 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereotype Detection as a Catalyst for Enhanced Bias Detection: A Multi-Task Learning Approach
Jul 02, 2025Bias and stereotypes in language models can cause harm, especially in sensitive areas like content moderation and decision-making. This paper addresses bias and stereotype detection by exploring how jointly learning these tasks enhances model performance. We introduce StereoBias, a unique dataset labeled for bias and stereotype detection across five categories: religion, gender, socio-economic status, race, profession, and others, enabling a deeper study of their relationship. Our experiments compare encoder-only models and fine-tuned decoder-only models using QLoRA. While encoder-only models perform well, decoder-only models also show competitive results. Crucially, joint training on bias and stereotype detection significantly improves bias detection compared to training them separately. Additional experiments with sentiment analysis confirm that the improvements stem from the connection between bias and stereotypes, not multi-task learning alone. These findings highlight the value of leveraging stereotype information to build fairer and more effective AI systems.
Mathematics Isn't Culture-Free: Probing Cultural Gaps via Entity and Scenario Perturbations
Jul 01, 2025



Although mathematics is often considered culturally neutral, the way mathematical problems are presented can carry implicit cultural context. Existing benchmarks like GSM8K are predominantly rooted in Western norms, including names, currencies, and everyday scenarios. In this work, we create culturally adapted variants of the GSM8K test set for five regions Africa, India, China, Korea, and Japan using prompt-based transformations followed by manual verification. We evaluate six large language models (LLMs), ranging from 8B to 72B parameters, across five prompting strategies to assess their robustness to cultural variation in math problem presentation. Our findings reveal a consistent performance gap: models perform best on the original US-centric dataset and comparatively worse on culturally adapted versions. However, models with reasoning capabilities are more resilient to these shifts, suggesting that deeper reasoning helps bridge cultural presentation gaps in mathematical tasks
Training with Pseudo-Code for Instruction Following
May 23, 2025Despite the rapid progress in the capabilities of Large Language Models (LLMs), they continue to have difficulty following relatively simple, unambiguous instructions, especially when compositions are involved. In this paper, we take inspiration from recent work that suggests that models may follow instructions better when they are expressed in pseudo-code. However, writing pseudo-code programs can be tedious and using few-shot demonstrations to craft code representations for use in inference can be unnatural for non-expert users of LLMs. To overcome these limitations, we propose fine-tuning LLMs with instruction-tuning data that additionally includes instructions re-expressed in pseudo-code along with the final response. We evaluate models trained using our method on $11$ publicly available benchmarks comprising of tasks related to instruction-following, mathematics, and common-sense reasoning. We conduct rigorous experiments with $5$ different models and find that not only do models follow instructions better when trained with pseudo-code, they also retain their capabilities on the other tasks related to mathematical and common sense reasoning. Specifically, we observe a relative gain of $3$--$19$% on instruction-following benchmark, and an average gain of upto 14% across all tasks.
Granite Embedding Models
Feb 27, 2025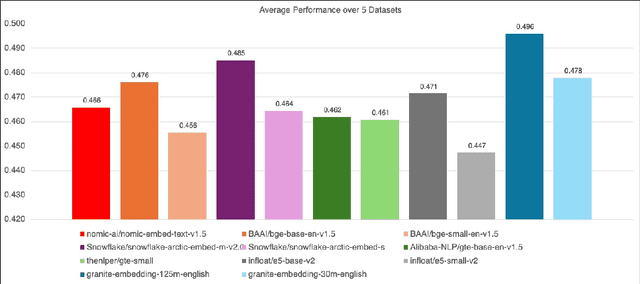



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
MILU: A Multi-task Indic Language Understanding Benchmark
Nov 04, 2024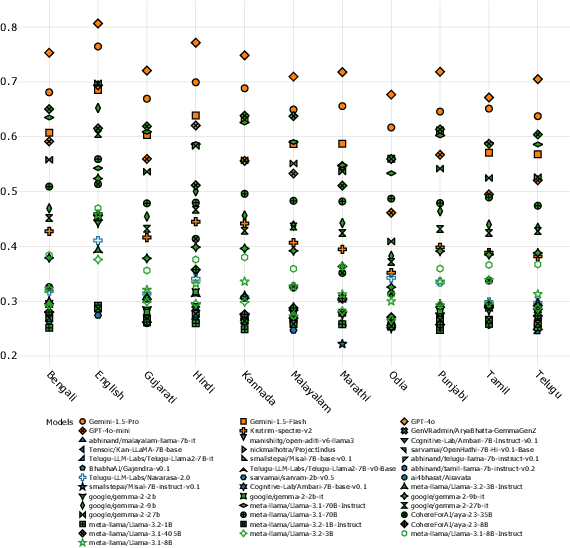

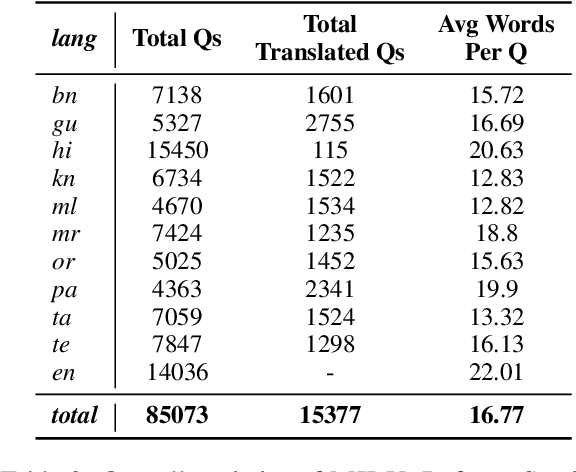
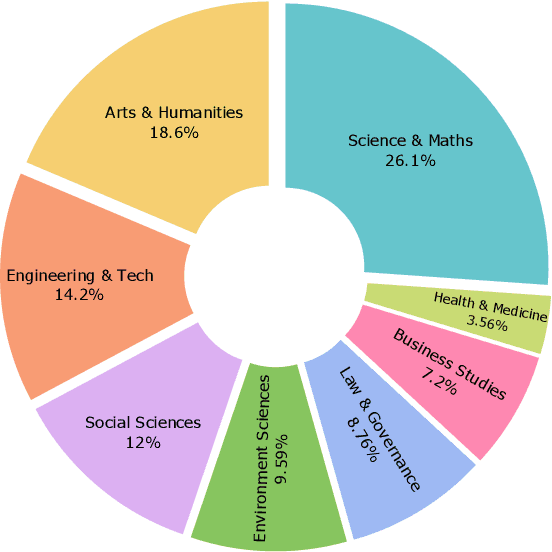
Evaluating Large Language Models (LLMs) in low-resource and linguistically diverse languages remains a significant challenge in NLP, particularly for languages using non-Latin scripts like those spoken in India. Existing benchmarks predominantly focus on English, leaving substantial gaps in assessing LLM capabilities in these languages. We introduce MILU, a Multi task Indic Language Understanding Benchmark, a comprehensive evaluation benchmark designed to address this gap. MILU spans 8 domains and 42 subjects across 11 Indic languages, reflecting both general and culturally specific knowledge. With an India-centric design, incorporates material from regional and state-level examinations, covering topics such as local history, arts, festivals, and laws, alongside standard subjects like science and mathematics. We evaluate over 42 LLMs, and find that current LLMs struggle with MILU, with GPT-4o achieving the highest average accuracy at 72 percent. Open multilingual models outperform language-specific fine-tuned models, which perform only slightly better than random baselines. Models also perform better in high resource languages as compared to low resource ones. Domain-wise analysis indicates that models perform poorly in culturally relevant areas like Arts and Humanities, Law and Governance compared to general fields like STEM. To the best of our knowledge, MILU is the first of its kind benchmark focused on Indic languages, serving as a crucial step towards comprehensive cultural evaluation. All code, benchmarks, and artifacts will be made publicly available to foster open research.
Evaluating the Instruction-following Abilities of Language Models using Knowledge Tasks
Oct 16, 2024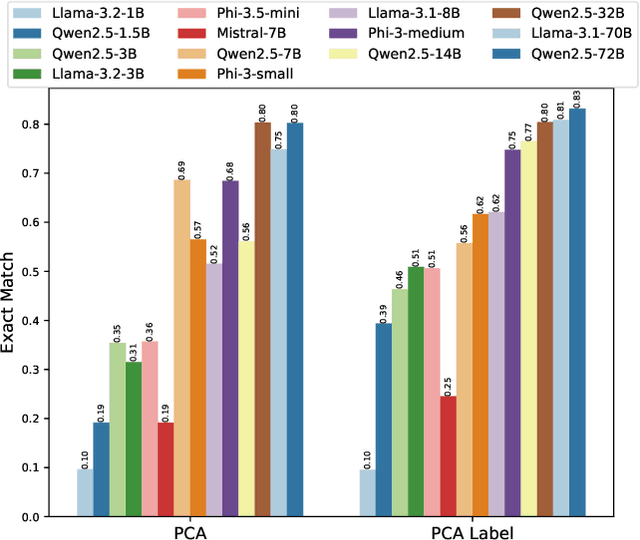



In this work, we focus our attention on developing a benchmark for instruction-following where it is easy to verify both task performance as well as instruction-following capabilities. We adapt existing knowledge benchmarks and augment them with instructions that are a) conditional on correctly answering the knowledge task or b) use the space of candidate options in multiple-choice knowledge-answering tasks. This allows us to study model characteristics, such as their change in performance on the knowledge tasks in the presence of answer-modifying instructions and distractor instructions. In contrast to existing benchmarks for instruction following, we not only measure instruction-following capabilities but also use LLM-free methods to study task performance. We study a series of openly available large language models of varying parameter sizes (1B-405B) and closed source models namely GPT-4o-mini, GPT-4o. We find that even large-scale instruction-tuned LLMs fail to follow simple instructions in zero-shot settings. We release our dataset, the benchmark, code, and results for future work.
NLLB-E5: A Scalable Multilingual Retrieval Model
Sep 09, 2024



Despite significant progress in multilingual information retrieval, the lack of models capable of effectively supporting multiple languages, particularly low-resource like Indic languages, remains a critical challenge. This paper presents NLLB-E5: A Scalable Multilingual Retrieval Model. NLLB-E5 leverages the in-built multilingual capabilities in the NLLB encoder for translation tasks. It proposes a distillation approach from multilingual retriever E5 to provide a zero-shot retrieval approach handling multiple languages, including all major Indic languages, without requiring multilingual training data. We evaluate the model on a comprehensive suite of existing benchmarks, including Hindi-BEIR, highlighting its robust performance across diverse languages and tasks. Our findings uncover task and domain-specific challenges, providing valuable insights into the retrieval performance, especially for low-resource languages. NLLB-E5 addresses the urgent need for an inclusive, scalable, and language-agnostic text retrieval model, advancing the field of multilingual information access and promoting digital inclusivity for millions of users globally.
Mistral-SPLADE: LLMs for better Learned Sparse Retrieval
Aug 22, 2024Learned Sparse Retrievers (LSR) have evolved into an effective retrieval strategy that can bridge the gap between traditional keyword-based sparse retrievers and embedding-based dense retrievers. At its core, learned sparse retrievers try to learn the most important semantic keyword expansions from a query and/or document which can facilitate better retrieval with overlapping keyword expansions. LSR like SPLADE has typically been using encoder only models with MLM (masked language modeling) style objective in conjunction with known ways of retrieval performance improvement such as hard negative mining, distillation, etc. In this work, we propose to use decoder-only model for learning semantic keyword expansion. We posit, decoder only models that have seen much higher magnitudes of data are better equipped to learn keyword expansions needed for improved retrieval. We use Mistral as the backbone to develop our Learned Sparse Retriever similar to SPLADE and train it on a subset of sentence-transformer data which is often used for training text embedding models. Our experiments support the hypothesis that a sparse retrieval model based on decoder only large language model (LLM) surpasses the performance of existing LSR systems, including SPLADE and all its variants. The LLM based model (Echo-Mistral-SPLADE) now stands as a state-of-the-art learned sparse retrieval model on the BEIR text retrieval benchmark.
Hindi-BEIR : A Large Scale Retrieval Benchmark in Hindi
Aug 18, 2024Given the large number of Hindi speakers worldwide, there is a pressing need for robust and efficient information retrieval systems for Hindi. Despite ongoing research, there is a lack of comprehensive benchmark for evaluating retrieval models in Hindi. To address this gap, we introduce the Hindi version of the BEIR benchmark, which includes a subset of English BEIR datasets translated to Hindi, existing Hindi retrieval datasets, and synthetically created datasets for retrieval. The benchmark is comprised of $15$ datasets spanning across $8$ distinct tasks. We evaluate state-of-the-art multilingual retrieval models on this benchmark to identify task and domain-specific challenges and their impact on retrieval performance. By releasing this benchmark and a set of relevant baselines, we enable researchers to understand the limitations and capabilities of current Hindi retrieval models, promoting advancements in this critical area. The datasets from Hindi-BEIR are publicly available.
INDIC QA BENCHMARK: A Multilingual Benchmark to Evaluate Question Answering capability of LLMs for Indic Languages
Jul 18, 2024



Large Language Models (LLMs) have demonstrated remarkable zero-shot and few-shot capabilities in unseen tasks, including context-grounded question answering (QA) in English. However, the evaluation of LLMs' capabilities in non-English languages for context-based QA is limited by the scarcity of benchmarks in non-English languages. To address this gap, we introduce Indic-QA, the largest publicly available context-grounded question-answering dataset for 11 major Indian languages from two language families. The dataset comprises both extractive and abstractive question-answering tasks and includes existing datasets as well as English QA datasets translated into Indian languages. Additionally, we generate a synthetic dataset using the Gemini model to create question-answer pairs given a passage, which is then manually verified for quality assurance. We evaluate various multilingual Large Language Models and their instruction-fine-tuned variants on the benchmark and observe that their performance is subpar, particularly for low-resource languages. We hope that the release of this dataset will stimulate further research on the question-answering abilities of LLMs for low-resource languages.