 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3Retrieve: Benchmarking Multimodal Retrieval for Medicine
Oct 08, 2025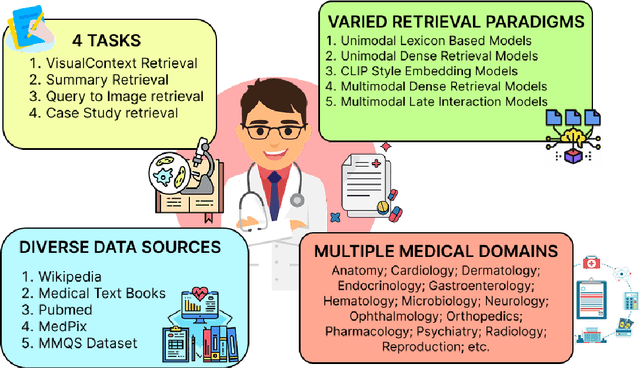
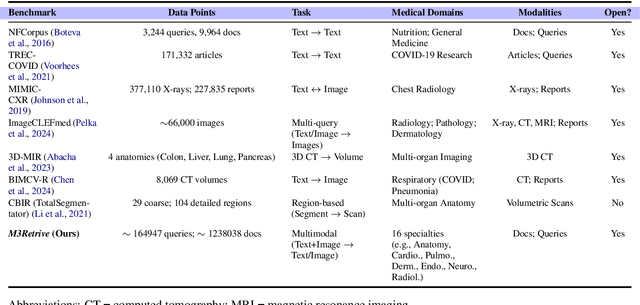

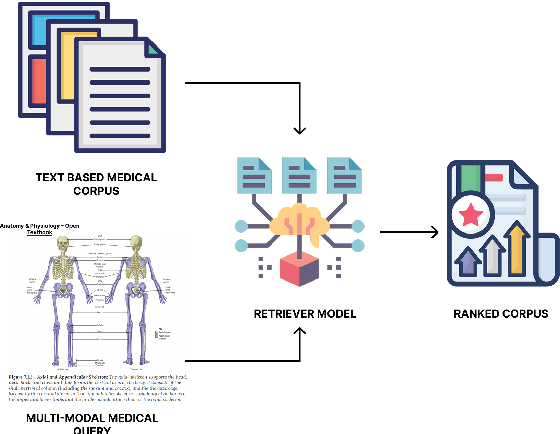
With the increasing use of RetrievalAugmented Generation (RAG), strong retrieval models have become more important than ever. In healthcare, multimodal retrieval models that combine information from both text and images offer major advantages for many downstream tasks such as question answering, cross-modal retrieval, and multimodal summarization, since medical data often includes both formats. However, there is currently no standard benchmark to evaluate how well these models perform in medical settings. To address this gap, we introduce M3Retrieve, a Multimodal Medical Retrieval Benchmark. M3Retrieve, spans 5 domains,16 medical fields, and 4 distinct tasks, with over 1.2 Million text documents and 164K multimodal queries, all collected under approved licenses. We evaluate leading multimodal retrieval models on this benchmark to explore the challenges specific to different medical specialities and to understand their impact on retrieval performance. By releasing M3Retrieve, we aim to enable systematic evaluation, foster model innovation, and accelerate research toward building more capable and reliable multimodal retrieval systems for medical applications. The dataset and the baselines code are available in this github page https://github.com/AkashGhosh/M3Retrieve.
NLLB-E5: A Scalable Multilingual Retrieval Model
Sep 09, 2024



Despite significant progress in multilingual information retrieval, the lack of models capable of effectively supporting multiple languages, particularly low-resource like Indic languages, remains a critical challenge. This paper presents NLLB-E5: A Scalable Multilingual Retrieval Model. NLLB-E5 leverages the in-built multilingual capabilities in the NLLB encoder for translation tasks. It proposes a distillation approach from multilingual retriever E5 to provide a zero-shot retrieval approach handling multiple languages, including all major Indic languages, without requiring multilingual training data. We evaluate the model on a comprehensive suite of existing benchmarks, including Hindi-BEIR, highlighting its robust performance across diverse languages and tasks. Our findings uncover task and domain-specific challenges, providing valuable insights into the retrieval performance, especially for low-resource languages. NLLB-E5 addresses the urgent need for an inclusive, scalable, and language-agnostic text retrieval model, advancing the field of multilingual information access and promoting digital inclusivity for millions of users globally.
Hindi-BEIR : A Large Scale Retrieval Benchmark in Hindi
Aug 18, 2024Given the large number of Hindi speakers worldwide, there is a pressing need for robust and efficient information retrieval systems for Hindi. Despite ongoing research, there is a lack of comprehensive benchmark for evaluating retrieval models in Hindi. To address this gap, we introduce the Hindi version of the BEIR benchmark, which includes a subset of English BEIR datasets translated to Hindi, existing Hindi retrieval datasets, and synthetically created datasets for retrieval. The benchmark is comprised of $15$ datasets spanning across $8$ distinct tasks. We evaluate state-of-the-art multilingual retrieval models on this benchmark to identify task and domain-specific challenges and their impact on retrieval performance. By releasing this benchmark and a set of relevant baselines, we enable researchers to understand the limitations and capabilities of current Hindi retrieval models, promoting advancements in this critical area. The datasets from Hindi-BEIR are publicly available.
MedSumm: A Multimodal Approach to Summarizing Code-Mixed Hindi-English Clinical Queries
Jan 03, 2024In the healthcare domain, summarizing medical questions posed by patients is critical for improving doctor-patient interactions and medical decision-making. Although medical data has grown in complexity and quantity, the current body of research in this domain has primarily concentrated on text-based methods, overlooking the integration of visual cues. Also prior works in the area of medical question summarisation have been limited to the English language. This work introduces the task of multimodal medical question summarization for codemixed input in a low-resource setting. To address this gap, we introduce the Multimodal Medical Codemixed Question Summarization MMCQS dataset, which combines Hindi-English codemixed medical queries with visual aids. This integration enriches the representation of a patient's medical condition, providing a more comprehensive perspective. We also propose a framework named MedSumm that leverages the power of LLMs and VLMs for this task. By utilizing our MMCQS dataset, we demonstrate the value of integrating visual information from images to improve the creation of medically detailed summaries. This multimodal strategy not only improves healthcare decision-making but also promotes a deeper comprehension of patient queries, paving the way for future exploration in personalized and responsive medical care. Our dataset, code, and pre-trained models will be made publicly available.
CLIPSyntel: CLIP and LLM Synergy for Multimodal Question Summarization in Healthcare
Dec 16, 2023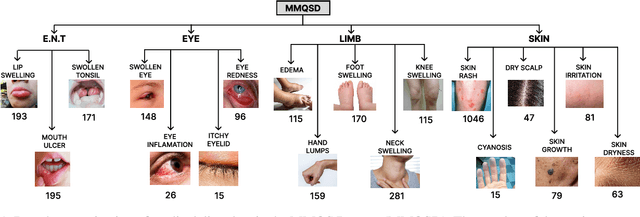
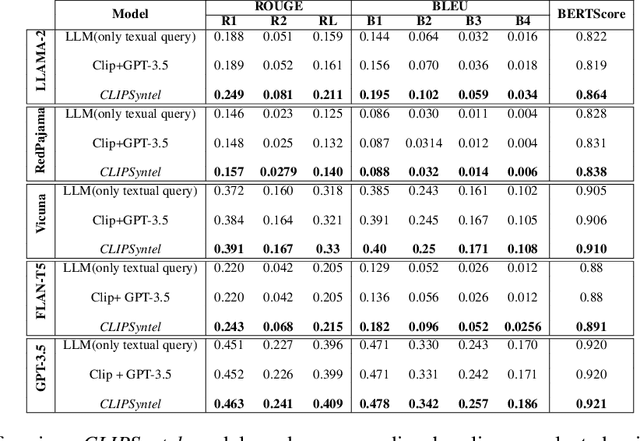

In the era of modern healthcare, swiftly generating medical question summaries is crucial for informed and timely patient care. Despite the increasing complexity and volume of medical data, existing studies have focused solely on text-based summarization, neglecting the integration of visual information. Recognizing the untapped potential of combining textual queries with visual representations of medical conditions, we introduce the Multimodal Medical Question Summarization (MMQS) Dataset. This dataset, a major contribution to our work, pairs medical queries with visual aids, facilitating a richer and more nuanced understanding of patient needs. We also propose a framework, utilizing the power of Contrastive Language Image Pretraining(CLIP) and Large Language Models(LLMs), consisting of four modules that identify medical disorders, generate relevant context, filter medical concepts, and craft visually aware summaries. Our comprehensive framework harnesses the power of CLIP, a multimodal foundation model, and various general-purpose LLMs, comprising four main modules: the medical disorder identification module, the relevant context generation module, the context filtration module for distilling relevant medical concepts and knowledge, and finally, a general-purpose LLM to generate visually aware medical question summaries. Leveraging our MMQS dataset, we showcase how visual cues from images enhance the generation of medically nuanced summaries. This multimodal approach not only enhances the decision-making process in healthcare but also fosters a more nuanced understanding of patient queries, laying the groundwork for future research in personalized and responsive medical care