and FiM classes, addressing a key limitation in prior studies. The model predicts magnetic moment per atom with a correlation coefficient of 0.93, surpassing the Hund's matrix and orbital field matrix descriptors. Additionally, it accurately estimates formation energy per atom, enabling assessment of both magnetic behavior and material stability. This generalized and computationally efficient framework offers a robust tool for high-throughput screening of magnetic materials with tailored properties.
Meme-ingful Analysis: Enhanced Understanding of Cyberbullying in Memes Through Multimodal Explanations
Jan 18, 2024
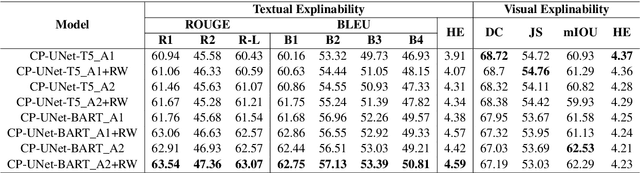
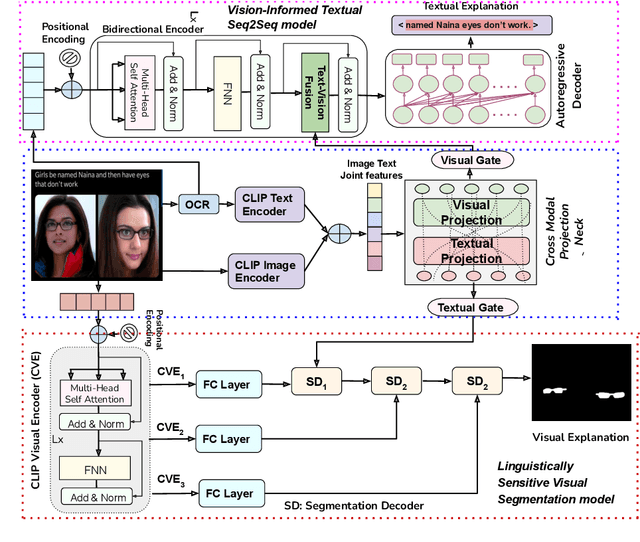
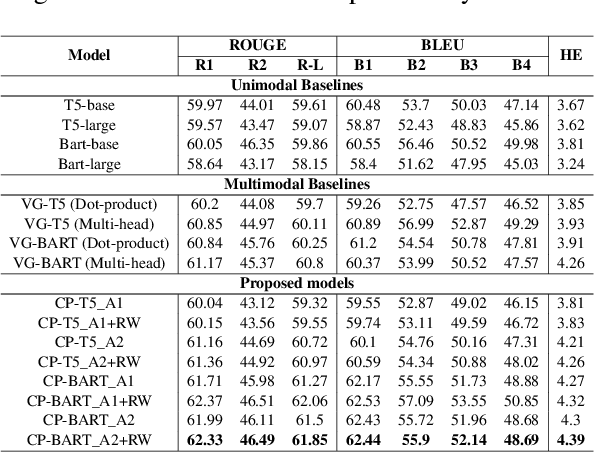
Internet memes have gained significant influence in communicating political, psychological, and sociocultural ideas. While memes are often humorous, there has been a rise in the use of memes for trolling and cyberbullying. Although a wide variety of effective deep learning-based models have been developed for detecting offensive multimodal memes, only a few works have been done on explainability aspect. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than only focusing on performance. Motivated by this, we introduce {\em MultiBully-Ex}, the first benchmark dataset for multimodal explanation from code-mixed cyberbullying memes. Here, both visual and textual modalities are highlighted to explain why a given meme is cyberbullying. A Contrastive Language-Image Pretraining (CLIP) projection-based multimodal shared-private multitask approach has been proposed for visual and textual explanation of a meme. Experimental results demonstrate that training with multimodal explanations improves performance in generating textual justifications and more accurately identifying the visual evidence supporting a decision with reliable performance improvements.