 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemeGuard: An LLM and VLM-based Framework for Advancing Content Moderation via Meme Intervention
Jun 08, 2024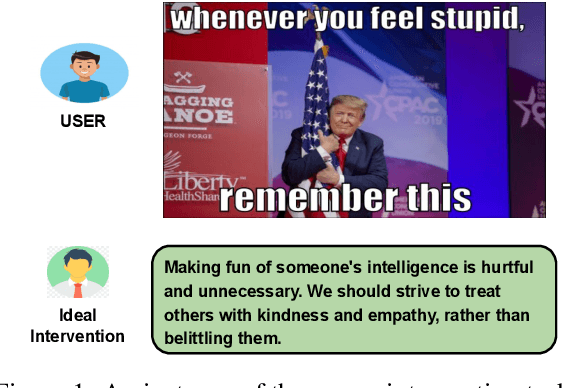
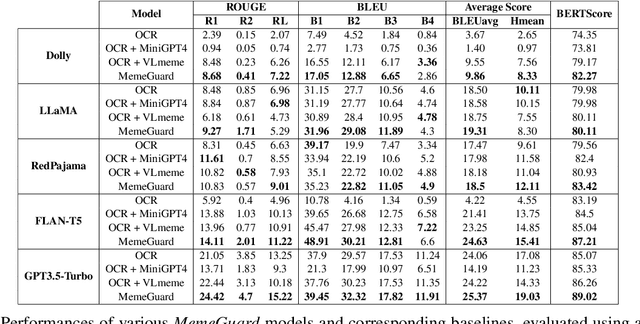
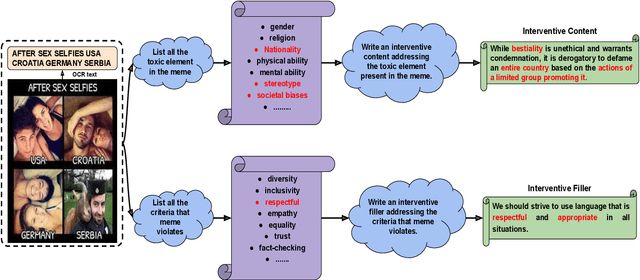

In the digital world, memes present a unique challenge for content moderation due to their potential to spread harmful content. Although detection methods have improved, proactive solutions such as intervention are still limited, with current research focusing mostly on text-based content, neglecting the widespread influence of multimodal content like memes. Addressing this gap, we present \textit{MemeGuard}, a comprehensive framework leveraging Large Language Models (LLMs) and Visual Language Models (VLMs) for meme intervention. \textit{MemeGuard} harnesses a specially fine-tuned VLM, \textit{VLMeme}, for meme interpretation, and a multimodal knowledge selection and ranking mechanism (\textit{MKS}) for distilling relevant knowledge. This knowledge is then employed by a general-purpose LLM to generate contextually appropriate interventions. Another key contribution of this work is the \textit{\textbf{I}ntervening} \textit{\textbf{C}yberbullying in \textbf{M}ultimodal \textbf{M}emes (ICMM)} dataset, a high-quality, labeled dataset featuring toxic memes and their corresponding human-annotated interventions. We leverage \textit{ICMM} to test \textit{MemeGuard}, demonstrating its proficiency in generating relevant and effective responses to toxic memes.
Knowing Your Nonlinearities: Shapley Interactions Reveal the Underlying Structure of Data
Mar 19, 2024Measuring nonlinear feature interaction is an established approach to understanding complex patterns of attribution in many models. In this paper, we use Shapley Taylor interaction indices (STII) to analyze the impact of underlying data structure on model representations in a variety of modalities, tasks, and architectures. Considering linguistic structure in masked and auto-regressive language models (MLMs and ALMs), we find that STII increases within idiomatic expressions and that MLMs scale STII with syntactic distance, relying more on syntax in their nonlinear structure than ALMs do. Our speech model findings reflect the phonetic principal that the openness of the oral cavity determines how much a phoneme varies based on its context. Finally, we study image classifiers and illustrate that feature interactions intuitively reflect object boundaries. Our wide range of results illustrates the benefits of interdisciplinary work and domain expertise in interpretability research.
ConspEmoLLM: Conspiracy Theory Detection Using an Emotion-Based Large Language Model
Mar 11, 2024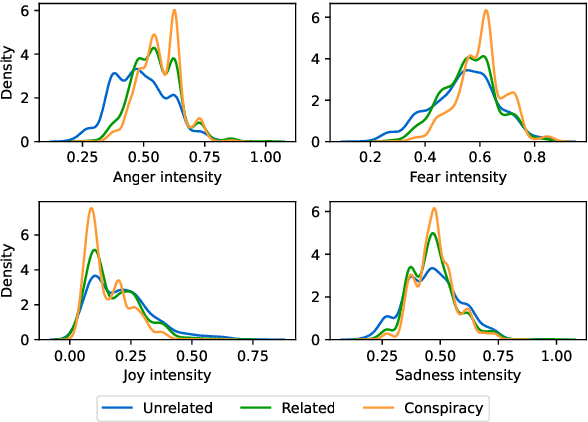
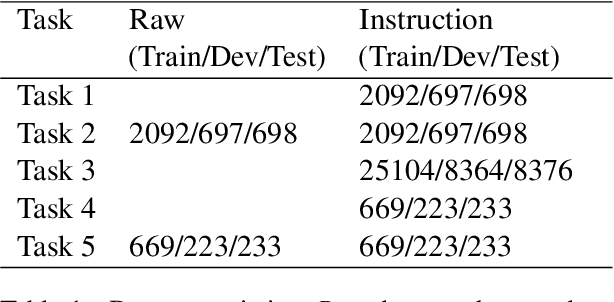

The internet has brought both benefits and harms to society. A prime example of the latter is misinformation, including conspiracy theories, which flood the web. Recent advances in natural language processing, particularly the emergence of large language models (LLMs), have improved the prospects of accurate misinformation detection. However, most LLM-based approaches to conspiracy theory detection focus only on binary classification and fail to account for the important relationship between misinformation and affective features (i.e., sentiment and emotions). Driven by a comprehensive analysis of conspiracy text that reveals its distinctive affective features, we propose ConspEmoLLM, the first open-source LLM that integrates affective information and is able to perform diverse tasks relating to conspiracy theories. These tasks include not only conspiracy theory detection, but also classification of theory type and detection of related discussion (e.g., opinions towards theories). ConspEmoLLM is fine-tuned based on an emotion-oriented LLM using our novel ConDID dataset, which includes five tasks to support LLM instruction tuning and evaluation. We demonstrate that when applied to these tasks, ConspEmoLLM largely outperforms several open-source general domain LLMs and ChatGPT, as well as an LLM that has been fine-tuned using ConDID, but which does not use affective features. This project will be released on https://github.com/lzw108/ConspEmoLLM/.
Meme-ingful Analysis: Enhanced Understanding of Cyberbullying in Memes Through Multimodal Explanations
Jan 18, 2024
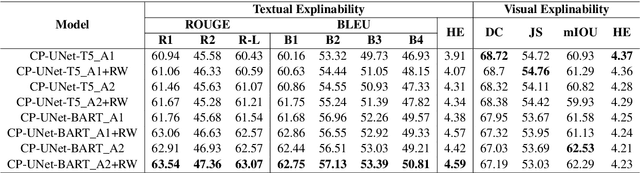
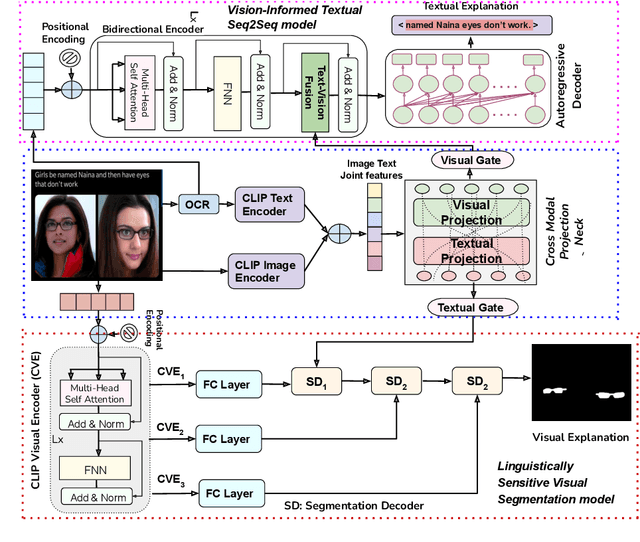
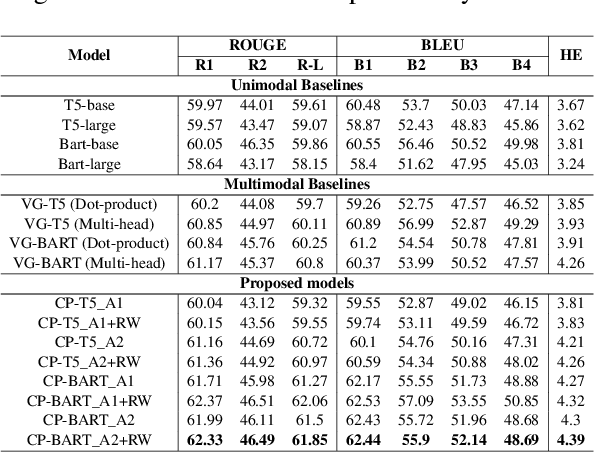
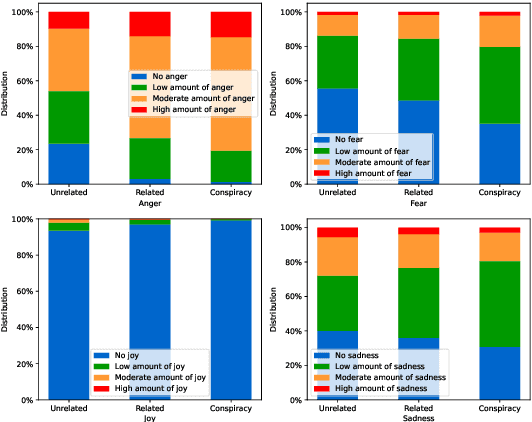
Internet memes have gained significant influence in communicating political, psychological, and sociocultural ideas. While memes are often humorous, there has been a rise in the use of memes for trolling and cyberbullying. Although a wide variety of effective deep learning-based models have been developed for detecting offensive multimodal memes, only a few works have been done on explainability aspect. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than only focusing on performance. Motivated by this, we introduce {\em MultiBully-Ex}, the first benchmark dataset for multimodal explanation from code-mixed cyberbullying memes. Here, both visual and textual modalities are highlighted to explain why a given meme is cyberbullying. A Contrastive Language-Image Pretraining (CLIP) projection-based multimodal shared-private multitask approach has been proposed for visual and textual explanation of a meme. Experimental results demonstrate that training with multimodal explanations improves performance in generating textual justifications and more accurately identifying the visual evidence supporting a decision with reliable performance improvements.
Explain Thyself Bully: Sentiment Aided Cyberbullying Detection with Explanation
Jan 17, 2024Cyberbullying has become a big issue with the popularity of different social media networks and online communication apps. While plenty of research is going on to develop better models for cyberbullying detection in monolingual language, there is very little research on the code-mixed languages and explainability aspect of cyberbullying. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than focusing on performance. Motivated by this we develop the first interpretable multi-task model called {\em mExCB} for automatic cyberbullying detection from code-mixed languages which can simultaneously solve several tasks, cyberbullying detection, explanation/rationale identification, target group detection and sentiment analysis. We have introduced {\em BullyExplain}, the first benchmark dataset for explainable cyberbullying detection in code-mixed language. Each post in {\em BullyExplain} dataset is annotated with four labels, i.e., {\em bully label, sentiment label, target and rationales (explainability)}, i.e., which phrases are being responsible for annotating the post as a bully. The proposed multitask framework (mExCB) based on CNN and GRU with word and sub-sentence (SS) level attention is able to outperform several baselines and state of the art models when applied on {\em BullyExplain} dataset.
MedSumm: A Multimodal Approach to Summarizing Code-Mixed Hindi-English Clinical Queries
Jan 03, 2024In the healthcare domain, summarizing medical questions posed by patients is critical for improving doctor-patient interactions and medical decision-making. Although medical data has grown in complexity and quantity, the current body of research in this domain has primarily concentrated on text-based methods, overlooking the integration of visual cues. Also prior works in the area of medical question summarisation have been limited to the English language. This work introduces the task of multimodal medical question summarization for codemixed input in a low-resource setting. To address this gap, we introduce the Multimodal Medical Codemixed Question Summarization MMCQS dataset, which combines Hindi-English codemixed medical queries with visual aids. This integration enriches the representation of a patient's medical condition, providing a more comprehensive perspective. We also propose a framework named MedSumm that leverages the power of LLMs and VLMs for this task. By utilizing our MMCQS dataset, we demonstrate the value of integrating visual information from images to improve the creation of medically detailed summaries. This multimodal strategy not only improves healthcare decision-making but also promotes a deeper comprehension of patient queries, paving the way for future exploration in personalized and responsive medical care. Our dataset, code, and pre-trained models will be made publicly available.
CLIPSyntel: CLIP and LLM Synergy for Multimodal Question Summarization in Healthcare
Dec 16, 2023
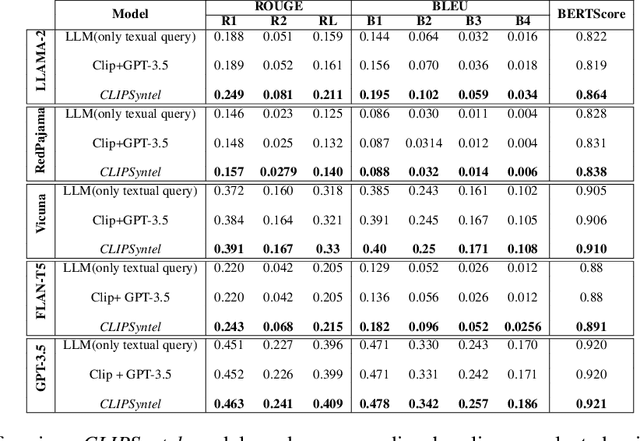
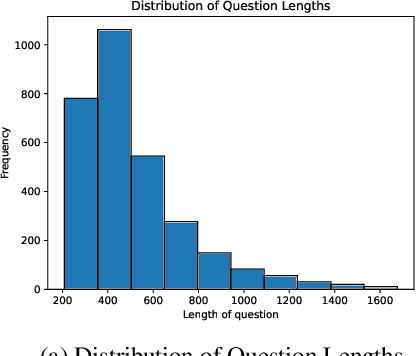

In the era of modern healthcare, swiftly generating medical question summaries is crucial for informed and timely patient care. Despite the increasing complexity and volume of medical data, existing studies have focused solely on text-based summarization, neglecting the integration of visual information. Recognizing the untapped potential of combining textual queries with visual representations of medical conditions, we introduce the Multimodal Medical Question Summarization (MMQS) Dataset. This dataset, a major contribution to our work, pairs medical queries with visual aids, facilitating a richer and more nuanced understanding of patient needs. We also propose a framework, utilizing the power of Contrastive Language Image Pretraining(CLIP) and Large Language Models(LLMs), consisting of four modules that identify medical disorders, generate relevant context, filter medical concepts, and craft visually aware summaries. Our comprehensive framework harnesses the power of CLIP, a multimodal foundation model, and various general-purpose LLMs, comprising four main modules: the medical disorder identification module, the relevant context generation module, the context filtration module for distilling relevant medical concepts and knowledge, and finally, a general-purpose LLM to generate visually aware medical question summaries. Leveraging our MMQS dataset, we showcase how visual cues from images enhance the generation of medically nuanced summaries. This multimodal approach not only enhances the decision-making process in healthcare but also fosters a more nuanced understanding of patient queries, laying the groundwork for future research in personalized and responsive medical care
Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence
Jun 12, 2023Better understanding of Large Language Models' (LLMs) legal analysis abilities can contribute to improving the efficiency of legal services, governing artificial intelligence, and leveraging LLMs to identify inconsistencies in law. This paper explores LLM capabilities in applying tax law. We choose this area of law because it has a structure that allows us to set up automated validation pipelines across thousands of examples, requires logical reasoning and maths skills, and enables us to test LLM capabilities in a manner relevant to real-world economic lives of citizens and companies. Our experiments demonstrate emerging legal understanding capabilities, with improved performance in each subsequent OpenAI model release. We experiment with retrieving and utilising the relevant legal authority to assess the impact of providing additional legal context to LLMs. Few-shot prompting, presenting examples of question-answer pairs, is also found to significantly enhance the performance of the most advanced model, GPT-4. The findings indicate that LLMs, particularly when combined with prompting enhancements and the correct legal texts, can perform at high levels of accuracy but not yet at expert tax lawyer levels. As LLMs continue to advance, their ability to reason about law autonomously could have significant implications for the legal profession and AI governance.
A Survey on Medical Document Summarization
Dec 03, 2022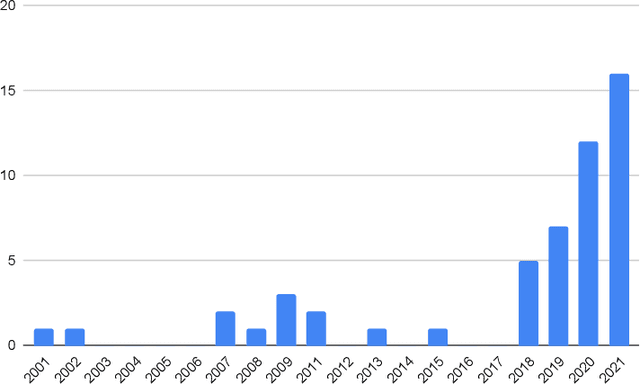
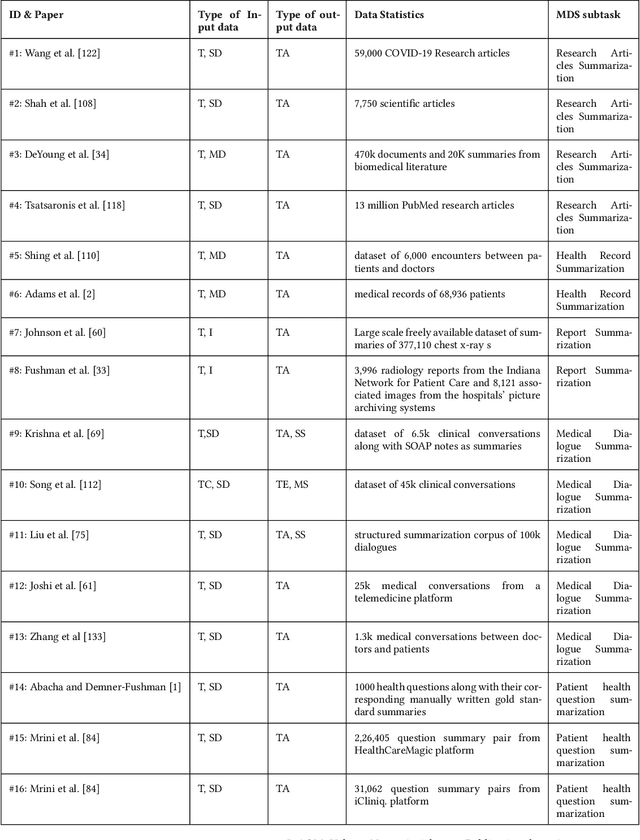
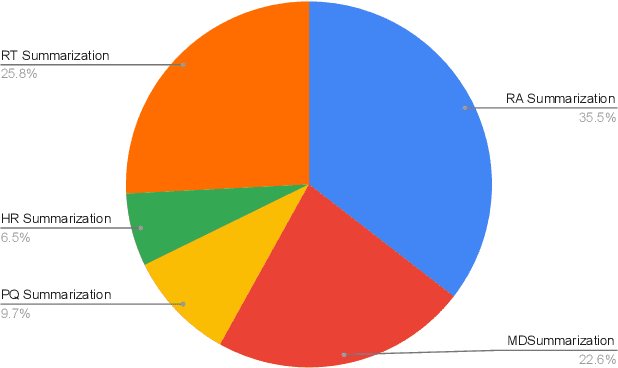

The internet has had a dramatic effect on the healthcare industry, allowing documents to be saved, shared, and managed digitally. This has made it easier to locate and share important data, improving patient care and providing more opportunities for medical studies. As there is so much data accessible to doctors and patients alike, summarizing it has become increasingly necessary - this has been supported through the introduction of deep learning and transformer-based networks, which have boosted the sector significantly in recent years. This paper gives a comprehensive survey of the current techniques and trends in medical summarization
WIDAR -- Weighted Input Document Augmented ROUGE
Jan 23, 2022

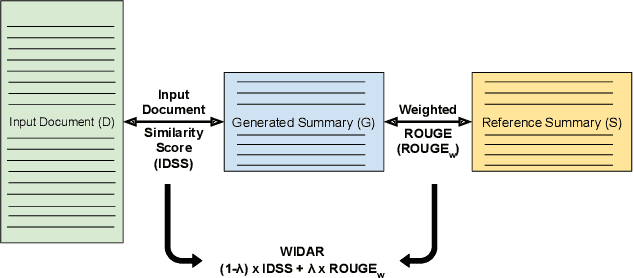
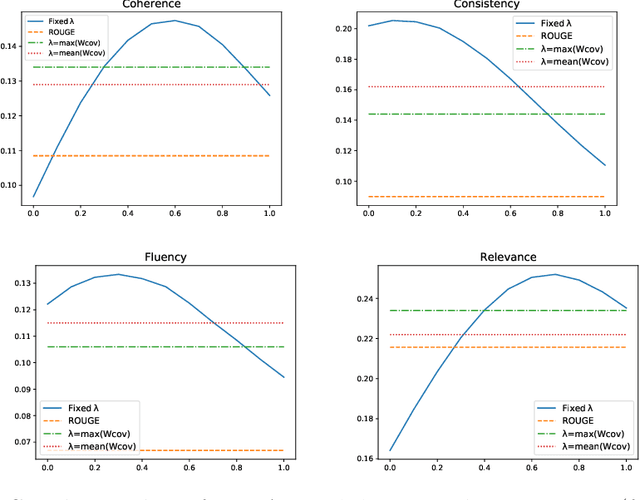
The task of automatic text summarization has gained a lot of traction due to the recent advancements in machine learning techniques. However, evaluating the quality of a generated summary remains to be an open problem. The literature has widely adopted Recall-Oriented Understudy for Gisting Evaluation (ROUGE) as the standard evaluation metric for summarization. However, ROUGE has some long-established limitations; a major one being its dependence on the availability of good quality reference summary. In this work, we propose the metric WIDAR which in addition to utilizing the reference summary uses also the input document in order to evaluate the quality of the generated summary. The proposed metric is versatile, since it is designed to adapt the evaluation score according to the quality of the reference summary. The proposed metric correlates better than ROUGE by 26%, 76%, 82%, and 15%, respectively, in coherence, consistency, fluency, and relevance on human judgement scores provided in the SummEval dataset. The proposed metric is able to obtain comparable results with other state-of-the-art metrics while requiring a relatively short computational time.